들어가기
자료의 분포를 설명하는 통계량에 자료의 중심을 설명하는 대표치와 자료의 퍼짐을 설명하는 산포도(분산)가 있다. 대표치로는 평균, 중위수, 최빈수 등이 있고, 퍼진 정도를 표현하는 분산, 분산의 제곱근인 표준편차 등이 있다. 또한 자료가 어느쪽으로 편중되었는지의 기울기를 나타내는 왜도, 대표치 부근에 자료가 밀집한 정도를 나타내는 첨도 등이 있다.
이번에는 왜도를 중심으로 이야기를 해 본다. 자료의 대칭성을 설명하는 왜도가 0이면 분포가 좌우 대칭을 이루고 음수이면 왼쪽으로 치우친 분포를, 양수이면 오른쪽으로 치우친 분포를 이룬다. 첨도는 3이면 정규분포 곡선과 유사하며, 3보다 크면 정규분포 곡선보다 정점이 높고 뾰족한 분포며 3보다 작으면 정규분포보다 정점이 낮고 퍼진 모양의 분포다.
왜도가 1이면 중위수, 평균(산술평균), 최빈수가 같은 값을 가지며 자료가 왼쪽으로 치우친 분포라면 왜도는 음수이며 최빈수 < 중위수 < 평균의 관계가 자료가 오른쪽으로 치우친 분포라면 왜도는 양수이며 평균 < 중위수 < 최빈수의 관계가 성립함을 배운적이 있다. 그러면 이를 보여줄 데이터를 만들고 그림으로 그려보면서 왜도의 값에 따른 평균, 중위수, 최빈수의 관계를 이해해 보자.
최빈수, 왜도, 첨도를 구하는 함수
다음처럼 최빈수, 왜도, 첨도를 구하는 함수를 만들어 보았다. 물론 이들 통계량을 구하는 패키지가 있지만, 그 내용을 이해하는 차원에서 구현해 보았다.
데이터 만들기
#####################################
# 왜도가 0에 근사한 데이터를 생성
#####################################
set.seed(2)
# 정규난수 1000개 생성
prob <- dnorm(1:21, mean=11, sd=3)
x <- sample(1:21, 1500, replace = TRUE, prob=prob)
x.mean <- mean(x) # 평균
x.median <- median(x) # 중위수
x.mode <- get.mode(x) # 최빈수
x.mean
[1] 11.06333sd(x) # 표준편차
[1] 3.080311x.median
[1] 11x.mode
[1] 11summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 9.00 11.00 11.06 13.00 21.00 get.skewness(x)
[1] 0.01977239get.kurtosis(x)
[1] -0.09515365#####################################
# 왜도가 음수인 데이터를 생성
#####################################
set.seed(3)
y <- numeric(1500)
for(i in 1:15) {
idx <- (i-1)*100+1
y[idx:(idx+99)] <- sample(i:20, 100, replace = TRUE)
}
y.mean <- mean(y)
y.median <- median(y)
y.mode <- get.mode(y)
y.mean
[1] 13.94733sd(y)
[1] 4.537505y.median
[1] 15y.mode
[1] 16 20summary(y)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 11.00 15.00 13.95 18.00 20.00 get.skewness(y)
[1] -0.6336066get.kurtosis(y)
[1] -0.4125684#####################################
# 왜도가 양수인 데이터를 생성
#####################################
set.seed(5)
z <- numeric(1500)
for(i in 6:20) {
idx <- (i-6)*100+1
z[idx:(idx+99)] <- sample(1:i, 100, replace = TRUE)
}
z.mean <- mean(z)
z.median <- median(z)
z.mode <- get.mode(z)
z.mean
[1] 6.989333sd(z)
[1] 4.419605z.median
[1] 6z.mode
[1] 5summary(z)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 3.000 6.000 6.989 10.000 20.000 get.skewness(z)
[1] 0.6470598get.kurtosis(z)
[1] -0.2881661분포의 시각화
세 분포를 시각화하면 다음과 같은 그래프를 얻을 수 있다. 왼쪽의 그림들이 분포의 그림이고, 오른쪽은 정규분포에 근사하는지를 검증하기 위한 Q-Q plot이다.
