개요
dlookr은 데이터 분석과정에서 데이터 품질진단, EDA 및 변수변환을 지원하는 패키지다. 이 패키지는 dplyr 패키지와 협업하여 데이터를 탐색하고 조작할 수있는 유연한 기능을 제공한다. 특히 자동화된 3종의 보고서는 데이터 품질진단, 탐색적 데이터분석(EDA), 데이터 변환을 수행하는데 훌륭한 가이드를 제공한다.
이번에 개선된 0.3.2 버전에서는 DBMS의 테이블로 존재하는 데이터의 진단과 EDA를 지원한다. 본 포스트는 DBMS의 테이블에 대한 품질진단과 EDA를 수행하는 방법을 제시한다.
dlookr 주요 기능
- 데이터 프레임이나 tbl_df의 품질을 진단
- 데이터 프레임이나 tbl_df의 EDA
- 데이터 프레임이나 tbl_df 변수변환을 수행하거나 파생변수를 생성
- 위 세가지 작업을 지원하는 자동화된 보고서 생성
0.3.2 버전의 추가 기능
- DBMS 테이블의 품질을 진단
- DBMS 테이블의 EDA
- 위 두가지 작업을 지원하는 자동화된 보고서 생성
dlookr 설치
현재 CRAN에는 dlookr 0.3.2 버전의 소스만 등록되어 있다. MS-Windows와 OS X의 binary는 며칠이 걸릴 것이다. 그러므로 github을 통해 설치하기 바란다.
GitHub에 등록된 vignettes이 없는 개발버전은 다음처럼 설치한다.:
devtools::install_github("choonghyunryu/dlookr")
혹은 GitHub에 등록된 vignettes을 포함한 개발버전은 다음처럼 설치한다.
install.packages(c("nycflights13", "ISLR", "DBI", "RSQLite"))
devtools::install_github("choonghyunryu/dlookr", build_vignettes = TRUE)
dlookr 사용 방법
dlookr에는 몇 가지 vignette 파일을 포함하고 있는데, 이 포스트는 이를 기초로 작성하였다.
제공되는 vignette는 다음과 같다.
- Data quality diagnosis
- Exploratory Data Analysis
- Data Transformation
browseVignettes(package = "dlookr")
여기서는 DBMS 테이블의 품질진단에 대한 내용만 다룬다. 좀 더 많은 기능의 dlookr 사용 방법은 vignette이나 https://choonghyunryu.github.io/ko/2018/05/dlookr-데이터진단-eda-데이터변환을-위한-패키지/를 참고하기 바란다.
DBMS의 테이블을 지원하는 함수들
DBMS 테이블 진단 및 EDA 기능은 DBMS side(DBMS 자원 사용)에서 SQL을 수행하는 In-Database 모드를 지원한다. 데이터의 크기가 큰 경우 In-Database 모드를 사용하는 것이 더 빠르다.
DBMS의 SQL은 이상치를 구하거나 샘플링 기반 알고리즘을 구현하기가 어렵다. 따라서 일부 기능은 In-Database 모드를 아직 지원하지 않는다. 이 경우 테이블 데이터를 R로 가져와 계산하는 In-Memory 모드로 수행됩니다. 이 경우 데이터 크기가 클 경우 실행 속도가 느려질 수 있다. collect_size 인수를 지원하는데, 이 인수를 사용하면 지정된 수의 샘플 데이터를 R로 가져올 수 있다.
DBMS의 테이블 품질진단
데이터 준비
dlookr 패키지로 EDA를 수행하는 기초적인 사용 방법을 설명하기 위해서 Carseats를 사용한다. ISLR 패키지의 Carseats는 400개의 매장에서 아동용 카시트를 판매하는 시뮬레이션 데이터다. 이 데이터는 판매량을 예측하는 목적으로 생성한 데이터 프레임이다.
'data.frame': 400 obs. of 11 variables:
$ Sales : num 9.5 11.22 10.06 7.4 4.15 ...
