들어가기
SQL에 익숙한 당신, dplyr를 쉽게 배울 수 있습니다.파이프를 이용한 dplyr의 사용은 SQL의 순차적인 Syntax를 그대로 이식시켜 주며, 집합론적인 사고의 로직도 쉽게 적용할 수 있기 때문입니다.
미리보기
SQL과 dplyr 비교
가상의 데이터를 집계하는 다음의 Script를 보면 dplyr의 문법이 SQL 문번과 상당히 유사함을 발견할 수 있습니다.
SQL
다음은 데이터를 집계하는 가상의 SQL 구문입니다.
SELECT col1,
CASE col2
WHEN '1' THEN 'TRUE'
WHEN '0' THEN 'FALSE'
ELSE 'FALSE'
END AS col2,
SUM(col3) AS col3
FROM T_TABS
WHERE col3 > 34
AND col4 in ('a', 'b', 'c')
GROUP BY col1,
CASE col2
WHEN '1' THEN 'TRUE'
WHEN '0' THEN 'FALSE'
ELSE 'FALSE'
ORDER BY col3 DESCdplyr
데이터를 집계하는 가상의 SQL 구문을 dplyr로 변환하면 다음과 같습니다.
데이터를 조인하는 방법도 유사합니다.
SQL
다음은 두 개의 데이터를 조인하는 가상의 SQL 구문입니다.
SELECT a.empno
, a.ename
, a.job
, a.mgr
, a.deptno
, b.dname
FROM emp AS a
LEFT JOIN dept AS b
ON a.deptno = b.deptnodplyr
두 개의 데이터를 조인하는 가상의 SQL 구문을 dplyr로 변환하면 다음과 같습니다.
emp %>%
select(empno, ename, job, deptno) %>%
left_join(
dept %>%
select(deptno, dname),
by = c("deptno")
)
솔루션
데이터 조작은 속도도 중요하지만, 빠른 시간 내에 정확한 스크립트를 작성하거나, 공유를 위한 해석의 용이성도 중요합니다. 이것을 만족하는 것이 dplyr입니다.준비하기
데이터 준비하기
nycflights13 패키지는 2013년도의 NYC 공항 출발 항공편과 관련된 데이터를 담은, 유용한 데이터 패키지입니다.
- 데이터의 종류
- flights
- 메인 데이터로 NYC 공항 출발 항공편 데이터
- On-time data for all flights that departed NYC (i.e. JFK, LGA or EWR) in 2013.
- airlines
- 항공사에 대한 메타 데이터
- Look up airline names from their carrier codes.
- airports
- 공항에 대한 메타 데이터
- Useful metadata about airports.
- planes
- 항공기에 대한 메타 데이터
- Plane metadata for all plane tailnumbers.
- weather
- 시간대별 기상 데이터
- Hourly meterological data for LGA, JFK and EWR.
- flights
워밍업
데이터 살펴보기
flights 데이터 프레임에는 2013년에 뉴욕에서 출발한 모든 336,776개의 항공편이 포함되어 있습니다. 이 데이터는 미국 교통 통계국에서 가져왔습니다.
library(tidyverse)
library(nycflights13)
flights
# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# … with 336,766 more rows, and 12 more variables:
# sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>,
# time_hour <dttm>dplyr 기초 다지기
필터링과 집계
Hands-on 1
- 년말(12월 31일)과 년초(1월 1일)의 비행 현황을 살펴보려 합니다. 해당 데이터를 추출해서 flights_1231_0101 데이터 프레임에 저장해보세요.
- 추출한 데이터를 날짜별로 몇 건인지 확인해 보세요.
힌트
- 변수 month와 day가 월과 일을 나타냅니다.
- filter() 함수를 사용합니다.
