다룰 이야기
연속형 변수가 범주화되면 디테일한 데이터의 정보가 사라진다. 예를 들면 시험성적이 96점인 학생의 A 학점은 90점으로 A 학점을 받은 학생과 동일하게 인식되지만, 두 학생의 성적 우열은 엄연히 존재한다.
모든 경우는 아니지만 연속형 변수를 비닝하면, 데이터의 분포에 따라서 이상치(outliers)로 발생할 수 있는 이슈를 회피하거나 과적합(over fitting)을 완화시켜주기도 한다. 그래서 흔하지 않지만, 가끔은 연속형 변수를 범주형 변수로 변환할 필요가 있다. 특히 금융권에서 사용하는 스코어카드 기법에서는 연속형 변수를 범주형 변수로 변환하는 작업을 빈번히 사용한다.
dlookr 패키지에는 일반적인 비닝과 스코어링 모델(Scoring Modeling)을 위한 Optimal Binning 기능을 지원한다. 여기서는 일반적인 방법으로서의 비닝에 대해서만 다룬다.
비닝(Binning)
비닝(Binning)을 쉽게 이해하려면 히스토그램을 떠올리면 된다. 다음은 iris 데이터 중 연속형 변수를 히스토그램으로 표현한 것이다. 연속형 변수를 일정한 간격으로 나누어 계급(class)을 만든 후 해당하는 계급의 구간(class interval)에 몇 개의 관측치가 포함되는지 집계한 것이 도수분포표(frequency table)다. 그리고 계급 구간별로 도수를 막대의 높이로 표현한 것이 히스토그램(histogram)이다. 원래의 데이터를 데이터가 포함된 계급에 매핑하는 범주화하는 이 작업도 비닝의 한 방법이다.
iris$Sepal.Length
[1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7
[17] 5.4 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4
[33] 5.2 5.5 4.9 5.0 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6
[49] 5.3 5.0 7.0 6.4 6.9 5.5 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1
[65] 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7
[81] 5.5 5.5 5.8 6.0 5.4 6.0 6.7 6.3 5.6 5.5 5.5 6.1 5.8 5.0 5.6 5.7
[97] 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3 6.7 7.2 6.5 6.4
[113] 6.8 5.7 5.8 6.4 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2 6.2 6.1
[129] 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8
[145] 6.7 6.7 6.3 6.5 6.2 5.9hist_info <- hist(iris$Sepal.Length, col = "lightblue")
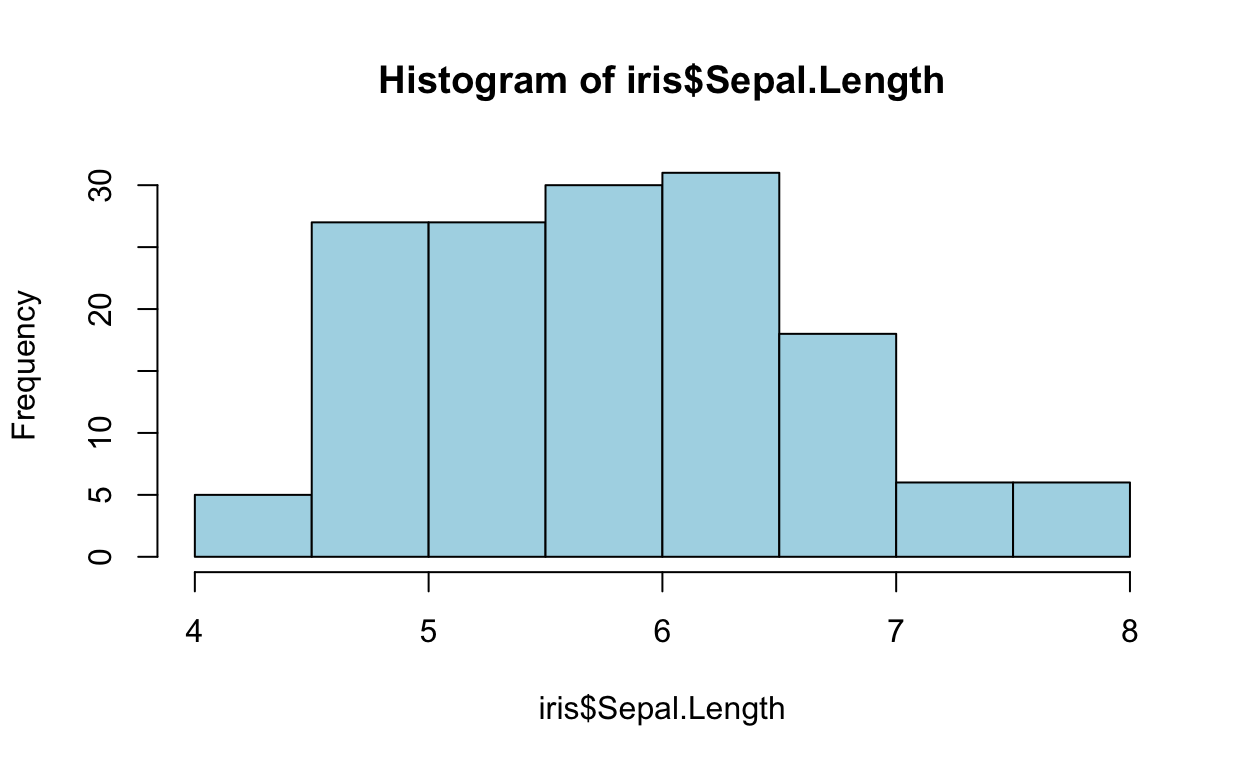
히스토그램을 그리는 hist() 함수는 유용한 정보를 list로 반환한다. 정보의 반환을 return() 함수가 아닌 invisible() 함수를 사용해서 별도의 이름에 할당한 후 그 정보를 사용할 수 있다. 특히 계급을 정의할 수 있는 계급의 경계는 breaks로, 계급 구간에 포함된 원 데이터의 개수인 도수(frequency)는 counts로 반환되었다. density는 상대도수(relative frequency)를 의미한다.
hist_info
$breaks
[1] 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0
$counts
[1] 5 27 27 30 31 18 6 6
$density
[1] 0.06666667 0.36000000 0.36000000 0.40000000 0.41333333 0.24000000
[7] 0.08000000 0.08000000
$mids
[1] 4.25 4.75 5.25 5.75 6.25 6.75 7.25 7.75
$xname
[1] "iris$Sepal.Length"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"cut() 함수로 비닝하기
R에서는 cut() 함수로 비닝한다. 그런데 사용자가 계급의 경계인 breaks를 지정해 주어야 한다. 앞에서 수행한 히스토그램의 정보를 활용해 보자.