$ CompPrice : num 138 111 113 117 141 124 115 136 132 132 ...
$ Income : num 73 48 35 100 64 113 105 81 110 113 ...
$ Advertising: num 11 16 10 4 3 13 0 15 0 0 ...
$ Population : num 276 260 269 466 340 501 45 425 108 131 ...
$ Price : num 120 83 80 97 128 72 108 120 124 124 ...
$ ShelveLoc : Factor w/ 3 levels "Bad","Good","Medium": 1 2 3 3 1 1 3 2 3 3 ...
$ Age : num 42 65 59 55 38 78 71 67 76 76 ...
$ Education : num 17 10 12 14 13 16 15 10 10 17 ...
$ Urban : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 2 2 1 1 ...
$ US : Factor w/ 2 levels "No","Yes": 2 2 2 2 1 2 1 2 1 2 ...개별 변수들의 의미는 다음과 같다. (ISLR::Carseats Man page 참고)
- Sales
- 지역의 단위 판매량 (단위: 천개)
- CompPrice
- 지역의 경쟁 업체가 부과하는 가격
- Income
- 지역 공동체 수입 수준 (단위: 천달러)
- Advertising
- 회사의 지역에 대한 광고 예산 (단위: 천달러)
- Population
- 지역의 인구 규모 (단위: 천명)
- Price
- 지역의 자동차 좌석 요금
- ShelveLoc
- 각 사이트에서 자동차 좌석의 선반 위치의 품질을 나타내는 수준. Bad, Good, Medium.
- Age
- 각 지역의 평균 연령
- Education
- 각 지역의 교육 수준
- Urban
- 점포의 도시 또는 농촌 소재 여부. Yes는 도시, No는 농촌.
- US
- 점포의 미국 소재 여부. Yes는 미국 소재, No는 미국 외 소재.
데이터 분석을 수행할 때, 결측치가 포함된 데이터를 자주 접한다. 그러나 Carseats는 결측치가 없은 완전한 데이터다. 그래서 다음과 같이 결측치를 생성하였다. 그리고 carseats라는 이름의 데이터 프레임 객체를 생성한다.
DBMS의 테이블 생성
carseats 데이터 프레임을 SQLite DBMS에 복사하고 TB_CARSEATS라는 테이블을 만든다. Mysql / MariaDB, PostgreSQL, Oracle DBMS 등의 사용자 환경에 적용할 수 있다.
if (!require(DBI)) install.packages('DBI')
if (!require(RSQLite)) install.packages('RSQLite')
library(dplyr)
# connect DBMS
con_sqlite <- DBI::dbConnect(RSQLite::SQLite(), ":memory:")
# copy carseats to the DBMS with a table named TB_CARSEATS
copy_to(con_sqlite, carseats, name = "TB_CARSEATS", overwrite = TRUE)
diagnose()을 이용한 DBMS에서 테이블의 데이터 품질진단
다음의 diagnose()는 SQLite DBMS에 존재하는 TB_CARSEATS 테이블의 컬럼을 진단한다.