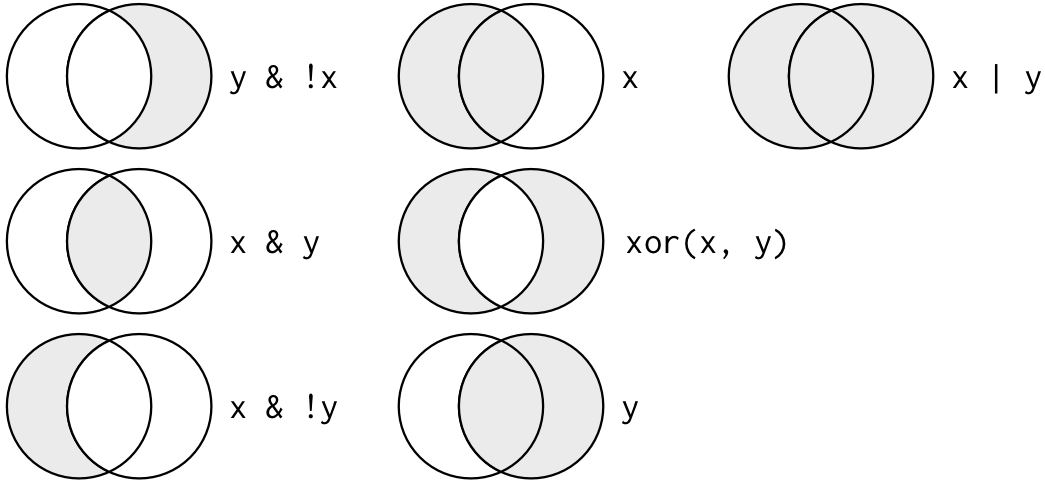
- 논리합 연산자 |와 논리곱 연산자 &를 사용하면 되겠지요.
- group_by()와 summarise() 함수를 사용합니다.
- n() 함수는 개수를 세는 함수입니다.
dplyr 솔루션
건수만 살펴볼 경우에는 tally() 함수가 유용합니다.
flights_1231_0101 <- flights %>%
filter((month == 12 & day == 31) |
(month == 1 & day == 1))
flights_1231_0101 %>%
group_by(month, day) %>%
summarise(cnt = n())
# A tibble: 2 x 3
# Groups: month [2]
month day cnt
<int> <int> <int>
1 1 1 842
2 12 31 776flights_1231_0101 %>%
group_by(month, day) %>%
tally()
# A tibble: 2 x 3
# Groups: month [2]
month day n
<int> <int> <int>
1 1 1 842
2 12 31 776파생변수 만들기
Hands-on 2
- 년말(12월 31일) 년초(1월 1일)와 그렇지 않은 날짜의 출발 지연시간의 평균을 비교해 보세요.
힌트
- mutate() 함수를 사용합니다.
- ifelse() 함수를 사용할 수 있습니다.
- 역시 논리합 연산자 |와 논리곱 연산자 &를 사용해야 겠지요.
- group_by()와 summarise() 함수를 사용합니다.
- dep_delay가 출발 지연시간을 나타내는 변수입니다.
dplyr 솔루션
ifelse() 함수 대신에 dplyr 패키지의 case_when() 함수를 사용해도 됩니다. 이 함수는 조건의 개수가 여러 개일 때 유용합니다.
flights %>%
mutate(class_date = ifelse((month == 12 & day == 31) |
(month == 1 & day == 1), "연말년초", "연말년초 아님")) %>%
group_by(class_date) %>%
summarise(dep_delay_avg = mean(dep_delay, na.rm = TRUE))
# A tibble: 2 x 2
class_date dep_delay_avg
<chr> <dbl>
1 연말년초 9.38
2 연말년초 아님 12.7 flights %>%
mutate(class_date = case_when(
(month == 12 & day == 31) | (month == 1 & day == 1) ~ "연말년초",
TRUE ~ "연말년초 아님")) %>%
group_by(class_date) %>%
summarise(dep_delay_avg = mean(dep_delay, na.rm = TRUE))
# A tibble: 2 x 2
class_date dep_delay_avg
<chr> <dbl>
1 연말년초 9.38
2 연말년초 아님 12.7 순위 계산하기
Hands-on 3
- 출발 지연시간의 평균이 큰 5개의 날짜를 추출하세요.
힌트
- group_by() 함수와 summarise() 함수로 집계합니다.
- arrange() 함수와 desc() 함수로 정렬합니다.
