다룰 이야기
R에서 데이터를 조작할 때, 가장 까다로운 것이 범주형 데이터를 표현하는 factor다. 이번 이야기에서는 시각화를 위해서 factor를 다루는 방법과 몇몇 ggplot2 패키지를 사용할 때의 몇 가지 팁을 소개한다.
- 플롯에서 factor의 경우에는, 데이터의 표현이 levels 순서로 이루어진다. 그러나 표현 순서를 변경하고 싶다.
- 솔루션) factor의 levels을 표현하는 순서에 맞게 변경한다.
- factor의 모든 levels이 아닌 상위.하위 몇 개의 levels에 해당하는 것만 시각화하고 싶다.
- 솔루션) 필터링 기능의 함수를 사용하며 몇 개의 levels에 해당하는 데이터만 추출한다.
또한 다음처럼 ggplot에서 응용할 수 있는 몇 가지 팁도 제시한다.
- 플롯에서 x-축의 tick 마크에 출력할 라벨 이름이 길 경우에는 서로 겹쳐서 읽기 어려운 경우가 있다.
- 솔루션 1) 라벨을 회전시켜 겹치지 않게 출력한다.
- 솔루션 2) x-축과 y-축을 바꿔서 출력한다.
- x-축과 y-축을 바꿔서 출력하고 싶다.
- 솔루션) coord_flip() 함수를 적용하여 축을 바꾼다.
- y-축에 데이터를 배치하는 순서를 역순으로 변경하고 싶다.
- 솔루션 1) aes() 함수 안에서 forcats::fct_reorder() 함수를 이용한다. 혹은,
- 솔루션 2) aes() 함수 안에서 ggplot2::reorder() 함수를 이용한다.
데이터
ggplot2 패키지에 포함된 txhousing는 Texas A&M University(TAMU)의 The Real Estate Center에서 제공한 Texas의 주택 시장에 대한 정보를 담고 있다. 이 데이터로 이야기를 풀어나가려 한다.
- city
- Name of MLS area
- year,month,date
- Date
- sales
- Number of sales
- volume
- Total value of sales
- median
- Median sale price
- listings
- Total active listings
- inventory
- “Months inventory”:
- amount of time it would take to sell all current listings at current pace of sales.
- “Months inventory”:
tibble [8,602 × 9] (S3: tbl_df/tbl/data.frame)
$ city : chr [1:8602] "Abilene" "Abilene" "Abilene" "Abilene" ...
$ year : int [1:8602] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
$ month : int [1:8602] 1 2 3 4 5 6 7 8 9 10 ...
$ sales : num [1:8602] 72 98 130 98 141 156 152 131 104 101 ...
$ volume : num [1:8602] 5380000 6505000 9285000 9730000 10590000 ...
$ median : num [1:8602] 71400 58700 58100 68600 67300 66900 73500 75000 64500 59300 ...
$ listings : num [1:8602] 701 746 784 785 794 780 742 765 771 764 ...
$ inventory: num [1:8602] 6.3 6.6 6.8 6.9 6.8 6.6 6.2 6.4 6.5 6.6 ...
$ date : num [1:8602] 2000 2000 2000 2000 2000 ...시각화
조작하지 않은 플롯
도시별 일별 부동산 판매 건수의 분포를 박스플롯을 그려 살펴보자. 그런데 도시 개수가 적지 않아, x-축의 도시 이름이 겹쳐서 출력되었다. 어떤 도시의 부동산 판매 건수가 많은지 혹은 적은지 알 수 없다.