library(dlookr)
# Diagnosis of all columns, and In-Database mode
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose()
# A tibble: 11 x 6
variables types missing_count missing_percent unique_count
<chr> <chr> <dbl> <dbl> <int>
1 Sales double 0 0 336
2 CompPrice double 0 0 73
3 Income double 20 5 99
4 Advertising double 0 0 28
5 Population double 0 0 275
6 Price double 0 0 101
7 ShelveLoc character 0 0 3
8 Age double 0 0 56
9 Education double 0 0 9
10 Urban character 10 2.5 3
11 US character 0 0 2
# … with 1 more variable: unique_rate <dbl># Select columns, and In-memory mode
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose(Sales, Income, in_database = FALSE)
# A tibble: 2 x 6
variables types missing_count missing_percent unique_count
<chr> <chr> <int> <dbl> <int>
1 Sales numeric 0 0 336
2 Income numeric 20 5 99
# … with 1 more variable: unique_rate <dbl># Positions values select columns, and In-memory mode
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose(1, 3, 8, in_database = FALSE)
# A tibble: 3 x 6
variables types missing_count missing_percent unique_count
<chr> <chr> <int> <dbl> <int>
1 Sales numeric 0 0 336
2 Income numeric 20 5 99
3 Age numeric 0 0 56
# … with 1 more variable: unique_rate <dbl># Positions values select columns, and In-memory mode and collect size is 200
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose(-8, -9, -10, in_database = FALSE, collect_size = 200)
# A tibble: 8 x 6
variables types missing_count missing_percent unique_count
<chr> <chr> <int> <dbl> <int>
1 Sales numeric 0 0 182
2 CompPrice numeric 0 0 65
3 Income numeric 9 4.5 83
4 Advertising numeric 0 0 23
5 Population numeric 0 0 162
6 Price numeric 0 0 82
7 ShelveLoc character 0 0 3
8 US character 0 0 2
# … with 1 more variable: unique_rate <dbl>diagnose()가 반환하는 tbl_df 객체의 변수는 다음과 같다.
variables: 변수명types: 변수의 데이터 유형missing_count: 결측치 수missing_percent: 결측치의 백분율unique_count: 유일값의 수unique_rate: 유일값의 비율. unique_count / 관측치의 수
dplyr을 이용해서 결측치를 포함한 변수를 결측치의 비중별로 정렬할 수 있다.:
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose() %>%
select(-unique_count, -unique_rate) %>%
filter(missing_count > 0) %>%
arrange(desc(missing_count))
# A tibble: 2 x 4
variables types missing_count missing_percent
<chr> <chr> <dbl> <dbl>
1 Income double 20 5
2 Urban character 10 2.5diagnose_numeric()을 이용한 테이블의 수치형 컬럼의 상세 진단
diagnose_numeric()은 데이터 프레임의 수치형(연속형과 이산형) 변수를 진단한다. 사용 방법은 diagnose()와 동일하나 더 많은 진단 정보를 반환한다. 그런데 두 번째 및 후속 인수 목록에 수치형이 아닌 변수를 지정하면 해당 변수는 자동적으로 무시한다.
diagnose_numeric()이 반환하는 tbl_df 객체의 변수는 다음과 같다.
min: 최소값Q1: 1/4분위수, 25백분위수mean: 산술평균median: 중위수, 50백분위수Q3: 3/4분위수, 75백분위수max: 최대값zero: 0의 값을 갖는 관측치의 개수minus: 음수를 갖는 관측치의 개수outlier: 이상치의 개수
zero, minus, outlier는 데이터의 무결성을 진단하는데 유용한 측도다. 예를 들어 어떤 경우의 수치 데이터는 0이나 음수를 가질 수 없는 경우가 있기 때문이다. ’직원의 급여’라는 가상의 수치형 변수는 음수나 0을 가질 수 없기 때문에 데이터 진단 과정에서 0이나 음수의 포함 여부를 살펴보아야 한다.
다음처럼 diagnose_numeric()는 TB_CARSEATS 테이블의 모든 수치형 컬럼을 진단할 수 있다.:
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_numeric
# A tibble: 8 x 10
variables min Q1 mean median Q3 max zero minus
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int>
1 Sales 0 5.39 7.50 7.49 9.32 16.3 1 0
2 CompPrice 77 115 125. 125 135 175 0 0
3 Income 21 44 69.3 69 92 120 0 0
4 Advertising 0 0 6.64 5 12 29 144 0
5 Population 10 139 265. 272 398. 509 0 0
6 Price 24 100 116. 117 131 191 0 0
7 Age 25 39.8 53.3 54.5 66 80 0 0
8 Education 10 12 13.9 14 16 18 0 0
# … with 1 more variable: outlier <int>수치형 변수가 논리적으로 음수나 0의 값을 가질 수 없을 경우에, filter()로 논리적으로 부합하지 않은 변수를 쉽게 찾아낸다.:
# A tibble: 2 x 10
variables min Q1 mean median Q3 max zero minus outlier
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <int> <int>
1 Sales 0 5.39 7.50 7.49 9.32 16.3 1 0 2
2 Advertising 0 0 6.64 5 12 29 144 0 0diagnose_category()을 이용한 테이블의 문자형 컬럼의 상세 진단
diagnose_category()은 데이터 프레임의 범주형(factor, ordered, character) 변수를 진단한다. 사용 방법은 diagnose()와 유사하나 더 많은 진단 정보를 반환한다. 그런데 두 번째 및 후속 인수 목록에 범주형이 아닌 변수를 지정하면 해당 변수는 자동적으로 무시한다. top 인수는 변수별로 반환할 수준(levels)의 개수를 지정한다. 기본값은 10으로 상위 top 10의 수준을 반환한다. 물론 수준의 개수가 10개 미만일 경우에는 모든 수준을 반환한다.