bins <- cut(iris$Sepal.Length, breaks = hist_info$breaks)
bins
[1] (5,5.5] (4.5,5] (4.5,5] (4.5,5] (4.5,5] (5,5.5] (4.5,5] (4.5,5]
[9] (4,4.5] (4.5,5] (5,5.5] (4.5,5] (4.5,5] (4,4.5] (5.5,6] (5.5,6]
[17] (5,5.5] (5,5.5] (5.5,6] (5,5.5] (5,5.5] (5,5.5] (4.5,5] (5,5.5]
[25] (4.5,5] (4.5,5] (4.5,5] (5,5.5] (5,5.5] (4.5,5] (4.5,5] (5,5.5]
[33] (5,5.5] (5,5.5] (4.5,5] (4.5,5] (5,5.5] (4.5,5] (4,4.5] (5,5.5]
[41] (4.5,5] (4,4.5] (4,4.5] (4.5,5] (5,5.5] (4.5,5] (5,5.5] (4.5,5]
[49] (5,5.5] (4.5,5] (6.5,7] (6,6.5] (6.5,7] (5,5.5] (6,6.5] (5.5,6]
[57] (6,6.5] (4.5,5] (6.5,7] (5,5.5] (4.5,5] (5.5,6] (5.5,6] (6,6.5]
[65] (5.5,6] (6.5,7] (5.5,6] (5.5,6] (6,6.5] (5.5,6] (5.5,6] (6,6.5]
[73] (6,6.5] (6,6.5] (6,6.5] (6.5,7] (6.5,7] (6.5,7] (5.5,6] (5.5,6]
[81] (5,5.5] (5,5.5] (5.5,6] (5.5,6] (5,5.5] (5.5,6] (6.5,7] (6,6.5]
[89] (5.5,6] (5,5.5] (5,5.5] (6,6.5] (5.5,6] (4.5,5] (5.5,6] (5.5,6]
[97] (5.5,6] (6,6.5] (5,5.5] (5.5,6] (6,6.5] (5.5,6] (7,7.5] (6,6.5]
[105] (6,6.5] (7.5,8] (4.5,5] (7,7.5] (6.5,7] (7,7.5] (6,6.5] (6,6.5]
[113] (6.5,7] (5.5,6] (5.5,6] (6,6.5] (6,6.5] (7.5,8] (7.5,8] (5.5,6]
[121] (6.5,7] (5.5,6] (7.5,8] (6,6.5] (6.5,7] (7,7.5] (6,6.5] (6,6.5]
[129] (6,6.5] (7,7.5] (7,7.5] (7.5,8] (6,6.5] (6,6.5] (6,6.5] (7.5,8]
[137] (6,6.5] (6,6.5] (5.5,6] (6.5,7] (6.5,7] (6.5,7] (5.5,6] (6.5,7]
[145] (6.5,7] (6.5,7] (6,6.5] (6,6.5] (6,6.5] (5.5,6]
8 Levels: (4,4.5] (4.5,5] (5,5.5] (5.5,6] (6,6.5] ... (7.5,8]table(bins)
bins
(4,4.5] (4.5,5] (5,5.5] (5.5,6] (6,6.5] (6.5,7] (7,7.5] (7.5,8]
5 27 27 30 31 18 6 6 pretty() 함수는 적당하게 계급의 경계를 구해준다. 이 함수를 이용해서 비닝해 보자.
pretty(iris$Sepal.Length)
[1] 4 5 6 7 8 [1] (5,6] (4,5] (4,5] (4,5] (4,5] (5,6] (4,5] (4,5] (4,5] (4,5]
[11] (5,6] (4,5] (4,5] (4,5] (5,6] (5,6] (5,6] (5,6] (5,6] (5,6]
[21] (5,6] (5,6] (4,5] (5,6] (4,5] (4,5] (4,5] (5,6] (5,6] (4,5]
[31] (4,5] (5,6] (5,6] (5,6] (4,5] (4,5] (5,6] (4,5] (4,5] (5,6]
[41] (4,5] (4,5] (4,5] (4,5] (5,6] (4,5] (5,6] (4,5] (5,6] (4,5]
[51] (6,7] (6,7] (6,7] (5,6] (6,7] (5,6] (6,7] (4,5] (6,7] (5,6]
[61] (4,5] (5,6] (5,6] (6,7] (5,6] (6,7] (5,6] (5,6] (6,7] (5,6]
[71] (5,6] (6,7] (6,7] (6,7] (6,7] (6,7] (6,7] (6,7] (5,6] (5,6]
[81] (5,6] (5,6] (5,6] (5,6] (5,6] (5,6] (6,7] (6,7] (5,6] (5,6]
[91] (5,6] (6,7] (5,6] (4,5] (5,6] (5,6] (5,6] (6,7] (5,6] (5,6]
[101] (6,7] (5,6] (7,8] (6,7] (6,7] (7,8] (4,5] (7,8] (6,7] (7,8]
[111] (6,7] (6,7] (6,7] (5,6] (5,6] (6,7] (6,7] (7,8] (7,8] (5,6]
[121] (6,7] (5,6] (7,8] (6,7] (6,7] (7,8] (6,7] (6,7] (6,7] (7,8]
[131] (7,8] (7,8] (6,7] (6,7] (6,7] (7,8] (6,7] (6,7] (5,6] (6,7]
[141] (6,7] (6,7] (5,6] (6,7] (6,7] (6,7] (6,7] (6,7] (6,7] (5,6]
Levels: (4,5] (5,6] (6,7] (7,8]dlookr을 이용한 비닝
예제 데이터 생성
ISLR 패키지의 Carseats는 유아용 차량 시트 판매에 대한 정보를 담고 있다. 400개의 관측치로 11개의 변수를 가지고 있다.
Income은 소득 수준을 나타내며, 그 단위는 1000 US 달러다.