library(dplyr)
library(ggplot2)
txhousing %>%
filter(!is.na(sales)) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
theme(legend.position = "none")
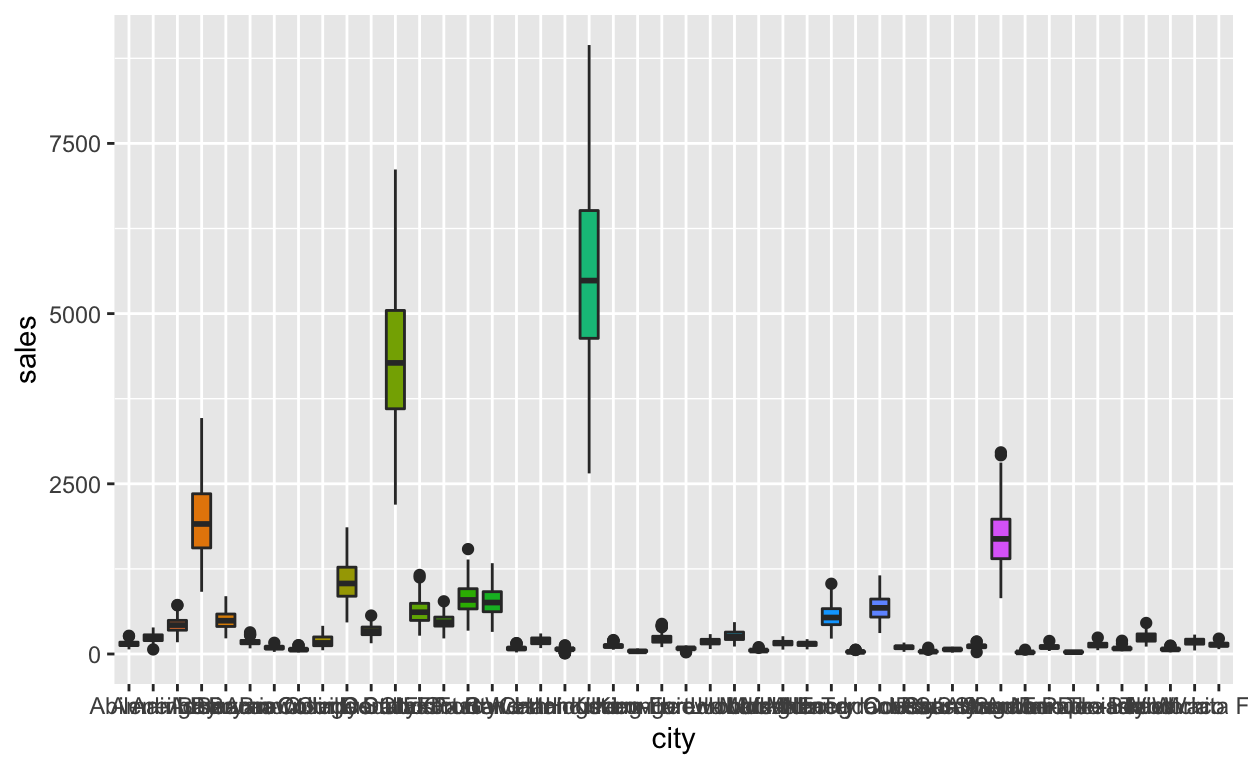
x-축의 tick 마크 라벨 회전
도시 이름이 겹쳐서 출력되었다. 어떤 도시의 부동산 판매 건수가 많은지 혹은 적은지 알 수 없다.
만약 x-축이 연속형 변수일 경우에는 라벨이 겹치지 않을 정도로 몇 개의 tick 마크만 출력하면 문제가 해결된다. 그러나 이 경우처럼 x-축이 범주형 변수일 경우에는 이 방법을 적용할 수 없다.
x-축의 tick 마크 라벨을 회전하면 겹쳐지는 것을 방지할 수 있다. 다음처럼 theme() 함수를 이용해서 axis.text.x의 출력 각도 90도로 조정한다.
txhousing %>%
filter(!is.na(sales)) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
theme(legend.position = "none") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1))
이제 도시 이름이 겹치지 않아서 Houstion에서의 부동산 거래가 활발함을 할 수 있다. 그러나 한가지 문제점이 있다. 도시 이름이 회전하다보니, 그 이름을 읽어서 인식하기가 다소 어려워 졌다. 또한 도시 이름이 긴 것이 많아 전체 시각화 결과에서 x-축의 영역이 필요 이상으로 커졌다.