- row_number() 함수로 관측치의 순번을 구한 후, filter() 함수로 원하는 대상을 가져옵니다.
dplyr 솔루션
상위 n개의 관측치를 가져오기 위해서 filter() 함수와 row_number() 함수를 사용할 수 있으나, top_n() 함수를 사용하면 쉽게 계산할 수 있습니다.
flights %>%
group_by(month, day) %>%
summarise(dep_delay_avg = mean(dep_delay, na.rm = TRUE),
.groups = "drop") %>%
arrange(desc(dep_delay_avg)) %>%
filter(row_number() <= 5)
# A tibble: 5 x 3
month day dep_delay_avg
<int> <int> <dbl>
1 3 8 83.5
2 7 1 56.2
3 9 2 53.0
4 7 10 52.9
5 12 5 52.3flights %>%
group_by(month, day) %>%
summarise(dep_delay_avg = mean(dep_delay, na.rm = TRUE),
.groups = "drop") %>%
arrange(desc(dep_delay_avg)) %>%
top_n(5)
# A tibble: 5 x 3
month day dep_delay_avg
<int> <int> <dbl>
1 3 8 83.5
2 7 1 56.2
3 9 2 53.0
4 7 10 52.9
5 12 5 52.3응용하기
집계 데이터의 시각화
ggplot2 패키지와의 연동
Hands-on 4
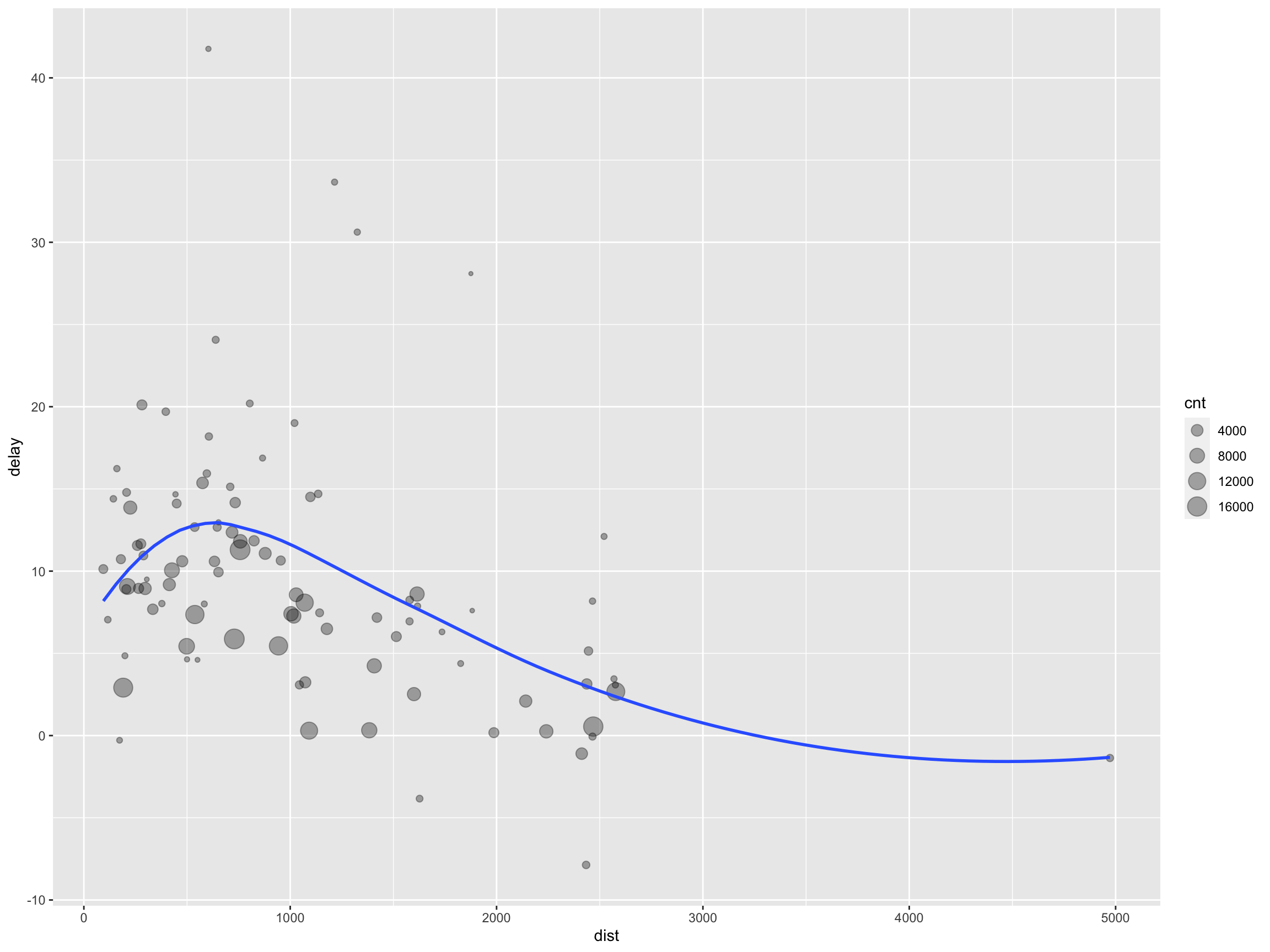
- 비행거리와 도착 지연 시간과의 관계를 살펴보려고 합니다.