[1] 400 11names(carseats)
[1] "Sales" "CompPrice" "Income" "Advertising"
[5] "Population" "Price" "ShelveLoc" "Age"
[9] "Education" "Urban" "US" carseats[sample(seq(NROW(carseats)), 20), "Income"] <- NA
carseats[sample(seq(NROW(carseats)), 5), "Urban"] <- NA
carseats$Income
[1] 73 48 35 100 64 113 105 81 110 113 78 94 35 28 117 NA
[17] 32 74 110 76 90 29 46 31 119 32 115 118 74 99 94 58
[33] 32 38 54 84 76 41 73 60 NA 53 69 42 79 63 90 98
[49] 52 93 32 90 40 64 103 81 82 91 93 71 102 32 45 88
[65] 67 26 92 61 69 59 81 NA 45 NA 68 111 87 71 NA 67
[81] 100 72 83 36 NA 103 84 67 42 66 22 46 113 30 97 25
[97] 42 82 77 47 69 93 22 91 96 100 33 107 79 65 62 118
[113] 99 29 87 35 75 53 88 94 105 89 NA 103 NA 78 68 48
[129] 100 120 NA 69 87 98 31 94 75 42 103 62 60 42 84 88
[145] 68 63 83 54 NA 120 84 58 78 36 69 72 34 58 90 60
[161] 28 21 74 64 64 58 67 73 89 41 39 NA 102 91 24 89
[177] 107 72 71 25 112 83 60 74 33 100 51 32 37 117 37 42
[193] 26 70 98 93 28 61 80 88 92 83 78 82 80 22 67 105
[209] 54 21 41 118 69 84 115 83 33 44 61 79 120 44 119 45
[225] 82 25 33 64 73 104 60 69 80 76 62 32 34 28 24 105
[241] 80 63 46 25 30 43 56 NA 52 67 105 111 97 24 104 81
[257] 40 NA 38 36 117 42 77 26 29 35 93 82 57 69 26 56
[273] 33 106 93 119 69 48 113 57 86 NA 96 110 46 26 118 44
[289] NA 77 111 70 66 84 76 35 44 83 63 40 NA 93 77 52
[305] 98 29 32 92 80 111 65 68 117 81 33 21 36 30 72 45
[321] 70 39 50 105 65 69 30 38 66 54 NA 63 33 60 117 70
[337] 35 38 24 44 29 120 102 42 80 68 107 39 NA 27 101 115
[353] 103 67 31 100 109 73 96 62 86 25 55 75 21 30 56 106
[369] NA 100 41 81 NA 71 47 46 60 61 88 111 64 65 28 117
[385] 37 73 116 73 89 42 75 63 42 51 58 108 23 26 79 37비닝하기
dlookr 패키지의 binning() 함수는 연속형 변수를 범주형 변수로 비닝한다. Income을 비닝해 보자. 소득이 10개 소득 구간의 범주로 비닝되었다.
binned type: quantile
number of bins: 10
x
[21,30] (30,38] (38,47.43333]
39 38 37
(47.43333,61.46667] (61.46667,69] (69,76.53333]
38 45 31
(76.53333,84] (84,95.2] (95.2,107]
41 35 40
(107,120] <NA>
36 20 summary() 함수는 범주화된 구간의 도수분포표(frequency table)를 구해준다.
summary(bin)
levels freq rate
1 [21,30] 39 0.0975
2 (30,38] 38 0.0950
3 (38,47.43333] 37 0.0925
4 (47.43333,61.46667] 38 0.0950
5 (61.46667,69] 45 0.1125
6 (69,76.53333] 31 0.0775
7 (76.53333,84] 41 0.1025
8 (84,95.2] 35 0.0875
9 (95.2,107] 40 0.1000
10 (107,120] 36 0.0900
11 <NA> 20 0.0500plot() 함수는 범주화된 구간에 대한 분포를 시각화한다. 플롯 상단은 변형된 히스토그램이다. 일반적으로 히스토그램은 구간의 너비는 동일하고, 높이로 그 밀도를 가늠한다. 그러나 이 변형된 히스토그램은 구간의 너비가 실제 구간의 길이와 동일하게 표현된다. 그러므로 높이가 밀도를 의미하지 않는다. “밀도는 사각형의 너비 \(\times\) 사각형의 높이다.” 즉, 기본 히스토그램보다 더 많은 정보를 표현한다.
기본에 우리가 알고 있는 히스토그램은 아래의 막대 그래프와 유사하다. 즉, 두 플롯을 이용해서 데이터의 분포를 좀 더 직관적으로 파악할 수 있는 시각화 도구다.
plot(bin)
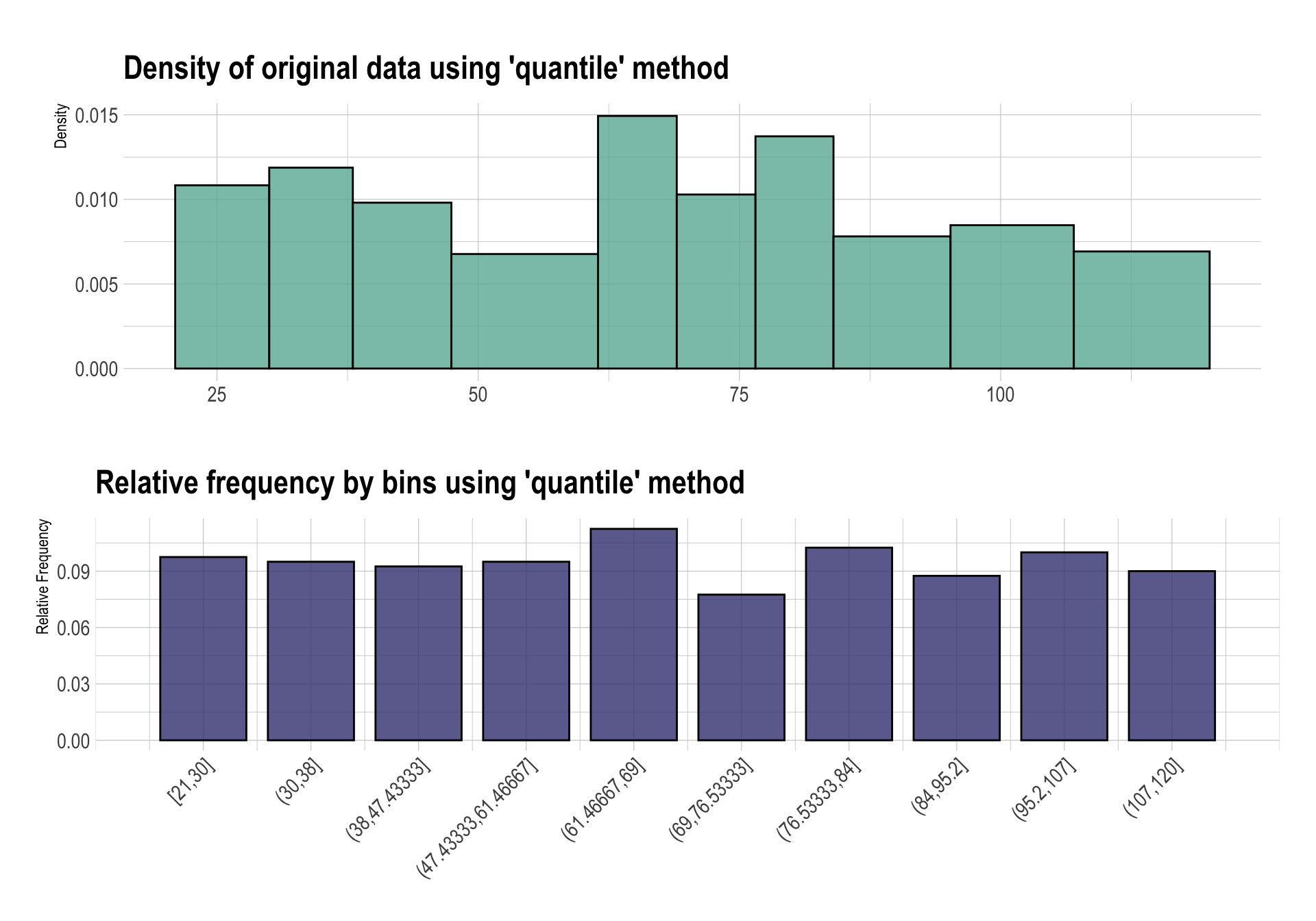
앞에서 소득을 소득 구간으로 비닝할 때 사용한 비닝 방법은 “quantile”이다. 이 방법은 분위수의 간격이 동일하게 구간을 나눈다. 그러므로 구간이 10개이므로 첫째 구간은 0~10% 분위수 구간이다. 즉, 10% 분위수는 30이다. 연산 과정에서 정확하게 딱 떨어지지는 않지만, 범주별로 동일한(거의) 도수를 갖게 된다.