diagnose_category()이 반환하는 tbl_df 객체의 변수는 다음과 같다.
variables: 변수의 이름levels: 수준의 이름N: 관측치의 수freq: 수준별 도수(frequency)ratio: 수준별 상대도수(백분율 표현)rank: 레벨별 도수 크기의 순위
다음처럼 diagnose_category()는 flights의 모든 범주형 변수를 진단할 수 있다.:
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_category
# A tibble: 8 x 6
variables levels N freq ratio rank
<chr> <chr> <int> <int> <dbl> <int>
1 ShelveLoc Medium 400 219 54.8 1
2 ShelveLoc Bad 400 96 24 2
3 ShelveLoc Good 400 85 21.2 3
4 Urban Yes 400 275 68.8 1
5 Urban No 400 115 28.7 2
6 Urban <NA> 400 10 2.5 3
7 US Yes 400 258 64.5 1
8 US No 400 142 35.5 2dplyr 패키지의 filter()와 협업하여 결측치가 top 10에 포함된 사례를 조회한 결과에서 Urban 변수가 10건의 결측치로 top 3에 랭크된 것을 알 수 있다.:
# A tibble: 1 x 6
variables levels N freq ratio rank
<chr> <chr> <int> <int> <dbl> <int>
1 Urban <NA> 400 10 2.5 3다음은 수준이 차지하는 비중이 5% 이하인 목록을 반환한다.:
# A tibble: 1 x 6
variables levels N freq ratio rank
<chr> <chr> <int> <int> <dbl> <int>
1 Urban <NA> 400 10 2.5 3diagnose_outlier()를 이용한 테이블의 수치형 컬럼의 이상치 진단
diagnose_outlier()은 데이터 프레임의 수치형(연속형과 이산형) 변수의 이상치(outliers)를 진단한다. 사용 방법은 diagnose()와 동일하다.
diagnose_outlier()이 반환하는 tbl_df 객체의 변수는 다음과 같다.
outliers_cnt: 이상치의 개수outliers_ratio: 이상치의 비율(백분율)outliers_mean: 이상치들의 산술평균with_mean: 이상치를 포함한 전체 관측치의 평균without_mean: 이상치를 제거한 관측치의 산술평균
다음처럼 diagnose_outlier()는 flights의 모든 수치형 변수의 이상치를 진단할 수 있다.:
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_outlier
# A tibble: 8 x 6
variables outliers_cnt outliers_ratio outliers_mean with_mean
<chr> <int> <dbl> <dbl> <dbl>
1 Sales 2 0.5 16.0 7.50
2 CompPrice 2 0.5 126 125.
3 Income 0 0 NaN 69.3
4 Advertising 0 0 NaN 6.64
5 Population 0 0 NaN 265.
6 Price 5 1.25 100. 116.
7 Age 0 0 NaN 53.3
8 Education 0 0 NaN 13.9
# … with 1 more variable: without_mean <dbl>plot_outlier()를 이용한 이상치 진단 시각화
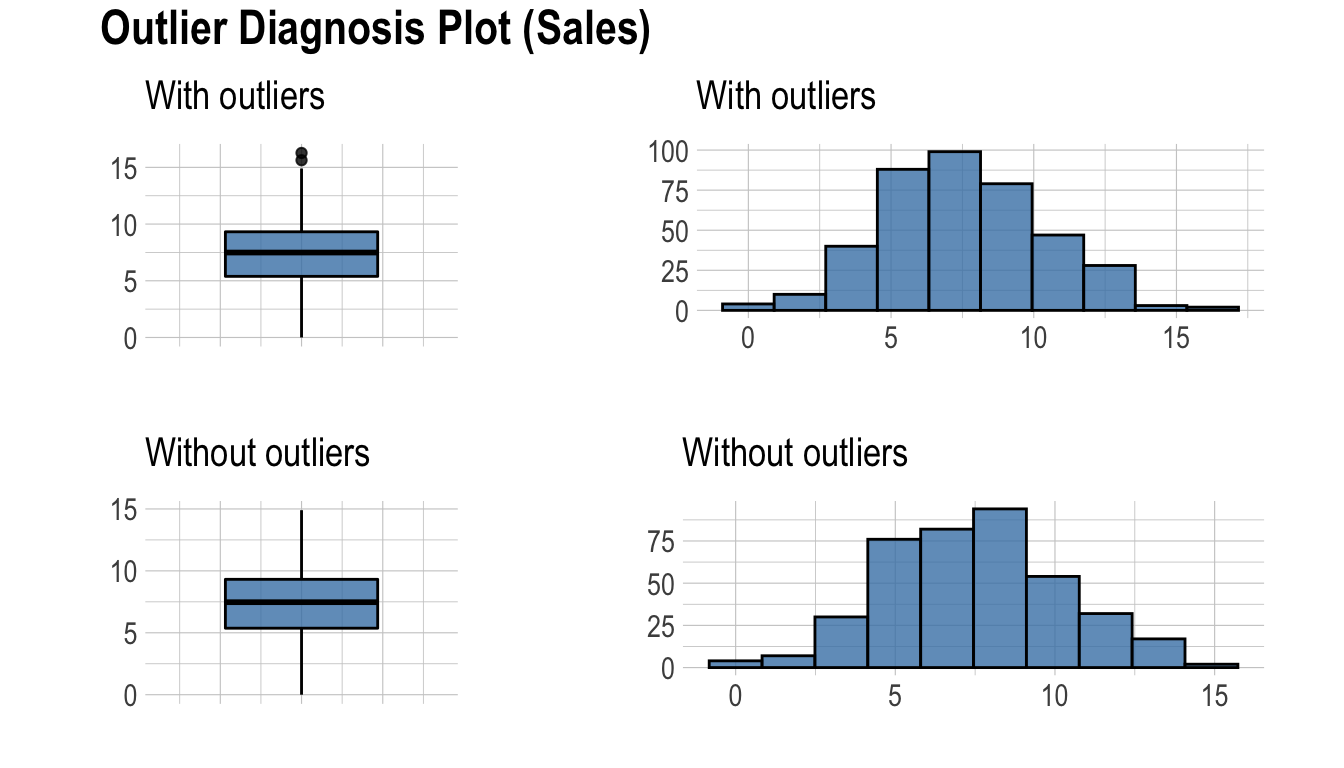
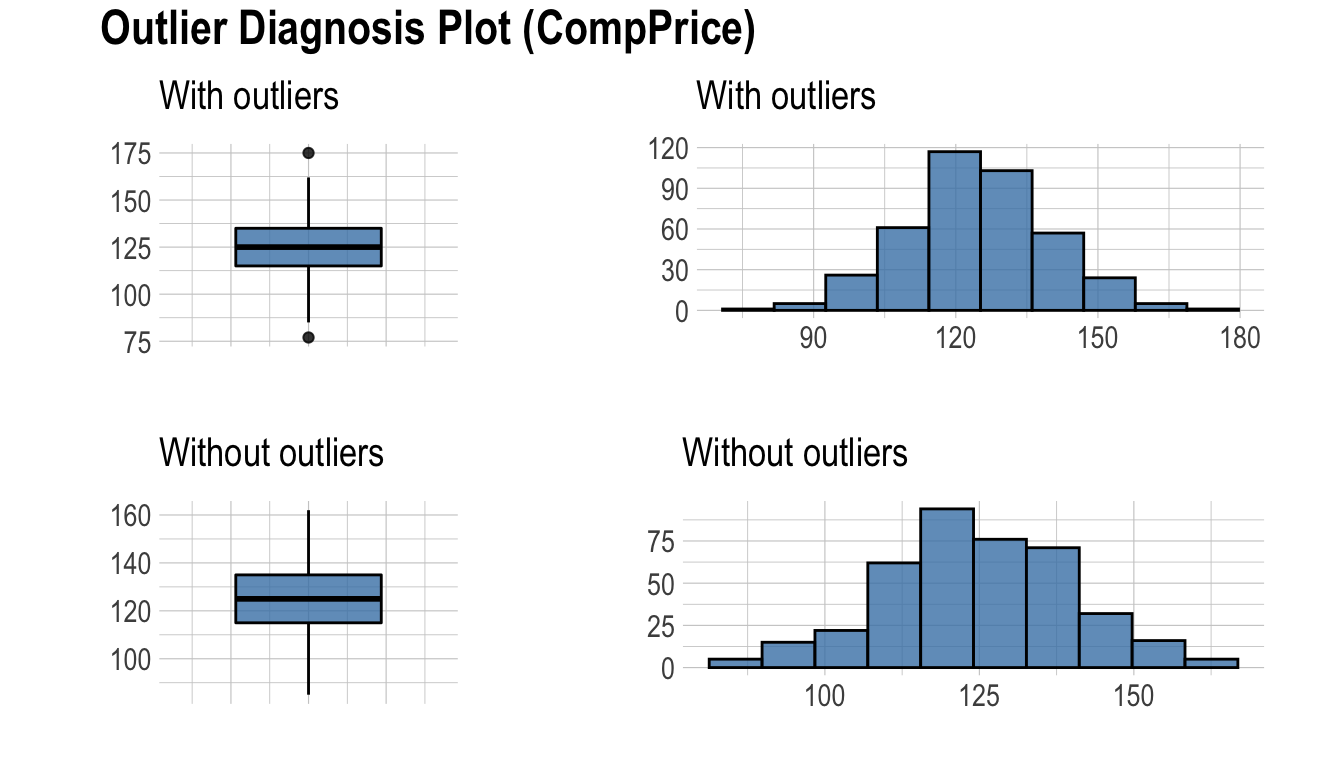
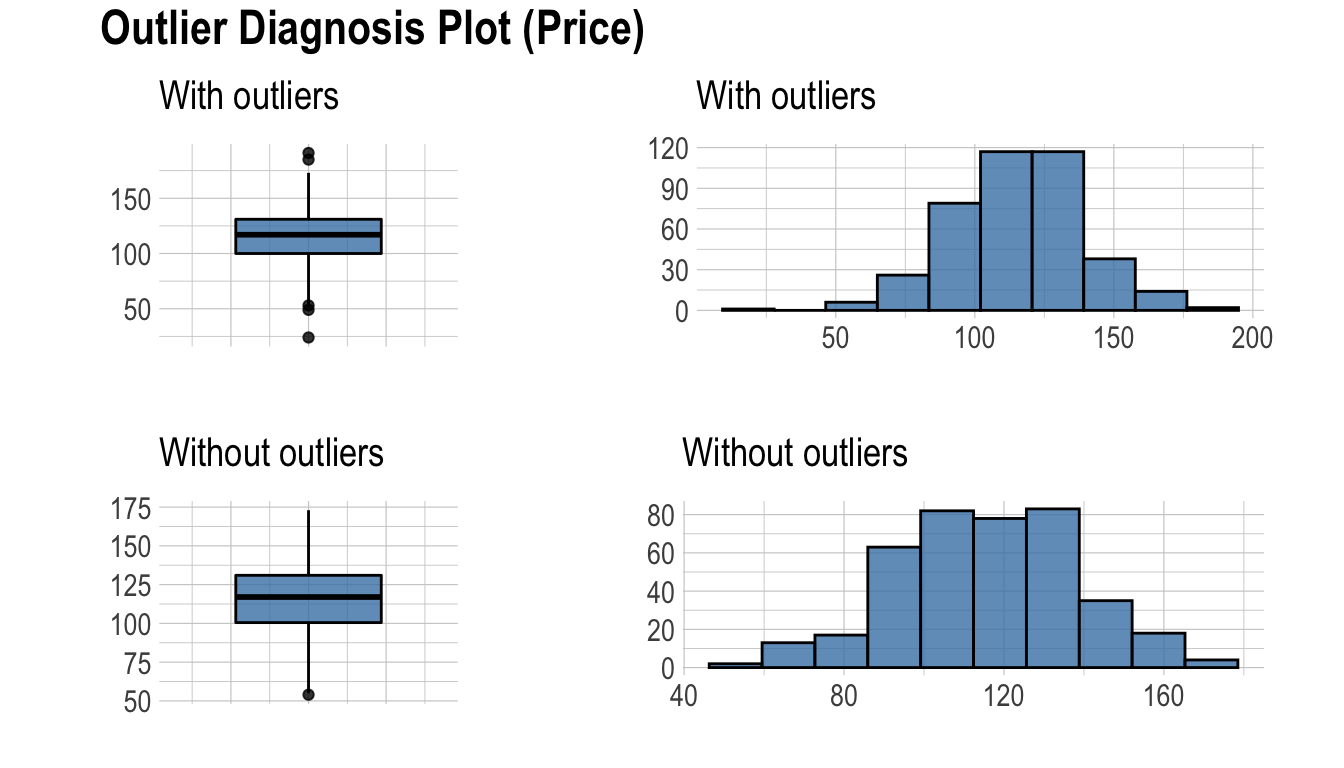