- 목적지인 dest별로 운항횟수를 계산하세요.
- 목적지인 dest별로 거리(distance)의 평균과 도착 지연시간(arr_delay)의 평균을 구하세요.
- 년간 운행횟수가 20회보다 큰 노선을 대상으로 집계하세요.
- 1번 결과로 거리별 평균 도착 지연시간의 관계를 시각화하세요.
- 산점도를 그리되, 운행횟수로 점의 크기를 나타내세요.
- x-축은 거리를, y-축은 도착지연시간을 나타내세요.
- Smooth 곡선을 추가해 보세요.
힌트
- 먼저 group_by()와 summarise() 함수를 사용 후, filter() 함수를 사용합니다.
- geom_point() 함수로 산점도를 그리고,
- geom_smooth() 함수로 Smooth 곡선을 그립니다.
dplyr 솔루션
dplyr 결과를 바로 ggplot2 시각화 함수인 ggplot() 함수로 보낼 수 있습니다. dplyr 패키지의 파이프인 “%>%”와 ggplot2의 파이프인 “+”를 혼동해서는 안됩니다.
데이터 결합
조인하기
Hands-on 5
- 항공기별로 데이터를 집계합니다.
- flights 데이터와 planes 데이터를 조인합니다.
- 도착 지연시간이 큰 상위 10개의 항공기 제조사, 항공기 모델을 추출하세요.
- 어떤 엔진을 사용하고 있나요?
힌트
- left_join() 함수를 사용합니다. 그리고 조인 변수는 “tailnum”입니다.
- 순서로 일부 데이터를 가져오기 때문에 summarise() 함수에는 .groups = “drop”를 적용합니다.
- top_n() 함수를 사용합니다.
dplyr 솔루션
summarise() 함수에는 .groups = “drop”를 적용하지 않으면, 상위 n개가 아닌 전체 건이 추출됩니다. .groups = “drop”는 집계된 데이터에 그룹정보를 삭제하는 옵션입니다.
flights %>%
left_join(
planes,
by = "tailnum"
) %>%
group_by(manufacturer, model, engine) %>%
summarise(delay = mean(arr_delay, na.rm = TRUE),
.groups = "drop") %>%
arrange(desc(delay)) %>%
top_n(n = 10)
# A tibble: 10 x 4
manufacturer model engine delay
<chr> <chr> <chr> <dbl>
1 AIRBUS INDUSTRIE A330-223 Turbo-jet 219
2 BOEING 747-451 Turbo-jet 120
3 BOEING 757-351 Turbo-jet 72.5
4 GULFSTREAM AEROSPACE G-IV Turbo-fan 41.2
5 BOEING MD-90-30 Turbo-fan 40.9
6 BOEING 777-224 Turbo-fan 40.8
7 AIRBUS A319-115 Turbo-fan 33.5
8 AGUSTA SPA A109E Turbo-shaft 30.6
9 AIRBUS INDUSTRIE A340-313 Turbo-jet 29.8
10 BOEING 737-76N Turbo-fan 28.4윈도우 함수 사용하기
전후 시간대의 상황 이해하기
항공기가 아닌 공항의 이슈에 기인한 항공기의 출발 지연은 이후 다른 항공 스케줄에 영향을 줄 수 있습니다.
Hands-on 6
- 항공기의 출발 지연 비율이 가장 높은 날자를 추출하세요.
- 편성 노선 대비 출발 지연 노선의 비율 상위 10개 일자를 추출하세요.