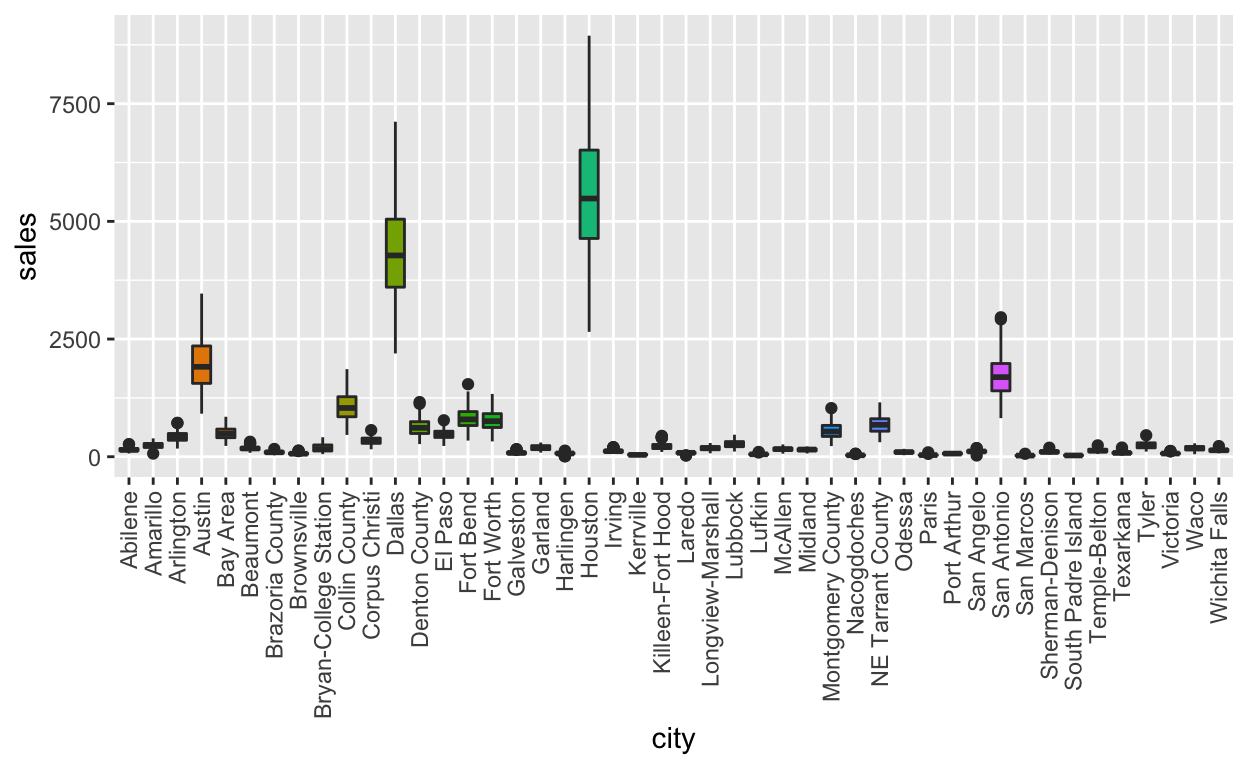
이번에는 각도를 45도로 조정해 보자.
txhousing %>%
filter(!is.na(sales)) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
theme(legend.position = "none") +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1))
출력된 플롯에서 x-축의 영역이 줄어들었고, 좀더 가로 모양에 가까워져서 이름을 읽어서 인식하기가 다소 쉬워 졌다. 그러나 도시간의 간격이 좀 줄어들어, 도시 이름간을 분리하는데 다소 간섭이 발생한다.
데이터 크기별로 정렬하여 출력
도시별 부동산 거래 규모를 파악하는 시나리오는“어느 도시가 거래량이 많은지, 혹은 어느 도시가 거래량이 적은지?”를 파악하는 것이다. 지극히 일반적인 시나리오다. 만약 관심있는 도시가 정해져 있고, 그 도시의 순서가 의미가 있다면 관심있는 도시 순서로 표현되길 원할 것이다.
앞에서 정의한 시나리오는 거래량이 많은 도시부터 시작해서 적은 도시의 순서(내림차순)로 표현하거나, 반대로 거래량이 적은 도시부터 시작해서 많은 도시의 순서(오름차순)로 표현하는 방법이다. 만약 수치 변수가 positive 지표일 경우에는 내림차순으로, negative일 경우에는 오름차숨으로 표현하는 것이 바람직하다. 거래량은 부정적인 지표가 아니므로 내림차순으로 표현하는 것이 바람직하다.
범주형 데이터인 factor나 ordered factor는 정의된 levels 순서로 데이터가 표현된다. 그러므로 levels을 거래량의 내림차순에 해당하는 도시 이름으로 변경해주면 도시별 박스 플롯이 내림차순으로 표현된다.
forcats 패키지의 fct_reorder() 함수는 지정한 수치변수의 정렬 순서에 따라 factor의 levels 순서를 변경한다. 그러므로 다음과 같이 mutate() 함수에 적용하여 거래량의 내림차순 순으로 도시 이름의 순서를 변경해 준다.