이번에는 각 구간의 너비(interval)가 동일하게 비닝한다. 간단하게 type 인수값을 “equal”로 지정한다.
bin_equal <- binning(carseats$Income, type = "equal")
bin_equal
binned type: equal
number of bins: 10
x
[21,30.9] (30.9,40.8] (40.8,50.7] (50.7,60.6] (60.6,70.5]
39 44 35 30 53
(70.5,80.4] (80.4,90.3] (90.3,100.2] (100.2,110.1] (110.1,120]
45 41 35 27 31
<NA>
20 summary(bin_equal)
levels freq rate
1 [21,30.9] 39 0.0975
2 (30.9,40.8] 44 0.1100
3 (40.8,50.7] 35 0.0875
4 (50.7,60.6] 30 0.0750
5 (60.6,70.5] 53 0.1325
6 (70.5,80.4] 45 0.1125
7 (80.4,90.3] 41 0.1025
8 (90.3,100.2] 35 0.0875
9 (100.2,110.1] 27 0.0675
10 (110.1,120] 31 0.0775
11 <NA> 20 0.0500plot(bin_equal)
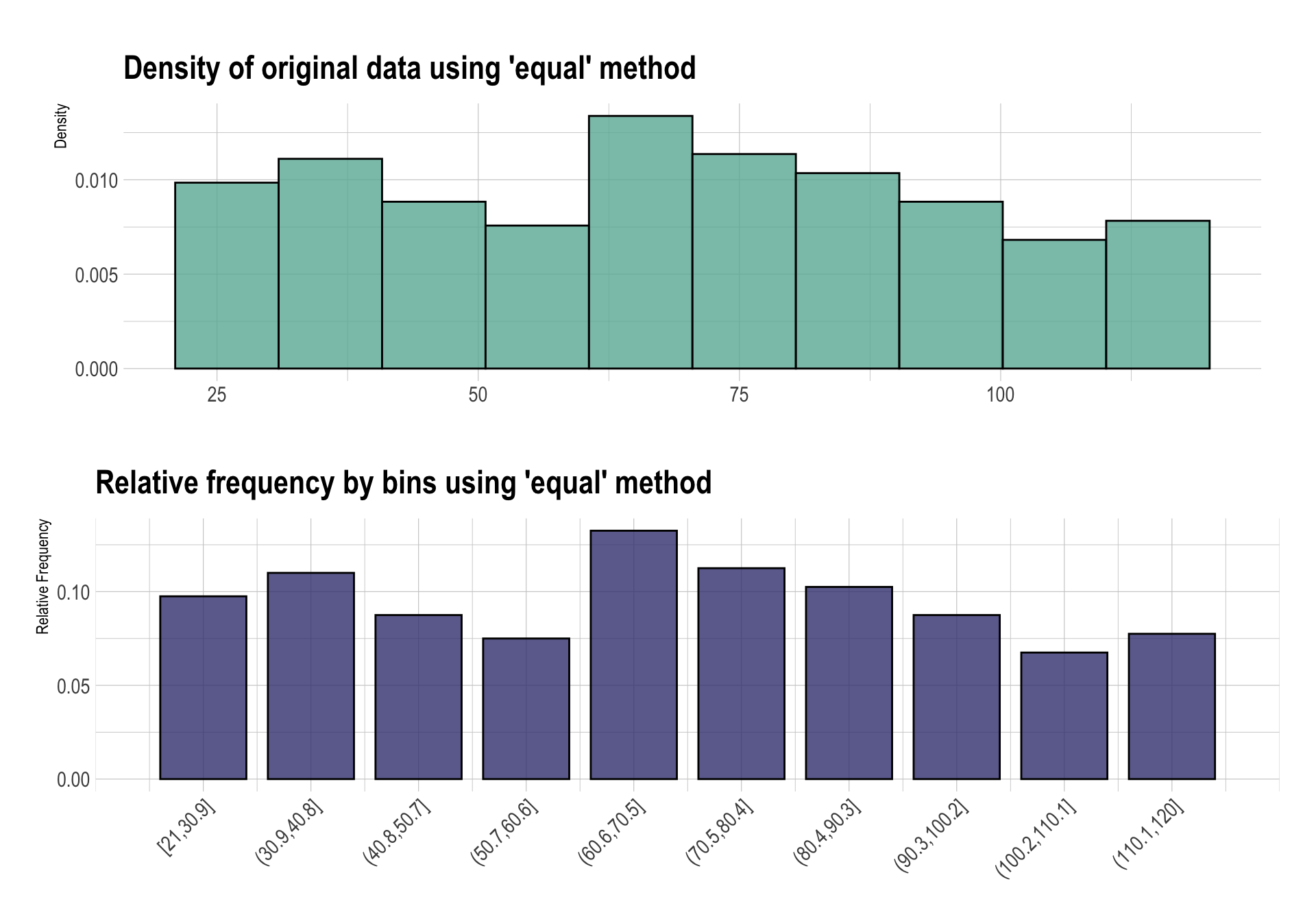
이번에는 각 구간의 너비(interval)가 동일하게 비닝한다. 간단하게 type 인수값을 “equal”로 지정한다.
bin_equal <- binning(carseats$Income, type = "equal")
bin_equal
binned type: equal
number of bins: 10
x
[21,30.9] (30.9,40.8] (40.8,50.7] (50.7,60.6] (60.6,70.5]
39 44 35 30 53
(70.5,80.4] (80.4,90.3] (90.3,100.2] (100.2,110.1] (110.1,120]
45 41 35 27 31
<NA>
20 summary(bin_equal)
levels freq rate
1 [21,30.9] 39 0.0975
2 (30.9,40.8] 44 0.1100
3 (40.8,50.7] 35 0.0875
4 (50.7,60.6] 30 0.0750
5 (60.6,70.5] 53 0.1325
6 (70.5,80.4] 45 0.1125
7 (80.4,90.3] 41 0.1025
8 (90.3,100.2] 35 0.0875
9 (100.2,110.1] 27 0.0675
10 (110.1,120] 31 0.0775
11 <NA> 20 0.0500plot(bin_equal)
이번에는 내부적으로 base 패키지의 pretty() 함수를 사용하는 “pretty” 방법이다. 간단하게 type 인수값을 “pretty”로 지정한다. 결과는 데이터에 따라 다르지만, 이번 데이터 사례는 “equal” 방법과 동일한 결과로 비닝한다.