- 상위 1개 일자의 전체 노선에 대해서 출발 지연시간인 dep_delay를 Bar Cart로 시각화 해 보세요.
- 윈도우 함수를 이용해서 바로 이전 편성보다 출발 지연시간이 큰 경우의 수가 많은 날자를 추출하세요.
lag() 함수는 이전 계열의 데이터를 참조할 수 있는 윈도우 함수입니다.- 상위 1개 일자의 전체 노선에 대해서 이전 시간 대비 지연 증감시간을 Bar Cart로 시각화 해 보세요.
힌트
- 출발 지연시간인 dep_delay이 0보다 큰 것이 몇 건인지 집계합니다.
- 순서로 일부 데이터를 가져오기 때문에 summarise() 함수에는 .groups = “drop”를 적용합니다.
- top_n() 함수를 사용합니다.
- time_hour 변수는 노선 스케줄의 일자와 시간까지 기록된 변수입니다. 이것을 조작해 보세요.
- ggplot2의 geom_bar() 함수와 geom_smooth() 함수를 사용합니다.
- 현재의 값에서 lag() 함수로 이전의 값을 가져와서 빼줍니다. dep_delay - lag(dep_delay)
- 출발 지연의 증감을 계산하기 전에 데이터를 시간의 순으로 정렬해야 합니다.
- 증감량이 0보다 크고, 현 시점의 출발지연 시간도 0보다 큰 건의 개수를 세야 합니다.
dplyr 솔루션
솔루션 1
hms 패키지도 Tidiverse 패키지군에 포함된 패키지입니다. 이 패키지는 시간 데이터를 조작하는 패키지입니다. as.hms() 함수로 문자열을 시간:분:초 포맷의 hms 데이터로 변환합니다.
# 1.1
top_delay <- flights %>%
group_by(month, day) %>%
summarise(cnt = n(),
cnt_delay = sum(dep_delay > 0, na.rm = TRUE),
rate_delay = cnt_delay / cnt, .groups = "drop") %>%
arrange(desc(rate_delay)) %>%
top_n(10)
top_delay
# A tibble: 10 x 5
month day cnt cnt_delay rate_delay