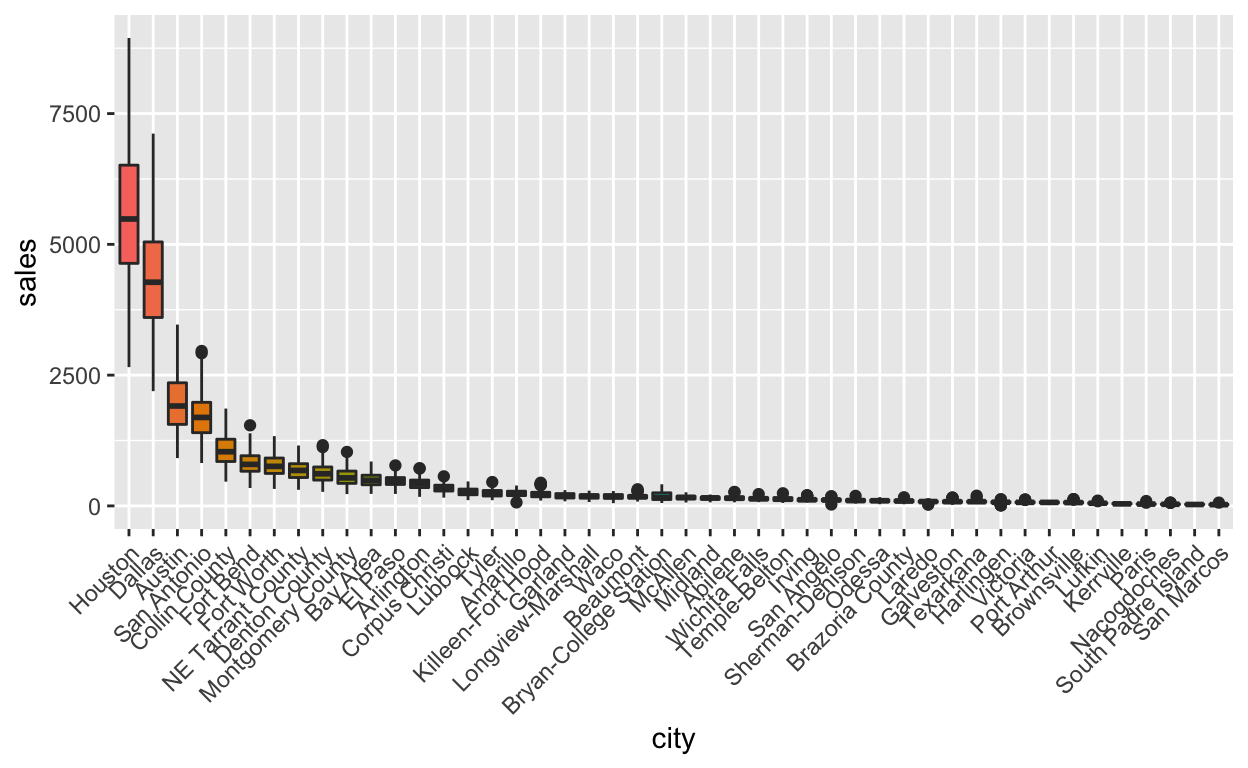
txhousing %>%
filter(!is.na(sales)) %>%
mutate(city = forcats::fct_reorder(city, sales, .desc = TRUE)) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
theme(legend.position = "none") +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust=1))
일부 범주의 정보만 출력하기
Top-n을 분석할 경우, 예를 들면 부동산 거래량 상위 10개 도시만 시각화는 경우, 부동산 거래량 하위 7개 도시만 시각화는 경우에는 전체 도시가 아닌 일부 도시를 필터링하여 출력해야 한다. 예제 데이터는 46개의 도시 정보를 포함하고 있다. 이 경우 46개의 도시에 대한 거래량을 이해하는 것보다 규모가 크거나 작은 몇 개의 도시에 대한 정보를 재빨리 파악하는 것이 중요하다.