plot_outlier()은 테이블의 수치형(연속형과 이산형) 컬럼의 이상치(outliers)를 시각화한다. 사용 방법은 diagnose()와 동일하다.
plot_outlier()이 시각화하는 플롯은 다음을 포함한다.
- 이상치를 포함한 박스플롯
- 이상치를 제거한 박스플롯
- 이상치를 포함한 히스토그램
- 이상치를 제거한 히스토그램
다음은 diagnose_outlier()와 plot_outlier(), dplyr 패키지의 함수를 사용하여 이상치의 비율이 0.5% 이상인 모든 수치형 변수의 이상치를 시각화 한다.
con_sqlite %>%
tbl("TB_CARSEATS") %>%
plot_outlier(con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_outlier() %>%
filter(outliers_ratio >= 0.5) %>%
select(variables) %>%
pull())
diagnose_report()를 이용한 진단 보고서 작성
diagnose_report()는 데이터 프레임이나 데이터 프레임을 상속받은 객체(tbl_df, tbl 등)의 모든 변수들에 대해서 데이터 진단을 수행한다. 그리고 dlookr 0.3.2 버전에서는 DBMS의 테이블에 대한 데이터 진단도 수행한다.
diagnose_report()는 진단 보고서를 다음과 같은 두 개의 형태로 작성한다.
- Latex에 기반한 pdf 파일
- html 파일
보고서의 목차는 다음과 같다.
- 데이터 진단
- 데이터 품질 총괄
- 전체변수 품질현황 목록
- 결측치 진단
- 유일값 진단(문자형과 범주형)
- 유일값 진단(수치형)
- 데이터 품질 상세
- 범주형 변수 품질 현황
- 수치형 변수 품질 현황
- 수치변수 품질현황 (zero)
- 수치변수 품질현황 (minus)
- 데이터 품질 총괄
- 이상치 진단
- 데이터 품질 총괄
- 수치변수의 이상치 진단
- 이상치 상세 진단
- 데이터 품질 총괄
다음은 tbl_dbi 클래스 객체로 매핑된 TB_CARSEATS 데이블의 품질진단 리포트를 작성한다. 파일 형식은 pdf이며, 파일이름은 DataDiagnosis_Report.pdf다.