bin_pretty <- binning(carseats$Income, type = "pretty")
bin_pretty
binned type: pretty
number of bins: 10
x
[20,30] (30,40] (40,50] (50,60] (60,70] (70,80] (80,90]
39 44 35 30 53 45 41
(90,100] (100,110] (110,120] <NA>
35 27 31 20 summary(bin_pretty)
levels freq rate
1 [20,30] 39 0.0975
2 (30,40] 44 0.1100
3 (40,50] 35 0.0875
4 (50,60] 30 0.0750
5 (60,70] 53 0.1325
6 (70,80] 45 0.1125
7 (80,90] 41 0.1025
8 (90,100] 35 0.0875
9 (100,110] 27 0.0675
10 (110,120] 31 0.0775
11 <NA> 20 0.0500plot(bin_pretty)
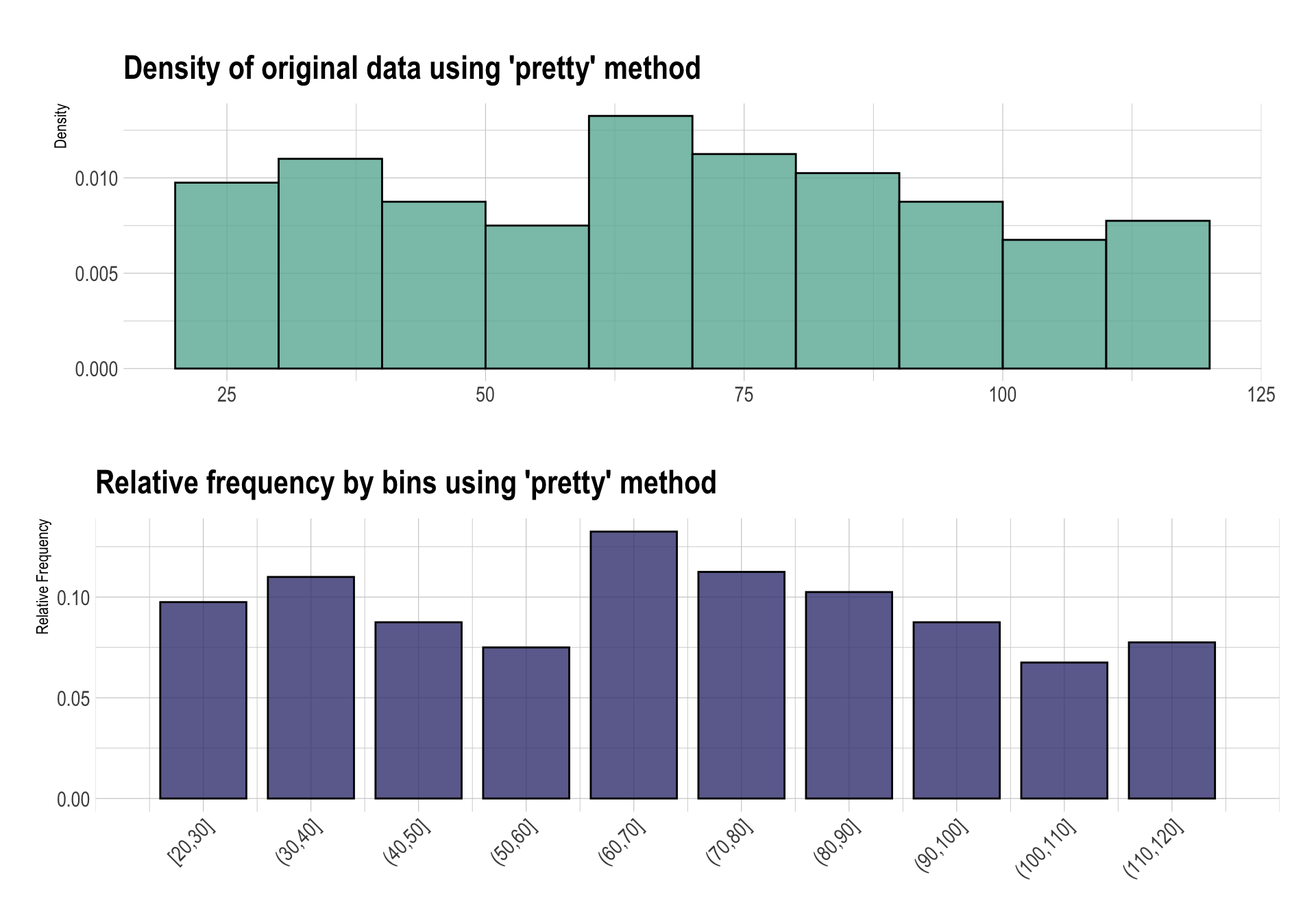
“kmenas” 방법은 Kmeans 클러스터링 기법을 이용해서 비닝한다. 하나의 연속형 변수로 Kmeans 클러스터링 후, 같은 클러스터에 포함된 값들을 하나의 구간으로 나눈다. 하나의 변수로 클러스터링하기 때문에 구간이 단조(monotonic, 주어진 순서를 보존하면서 상승/하강) 증가하게 형성된다.