<int> <int> <int> <int> <dbl>
1 12 23 985 674 0.684
2 7 1 966 652 0.675
3 3 8 979 653 0.667
4 6 25 993 649 0.654
5 12 22 895 583 0.651
6 7 23 997 645 0.647
7 12 17 949 608 0.641
8 5 24 978 621 0.635
9 12 9 962 606 0.630
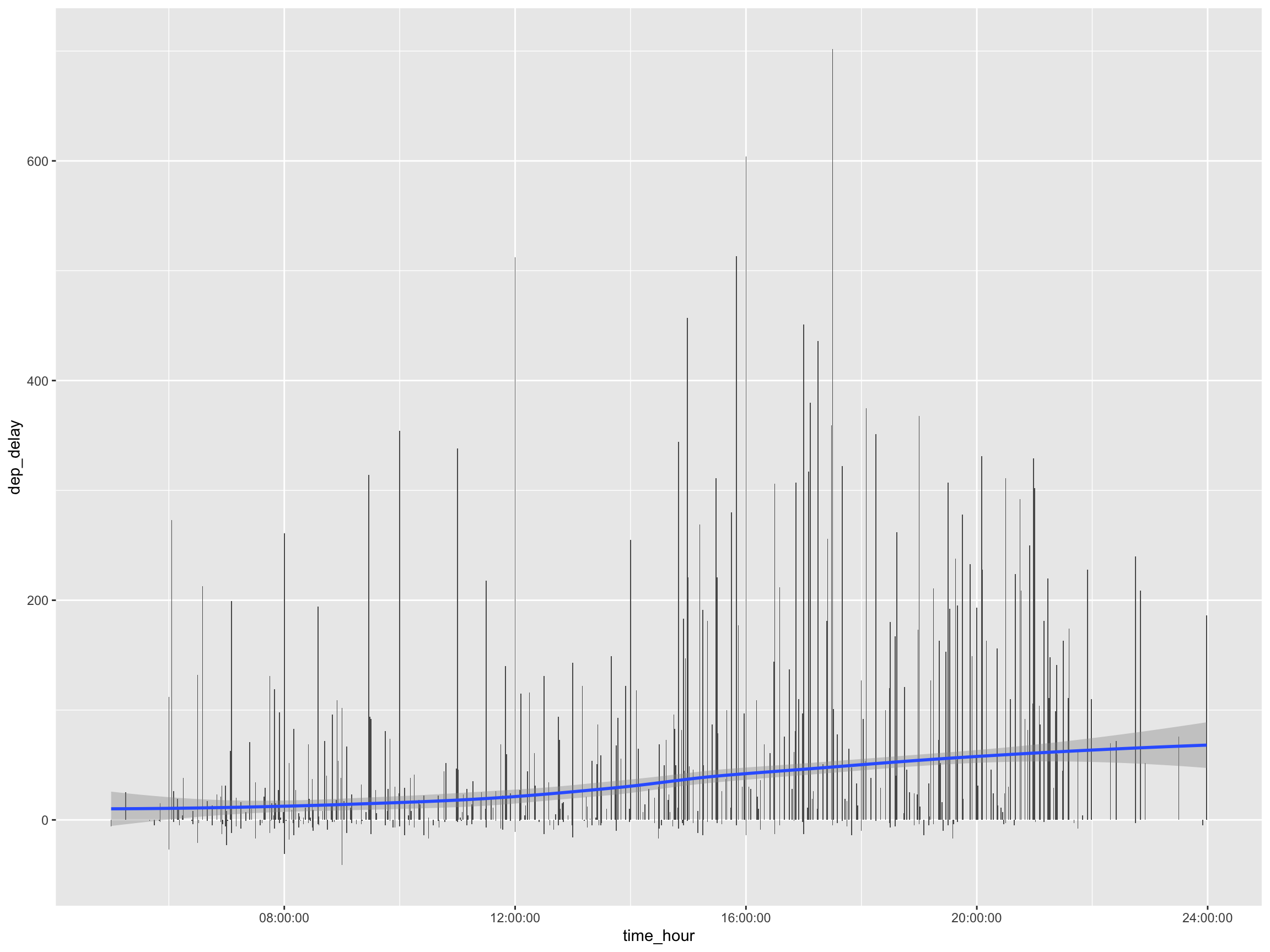
10 2 27 945 584 0.618# 1.2
flights %>%
arrange(time_hour, sched_dep_time) %>%
filter(month == top_delay$month[1] & day == top_delay$day[1]) %>%
mutate(sched_time = sprintf("%04d", sched_dep_time)) %>%
mutate(time_hour =
hms::as.hms(paste(substr(sched_time, 1, 2),
substr(sched_time, 3, 4), "00", sep = ":"))) %>%
select(time_hour, dep_delay) %>%
ggplot(aes(x = time_hour, y = dep_delay)) +
geom_bar(stat = "identity") +
geom_smooth()
솔루션 2
sched_dep_time 변수는 출발 스케줄을 분 단위까지 포함하고 있기 때문에 윈도우 함수를 사용하기 전에 이 변수 기준으로 오름차순으로 정렬해야 합니다.
# 2.1
top_increase <- flights %>%
group_by(month, day) %>%
arrange(sched_dep_time) %>%
mutate(delta_delay = dep_delay - lag(dep_delay)) %>%
summarise(cnt = n(),
