들어가기
R에서 데이터를
scraping하는 기술은 데이터 조작 함수를 구사하는 능력에 비례한다. 그 이유는 원하는 부분의 데이터만 취하기 위해서는 데이터 조작이 필수적이기 때문이다. 물론 원천 데이터가 웹 채널에 있기 때문에 HTML 문법과 이를 긁어올 수 있는rvest 패키지등의 사용법도 중요하다.Text Analytics는NLP(Natural language processing)를 위한 전문적인 도구와 기술이 필요하다. 그러나 다행이도 일반적인 데이터 분석 기법을 적용할 수도 있고, 최근에는 Deep Learning 기법이 응용되는 분야이기도 하다. 일반적인 데이터 분석 기법을 적용하여 Text Analytics을 이해해 보자.
Crawling
대통령기록연구실 홈페이지에서 특정 대통령의 재임 기간의 연설문을 수집한다.
Preprocessing
텍스트 분석을 위해서 수집한 텍스트 데이터를 전처리한다. 몇 가지의 형태소 분석기를 분석해 본다.
Text Analytics
Document Term Matrix를 생성한 다음, 여러 기법의 텍스트 데이터 분석을 수행한다.
데이터 조작에 대한 슬라이드의 공유
다음에 링크를 걸어 둔 슬라이드 파일은 2017년도에 모 미트업에서 발표한 슬라이드 pdf 파일이다. 그 이후에 많은 시간이 흘렀기 때문에 일부 개선된 것들이 있을 수 있다. 감안해서 참고하기 바란다.
슬라이드 발췌 이미지를 예시해 본다.
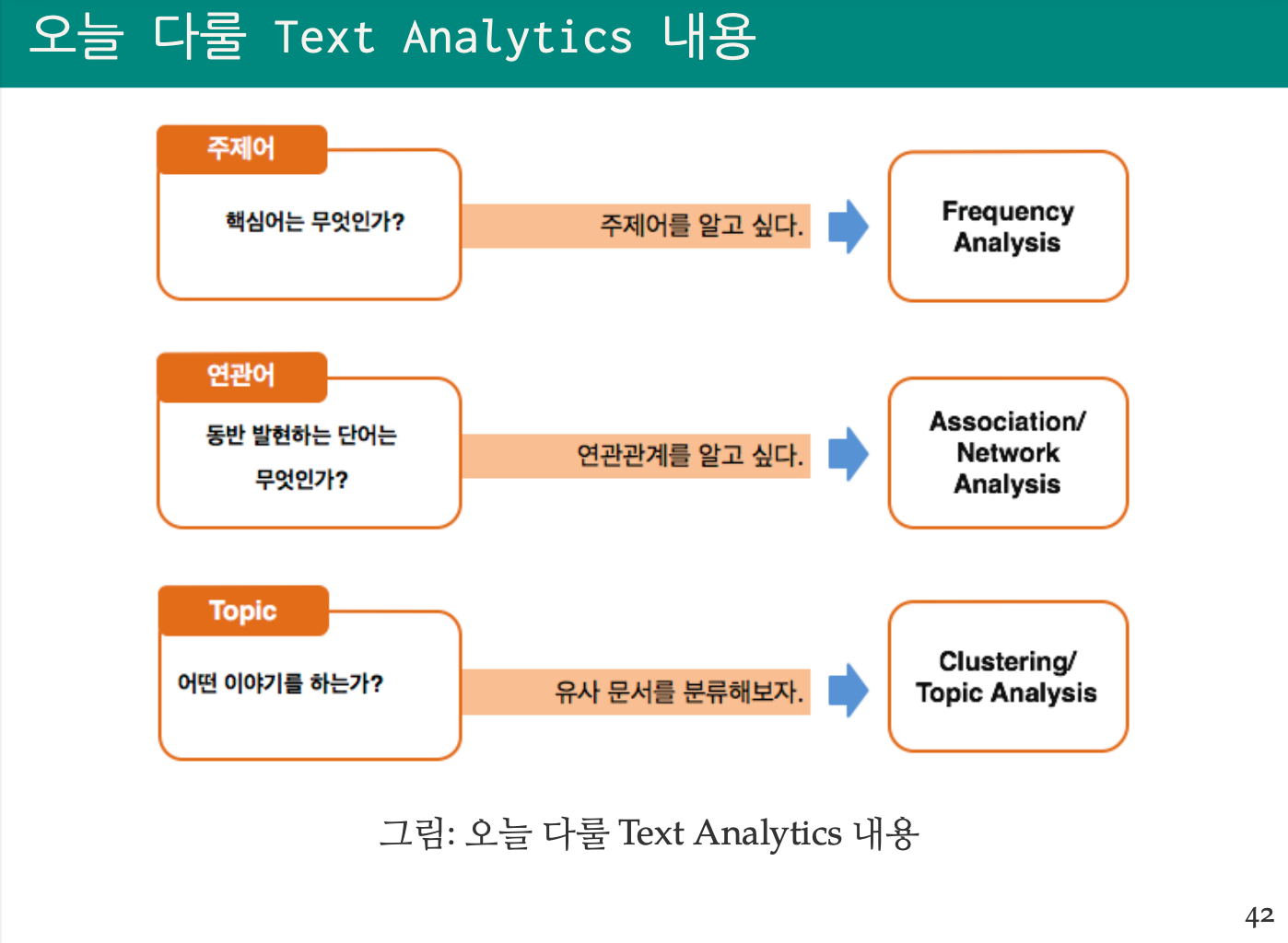
Figure 1: 슬라이드 발췌 이미지
차례
이 문서는 다음과 같은 아젠다를 이야기 한다.
- Learning Outline
- Scraping Data
- 수집 데이터 전처리
- Text Analytics 개요
- Frequency Analysis
- Association Rules
- Clustering/Topic Analytics