bin_kmeans <- binning(carseats$Income, type = "kmeans")
bin_kmeans
binned type: kmeans
number of bins: 10
x
[21,33.5] (33.5,42.5] (42.5,51.5] (51.5,60.5] (60.5,67.5]
57 40 23 28 34
(67.5,75.5] (75.5,85] (85,96.5] (96.5,108.5] (108.5,120]
42 45 38 38 35
<NA>
20 summary(bin_kmeans)
levels freq rate
1 [21,33.5] 57 0.1425
2 (33.5,42.5] 40 0.1000
3 (42.5,51.5] 23 0.0575
4 (51.5,60.5] 28 0.0700
5 (60.5,67.5] 34 0.0850
6 (67.5,75.5] 42 0.1050
7 (75.5,85] 45 0.1125
8 (85,96.5] 38 0.0950
9 (96.5,108.5] 38 0.0950
10 (108.5,120] 35 0.0875
11 <NA> 20 0.0500plot(bin_kmeans)
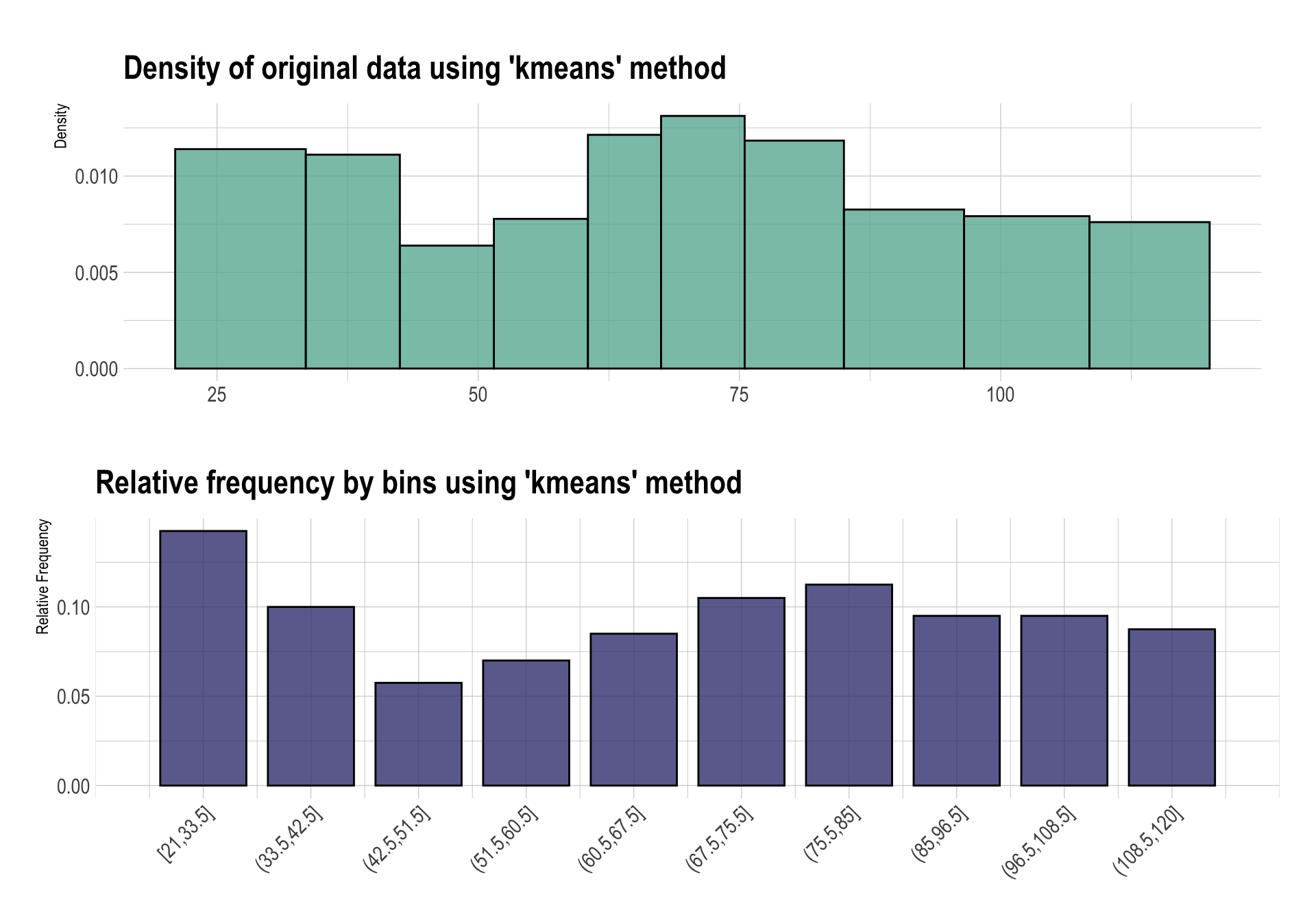
type 인수값을 “bclust”로 지정하면 bagged clustering을 수행하여 비닝한다.
bin_bclust <- binning(carseats$Income, type = "bclust")
bin_bclust
binned type: bclust
number of bins: 10
x
[21,31.5] (31.5,36.5] (36.5,49] (49,62.5] (62.5,70.5]
42 27 48 39 45
(70.5,76.5] (76.5,85] (85,95] (95,107.5] (107.5,120]
27 41 35 40 36
<NA>
20 summary(bin_bclust)
levels freq rate
1 [21,31.5] 42 0.1050
2 (31.5,36.5] 27 0.0675
3 (36.5,49] 48 0.1200
4 (49,62.5] 39 0.0975
5 (62.5,70.5] 45 0.1125
6 (70.5,76.5] 27 0.0675
7 (76.5,85] 41 0.1025
8 (85,95] 35 0.0875
9 (95,107.5] 40 0.1000
10 (107.5,120] 36 0.0900
11 <NA> 20 0.0500plot(bin_bclust)
비닝 결과의 추출
비닝한 결과를 서머리하거나 시각화한 후 비닝한 결과에 확신이 생긴다면, extract() 함수로 비닝한 데이터를 추출한다. 마지막 예제, bagged clustering 기법의 비닝 결과를 채택하였다고 가정한다.
carseats$Income_bin <- extract(bin_bclust)
비닝된 모든 관측치를 살펴보기에는 건수가 크니 앞의 20건만 살펴보자.
head(carseats$Income_bin, n = 10)
[1] (70.5,76.5] (36.5,49] (31.5,36.5] (95,107.5] (62.5,70.5]
[6] (107.5,120] (95,107.5] (76.5,85] (107.5,120] (107.5,120]
10 Levels: [21,31.5] < (31.5,36.5] < (36.5,49] < ... < (107.5,120]dplyr 패키지와의 협업
dlookr 패키지는 dplyr 패키지와 궁합이 잘 맞는다. 다음은 Income을 비닝 후 ShelveLoc 변수의 수준(levels)별로 비닝 구간의 분포를 비교한다.