filter() 함수는 조건을 만족하는 사례만 취하는 함수다. 다음처럼 조건에 상위, 혹은 하위 Top-n 개의 도시를 추려서 시각화하면 원하는 결과를 얻을 수 있다.
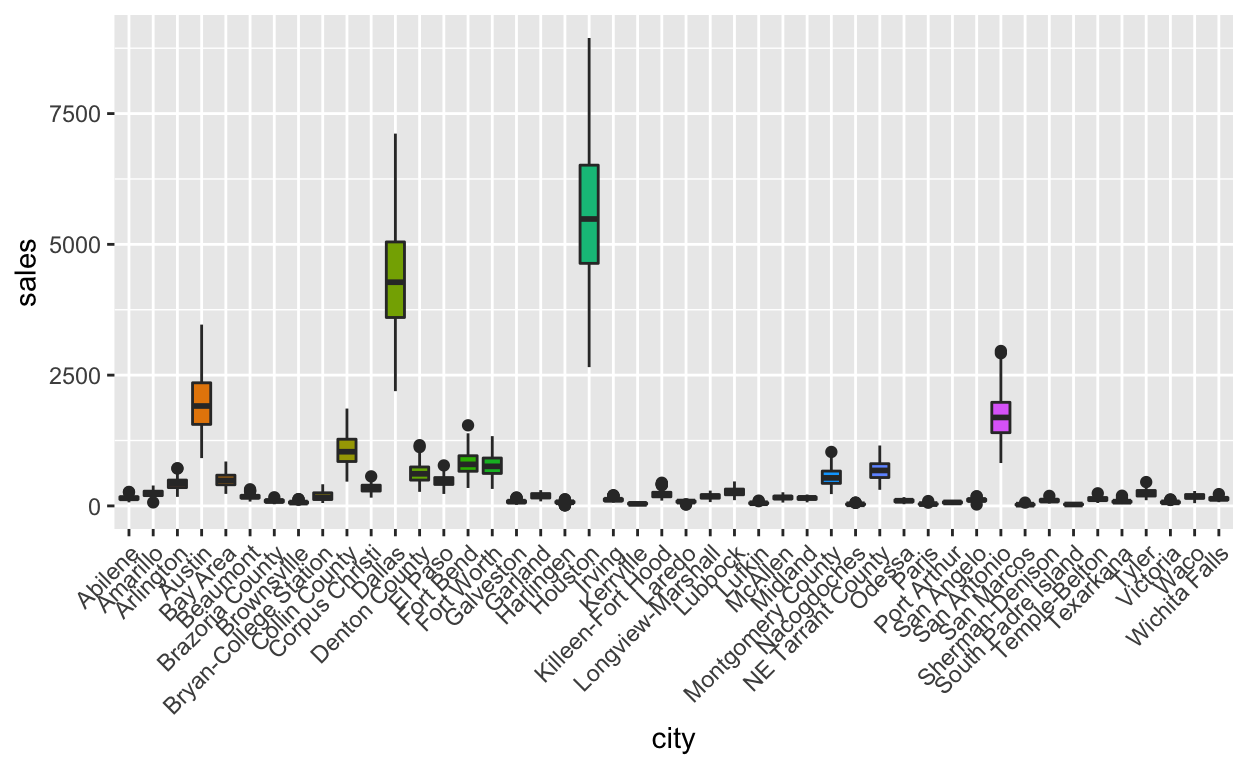
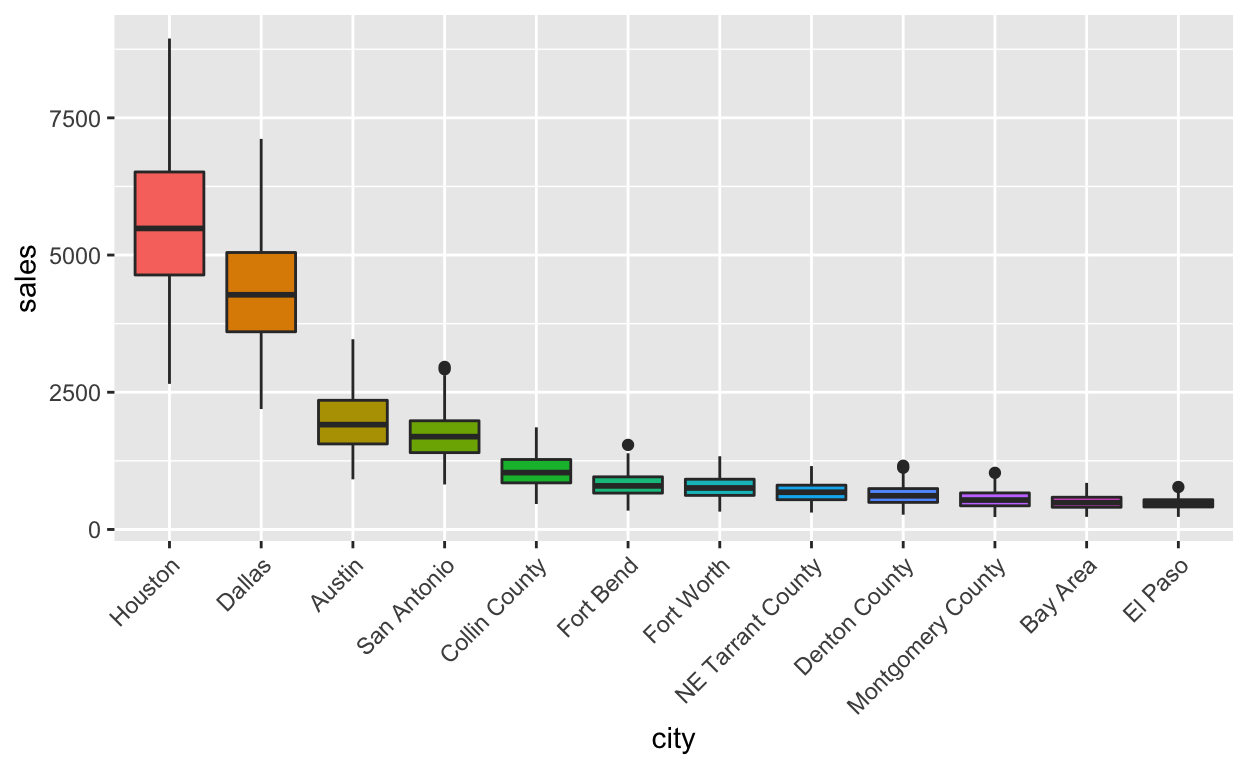
n <- 12
txhousing %>%
filter(!is.na(sales)) %>%
mutate(city = forcats::fct_reorder(city, sales, .desc = TRUE)) %>%
filter(city %in% levels(city)[1:n]) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
theme(legend.position = "none") +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust=1))
축을 바꿔서 출력하기
일반화된 법칙은 아니지만 경우에 따라서, x-축과 y-축을 바꿔서 출력하면 몇 가지 잇점을 얻을 수 있다.