첫번째 그림은 정규분포에 근사하고, 두번째 그림은 오른쪽으로 치우친 분포(skewed to the left)고, 세번째 그림은 왼쪽으로 치우친 분포(skewed to the right)의 그래프임을 알 수 있다.
par(mfrow = c(3, 2))
plot(density(x), main = "Like Normal")
abline(v = x.mean, col = "red", lty = 1)
abline(v = x.median, col = "blue", lty = 2)
abline(v = x.mode, col = "black", lty = 3)
qqnorm(x)
qqline(x)
plot(density(y), main = "Skewed Right")
abline(v = y.mean, col = "red", lty = 1)
abline(v = y.median, col = "blue", lty = 2)
abline(v = y.mode, col = "black", lty = 3)
legend("topleft", legend = c("mean", "median", "mode"),
col=c("red", "blue", "black"), lty = 1:3)
qqnorm(y)
qqline(y)
plot(density(z), main = "Skewed Left")
abline(v = z.mean, col = "red", lty = 1)
abline(v = z.median, col = "blue", lty = 2)
abline(v = z.mode, col = "black", lty = 3)
legend("topright", legend = c("mean", "median", "mode"),
col=c("red", "blue", "black"), lty = 1:3)
qqnorm(z)
qqline(z)
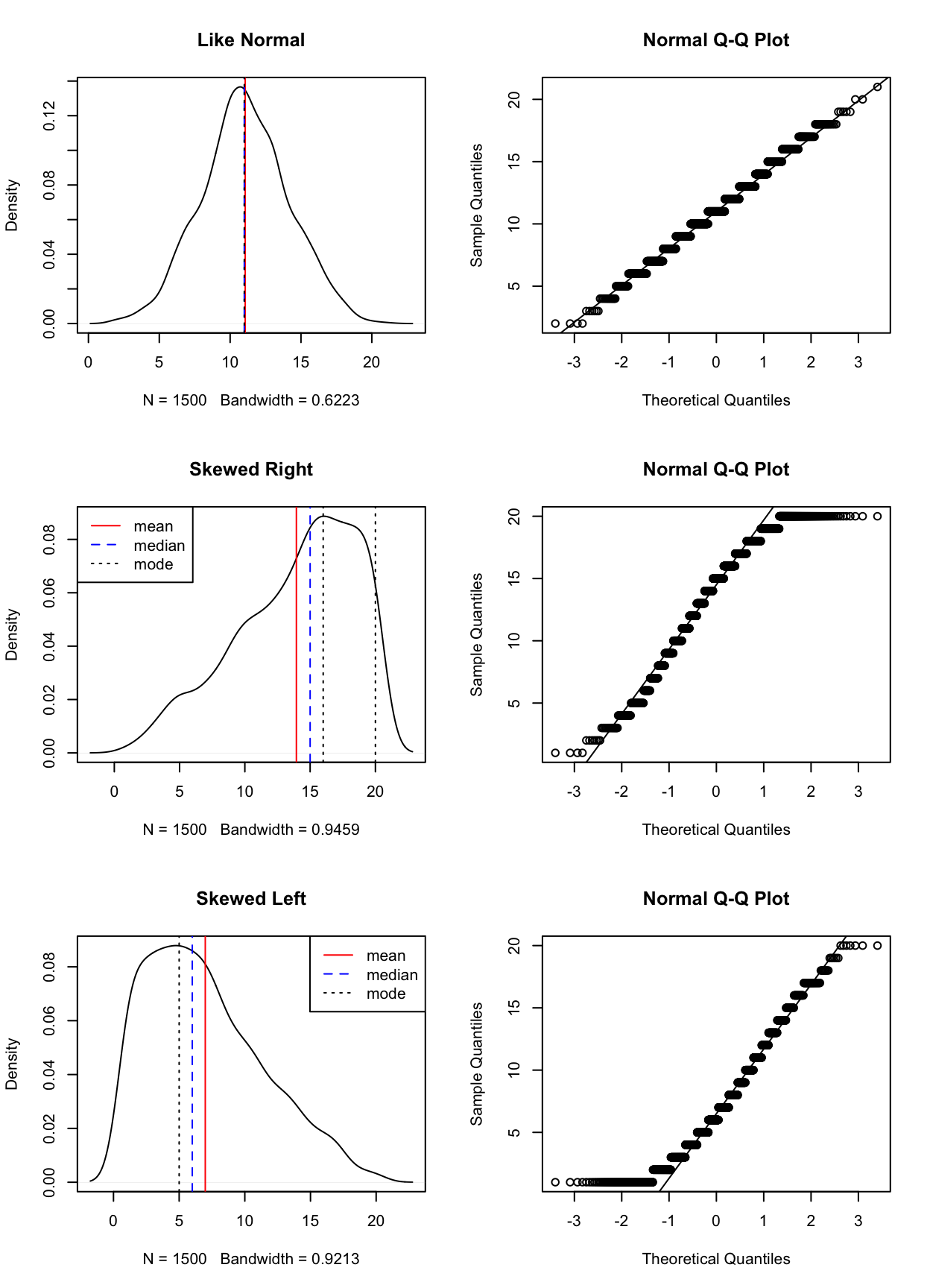
Figure 1: distribution plot