library(dplyr)
carseats %>%
mutate(Income_bin = binning(carseats$Income) %>%
extract()) %>%
group_by(ShelveLoc, Income_bin) %>%
summarise(freq = n()) %>%
arrange(ShelveLoc, desc(freq))
# A tibble: 33 x 3
# Groups: ShelveLoc [3]
ShelveLoc Income_bin freq
<fct> <ord> <int>
1 Bad (76.53333,84] 12
2 Bad (47.43333,61.46667] 11
3 Bad (61.46667,69] 11
4 Bad (107,120] 11
5 Bad (38,47.43333] 10
6 Bad (84,95.2] 10
7 Bad (95.2,107] 10
8 Bad (30,38] 7
9 Bad [21,30] 5
10 Bad (69,76.53333] 5
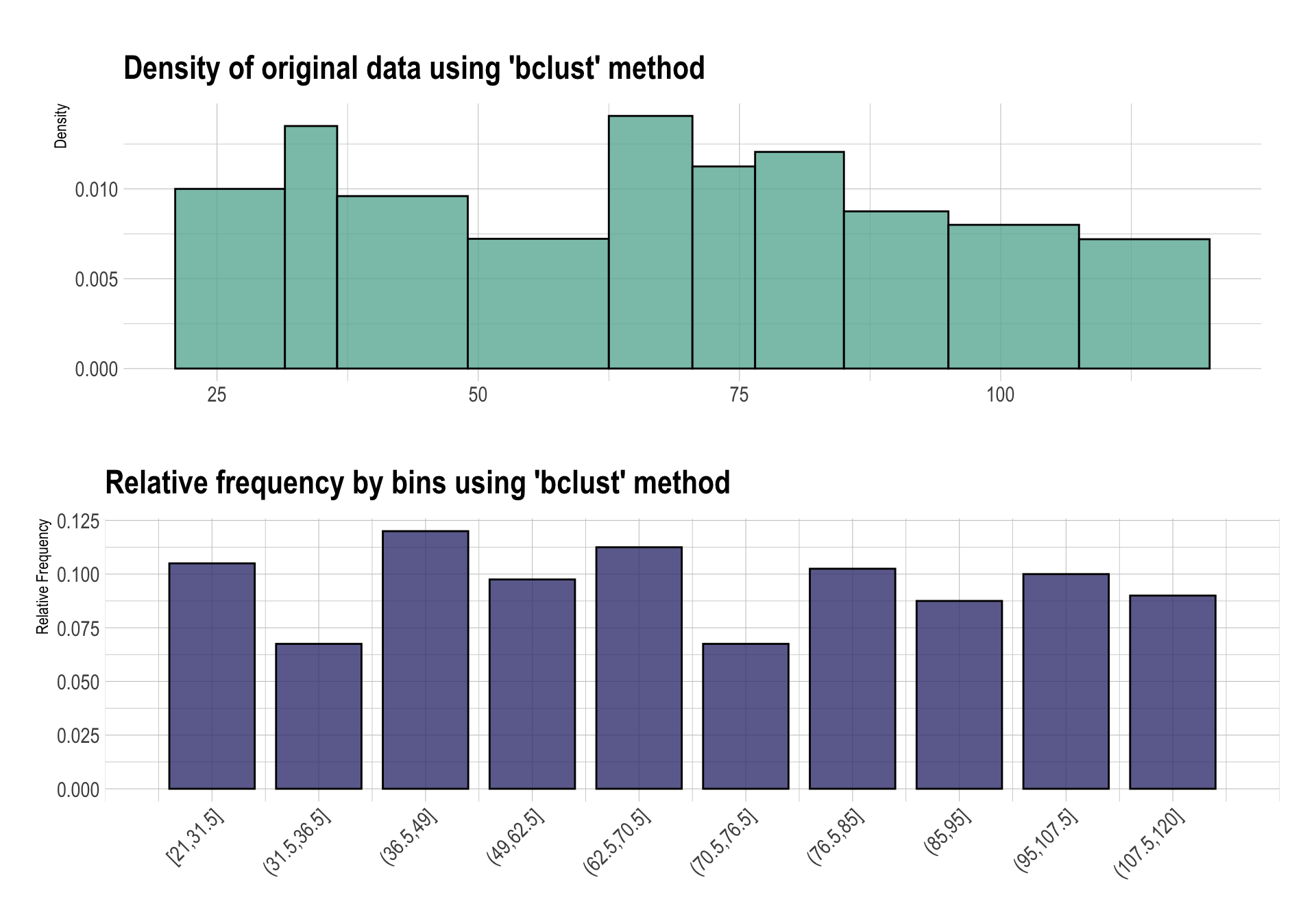
# … with 23 more rowsdlookr 패키지의 target_by(), relate(), plot.relate() 함수를 이용하면, dplyr 구문 형태로 쉽게 그 분포를 시각화 할 수 있다.
carseats %>%
mutate(Income_bin = binning(carseats$Income) %>%
extract()) %>%
target_by(ShelveLoc) %>%
relate(Income_bin) %>%
plot()
그 밖의 기능
binning() 함수는 비닝 결과를 조정하는 여러 인수를 지원한다. 하나씩 살펴보자.
Bins 개수 지정하기
nbins 인수는 비닝된 범주의 개수를 지정한다. 이 인수를 사용하면 알고리즘을 통해 관측치의 개수를 고려해서 적당한 범주로 나눈다. 그러나 경우에 따라서 분석가가 원하는 범주의 개수와 다를 수 있다. 이 경우에 nbins 인수로 범주의 개수를 지정할 수 있다.
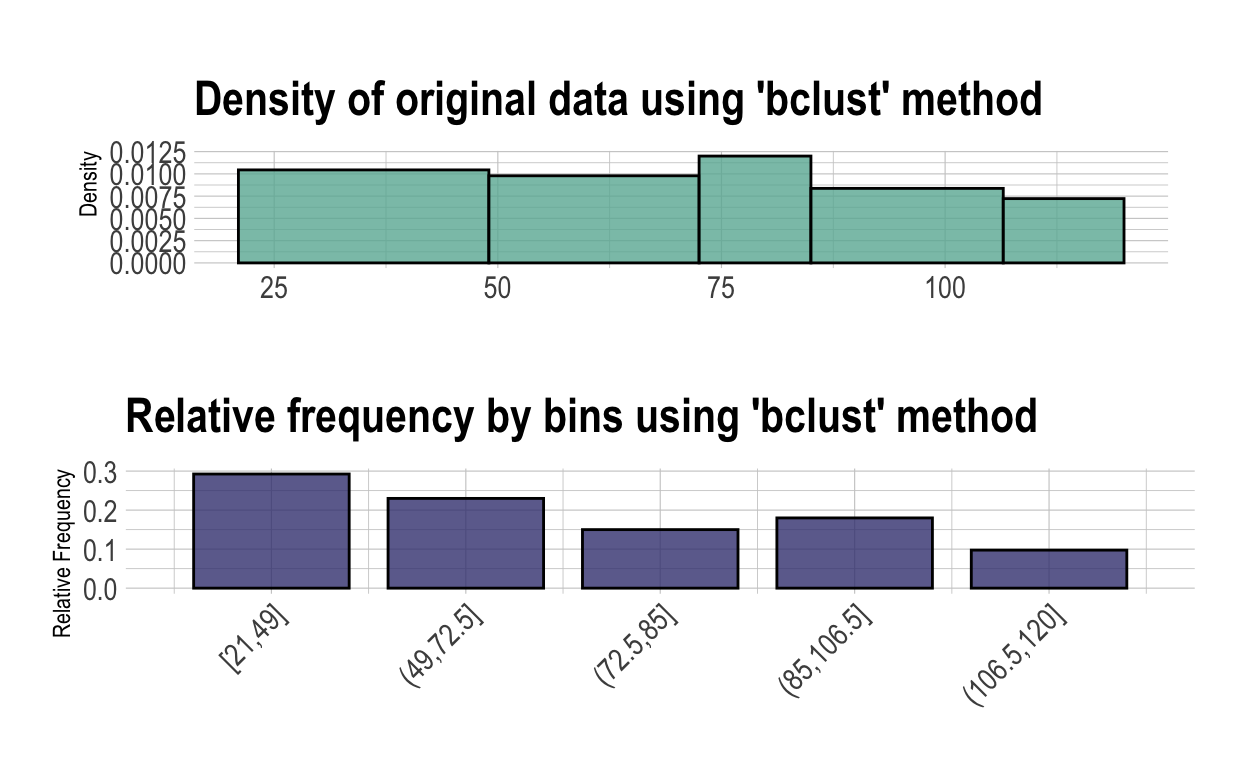
bin_bclust <- binning(carseats$Income, type = "bclust", nbins = 5)
bin_bclust
binned type: bclust
number of bins: 5
x
[21,49] (49,72.5] (72.5,85] (85,106.5] (106.5,120]
117 92 60 72 39
<NA>
20 summary(bin_bclust)
levels freq rate
1 [21,49] 117 0.2925
2 (49,72.5] 92 0.2300
3 (72.5,85] 60 0.1500
4 (85,106.5] 72 0.1800
5 (106.5,120] 39 0.0975
6 <NA> 20 0.0500plot(bin_bclust)
ordered factor 또는 factor
binning() 함수로 만들어진 범주는 R의 ordered factor로 반환된다. 만약 분석가가 ordered factor가 아닌 factor를 원한다면 ordered 인수값에 FALSE를 지정한다. 기본값은 TRUE이기 때문에 앞에서 수행한 모든 예제는 순서 범주형인 ordered factor로 반환되었다.