x-축에 표현할 범주형 변수의 levels 개수가 많아서 겹쳐 출력할 경우에 겹치는 문제를 해결할 수 있다. 그리고 박스 플롯처럼 분포를 파악하는 시각화의 경우에는 위 아래로 시선을 훑으면서 해석하는 것보다는 왼쪽에서 오른쪽으로 시선을 훑는 것이 정보를 이해하는데 수월하다. 유사한 기능을 수행하는 히스토그램이나 밀도 그래프(density plot)는 횡으로 나열하여 표현한 것도 이런 이유다. 그러나 절대적이지는 않다. 세로로 표현해도 해석하는 데 문제는 없다. 다만, 세심한 배려가 시각화 결과를 해석하는 분석가나 정보를 재공받는 플롯 해석가에게 해석에 존더 집중할 수 있는 환경을 만들어 줄 수 있다는 점을 고려해야 한다.
ggplot의 경우에는 coord_flip() 함수를 적용해서 x-축과 y-축을 바꿔서 출력할 수 있다.
n <- 12
txhousing %>%
filter(!is.na(sales)) %>%
mutate(city = forcats::fct_reorder(city, sales, .desc = TRUE)) %>%
filter(city %in% levels(city)[1:n]) %>%
ggplot(aes(x = city, y = sales, fill = city)) +
geom_boxplot() +
coord_flip() +
theme(legend.position = "none")
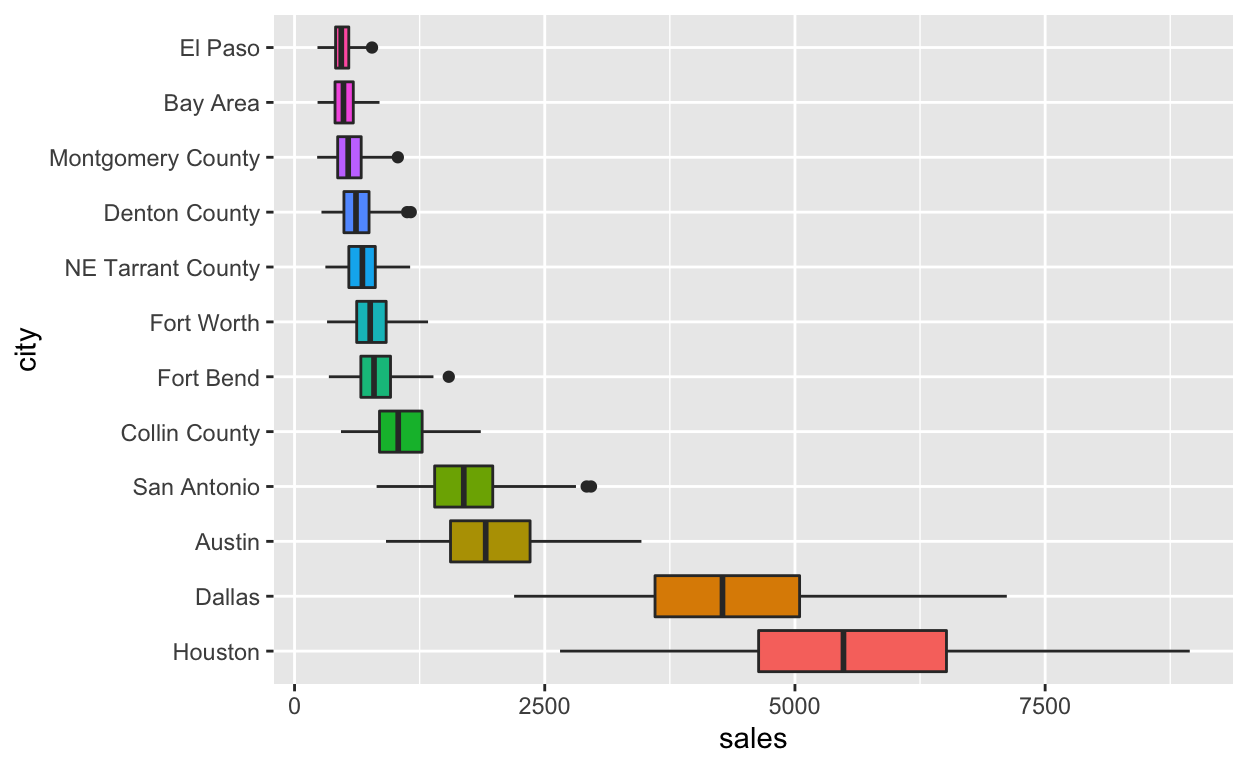
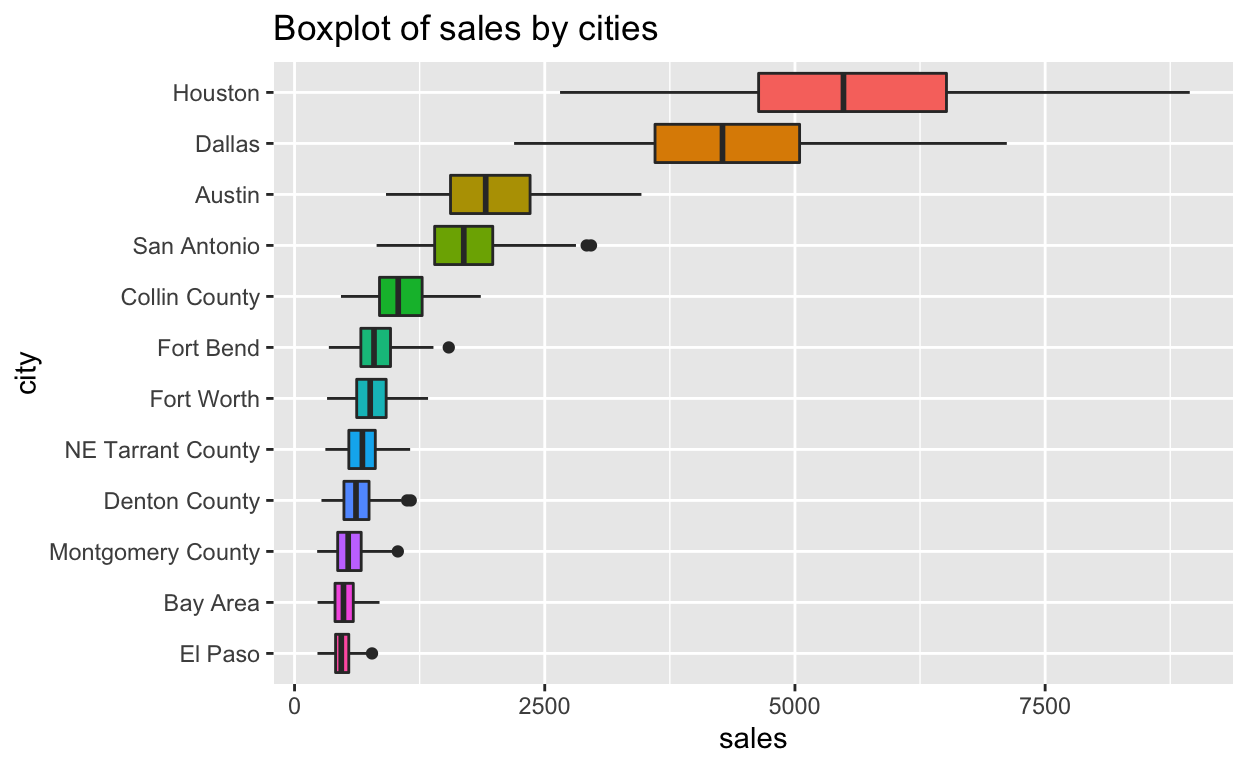
유클리드 공간을 표현하는 직교좌표계인 데카르트 좌표계(Cartesian coordinate system)는 우리가 흔히 사용하는 좌표계다. x-축과 y-축이 교차하는 좌표계에 플롯을 그릴 경우에는, x-축의 경우는 왼쪽에서 오른쪽의 방향성이 있고, y-축의 경우에는 아래에서 윗쪽으로의 방향성이 있다. 앞의 경과에서 Houstion이 맨 아래에 표현된 이유다.
사람의 공간 인지 능력은 아래서 시작해서 위로 시선을 옮기는 접근보다 위에서 아래로 시선을 옮겨가면서 파악하는 것이 수월하다. 그런데 앞의 결과는 축이 바뀌면서 y-축에 표현되는 정보가 내림차순이 아닌 오름차순으로 바뀌었다.