increase_delay = sum(delta_delay > 0 & dep_delay > 0, na.rm = TRUE),
rate_increase = increase_delay / cnt, .groups = "drop") %>%
arrange(desc(rate_increase)) %>%
top_n(10)
top_increase
# A tibble: 10 x 5
month day cnt increase_delay rate_increase
<int> <int> <int> <int> <dbl>
1 12 23 985 513 0.521
2 6 25 993 505 0.509
3 7 1 966 490 0.507
4 12 22 895 453 0.506
5 5 24 978 492 0.503
6 12 18 956 479 0.501
7 12 21 811 404 0.498
8 7 23 997 490 0.491
9 12 9 962 468 0.486
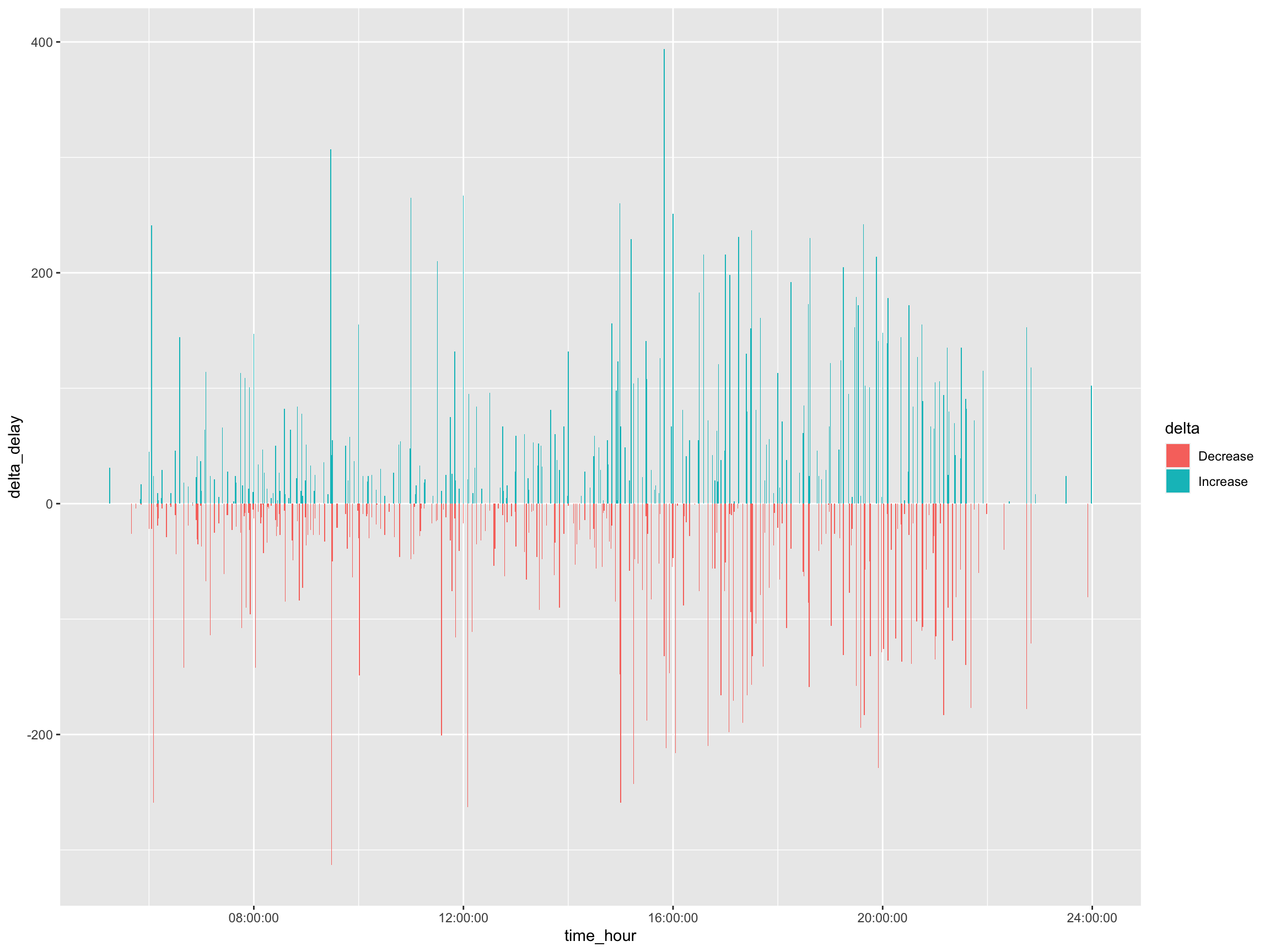
10 2 27 945 459 0.486flights %>%
filter(month == top_increase$month[1] & day == top_increase$day[1]) %>%
mutate(sched_time = sprintf("%04d", sched_dep_time)) %>%
mutate(time_hour =
hms::as.hms(paste(substr(sched_time, 1, 2),
substr(sched_time, 3, 4), "00", sep = ":"))) %>%
arrange(time_hour) %>%
mutate(delta_delay = dep_delay - lag(dep_delay)) %>%
mutate(delta = ifelse(delta_delay > 0, "Increase", "Decrease") %>%
as.factor()) %>%
ggplot(aes(x = time_hour, y = delta_delay, fill = delta)) +
geom_bar(stat = "identity")