[1] (67.5,76.5] (39.5,50.5] (27.5,39.5] (95,109.5] (56.5,67.5]
[6] (109.5,120]
10 Levels: [21,27.5] < (27.5,39.5] < (39.5,50.5] < ... < (109.5,120]bin_bclust <- binning(carseats$Income, type = "bclust", ordered = FALSE)
extract(bin_bclust) %>%
head()
[1] (69.5,79.5] (47.5,56.5] (27.5,35.5] (95,107.5] (56.5,69.5]
[6] (107.5,120]
10 Levels: [21,27.5] (27.5,35.5] (35.5,47.5] ... (107.5,120]범주 라벨 지정하기
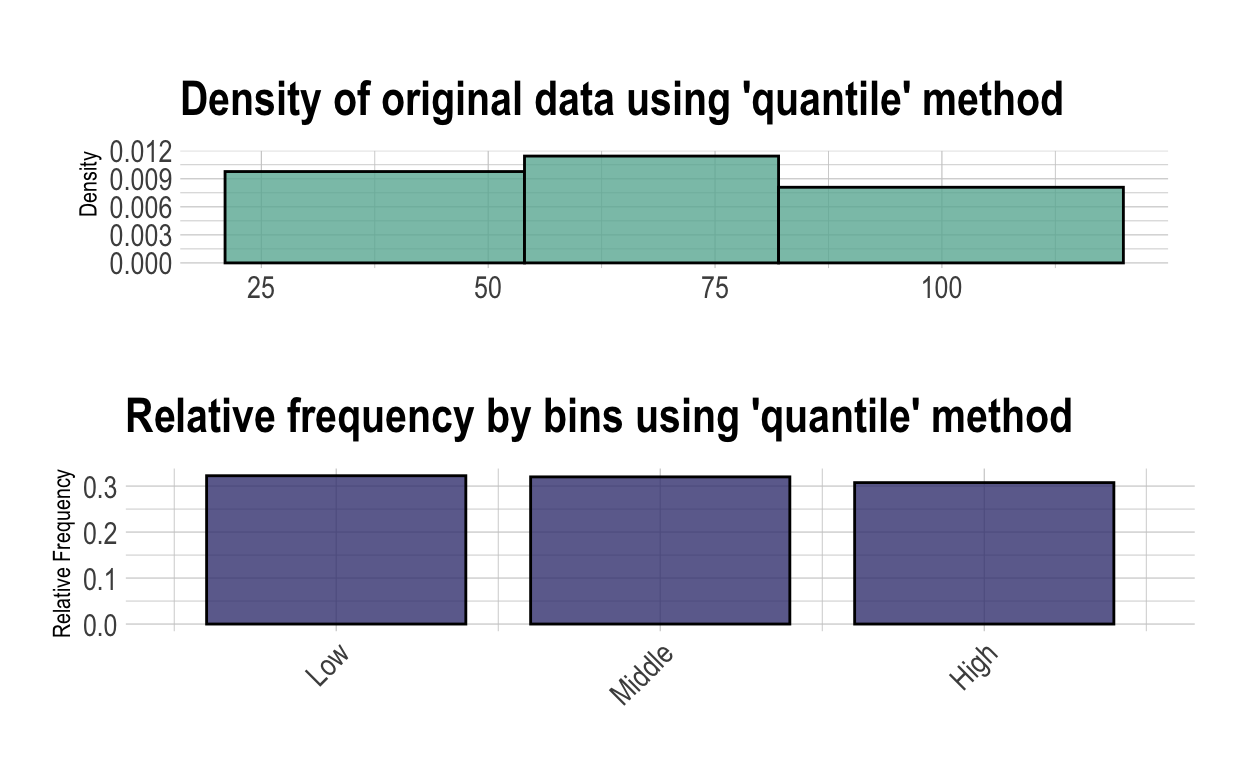
범주 라벨 이름을 breaks를 이용해서 (34.5,49]와 같이 표현할 수도 았지만, 분석가가 labels 인수를 사용해서 다음처럼 의미를 부여할 수도 있다.
binned type: quantile
number of bins: 3
x
Low Middle High <NA>
129 128 123 20 summary(bin)
levels freq rate
1 Low 129 0.3225
2 Middle 128 0.3200
3 High 123 0.3075
4 <NA> 20 0.0500plot(bin)
Breaks를 이쁘게 다듬기
연속형 변수에서 breaks는 일반적으로 소수점으로 만들어진다. 이 경우에는 개별 breaks의 소수점 아래 자리수가 다를 수 있다. 다른 자리수로 만든 범주는 시각적으로 해석하기에 거추장스럽다. 이 경우에는 approxy.lab 인수를 TRUE로 지정하면 비닝 breaks를 근사치로 변환해서 깔끔한 형태로 바꿔준다. 기본값이 TRUE이기 때문에 별도로 지정하지 않아도 된다.
bin <- binning(carseats$Income, type = "bclust", approxy.lab = FALSE)
bin
binned type: bclust
number of bins: 10
x
[21,30.5] (30.5,37.5] (37.5,50.5] (50.5,62.5] (62.5,70.5]
39 34 45 38 45
(70.5,76.5] (76.5,85] (85,96.5] (96.5,107.5] (107.5,120]
27 41 38 37 36
<NA>
20 bin <- binning(carseats$Income, type = "bclust", approxy.lab = TRUE)
bin
binned type: bclust
number of bins: 10
x
[21,31.5] (31.5,37.5] (37.5,50.5] (50.5,59.5] (59.5,65.5]
42 31 45 23 31
(65.5,75.5] (75.5,85] (85,95] (95,107.5] (107.5,120]
52 45 35 40 36
<NA>
20