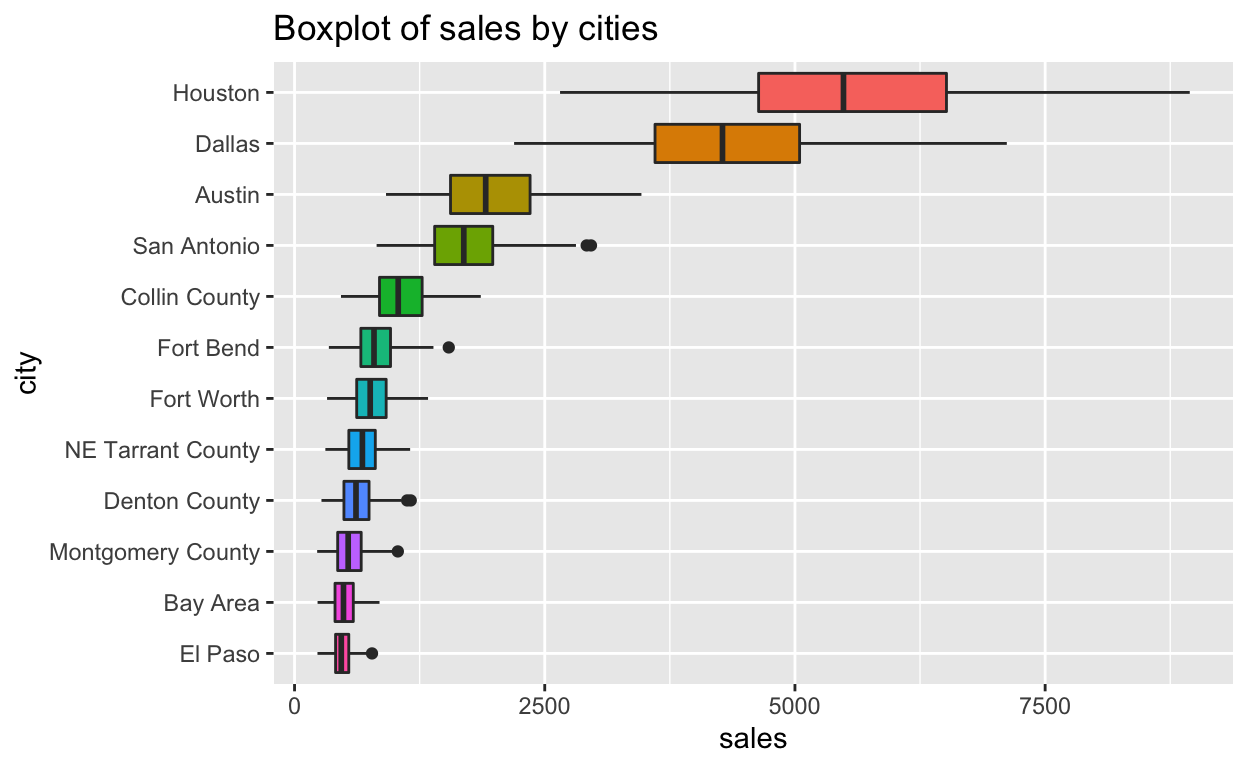
forcats 패키지의 fct_reorder()를 이용하면 순서를 바꿔 값이 큰 Houstion을 맨 위에 표현할 수 있다. 이 경우 xlab() 함수를 이용해서 x-축의 레이블을 변경해 준다. x-축과 y-축이 바뀌었으므로, xlab() 함수는 실제로 x-축의 레이블을 변경시키며, 시각적으로는 우리가 익숙하게 인식하는 y-축 방향의 레이블을 변경한다. 만약 ylab() 함수를 사용하면 sales에 해당하는, 우리가 익숙하게 인식하는 y-축 방향의 레이블이 변경되므로 주의해야 한다.
n <- 12
txhousing %>%
filter(!is.na(sales)) %>%
mutate(city = forcats::fct_reorder(city, sales, .desc = TRUE)) %>%
filter(city %in% levels(city)[1:n]) %>%
ggplot(aes(x = forcats::fct_reorder(city, desc(city)), y = sales, fill = city)) +
geom_boxplot() +
coord_flip() +
xlab("city") +
ggtitle("Boxplot of sales by cities") +
theme(legend.position = "none")
forcats 패키지의 fct_reorder()는 ggplot의 reorder() 함수로 대체할 수도 있다.
n <- 12
txhousing %>%
filter(!is.na(sales)) %>%
mutate(city = forcats::fct_reorder(city, sales, .desc = TRUE)) %>%
filter(city %in% levels(city)[1:n]) %>%
ggplot(aes(x = reorder(city, desc(city)), y = sales, fill = city)) +
geom_boxplot() +
coord_flip() +
xlab("city") +
ggtitle("Boxplot of sales by cities") +
theme(legend.position = "none")