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_report()
다음은 DataDiagnosis_Report.html라는 이름의 html 형식의 보고서를 생성한다.
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_report(output_format = "html")
다음은 Diagn.html라는 이름의 html 형식의 보고서를 생성한다.
con_sqlite %>%
tbl("TB_CARSEATS") %>%
diagnose_report(output_format = "html", output_file = "Diagn.html")
데이터 진단 보고서는 데이터 진단 과정에 도움을 주기 위한 자동화 보고서다. 보고서 결과를 참고하여 데이터 보완이나 재획득을 판단한다.
데이터 진단 리포트 내용
pdf 파일의 내용
- 보고서의 표지는 다음 그림 1과 같다.

Figure 1: 데이터진단 보고서 표지
- 보고서의 차례는 다음 그림 2와 같다.

Figure 2: 데이터진단 보고서 차례
- 대부분의 정보는 보고서에서 표로 표현된다. 표의 예시는 다음 그림 3과 같다.
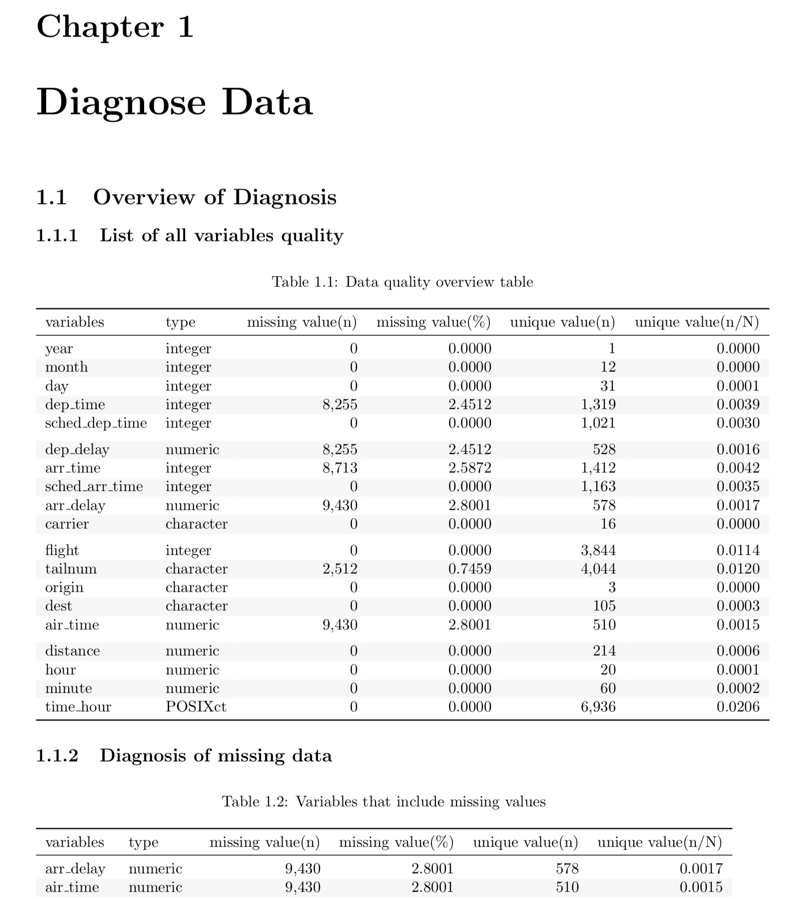
Figure 3: 데이터진단 보고서 도표 예시
- 데이터진단 보고서에서 이상치 진단 내용은 시각화 결과를 포함한다. 그 결과는 다음 그림 4와 같다.
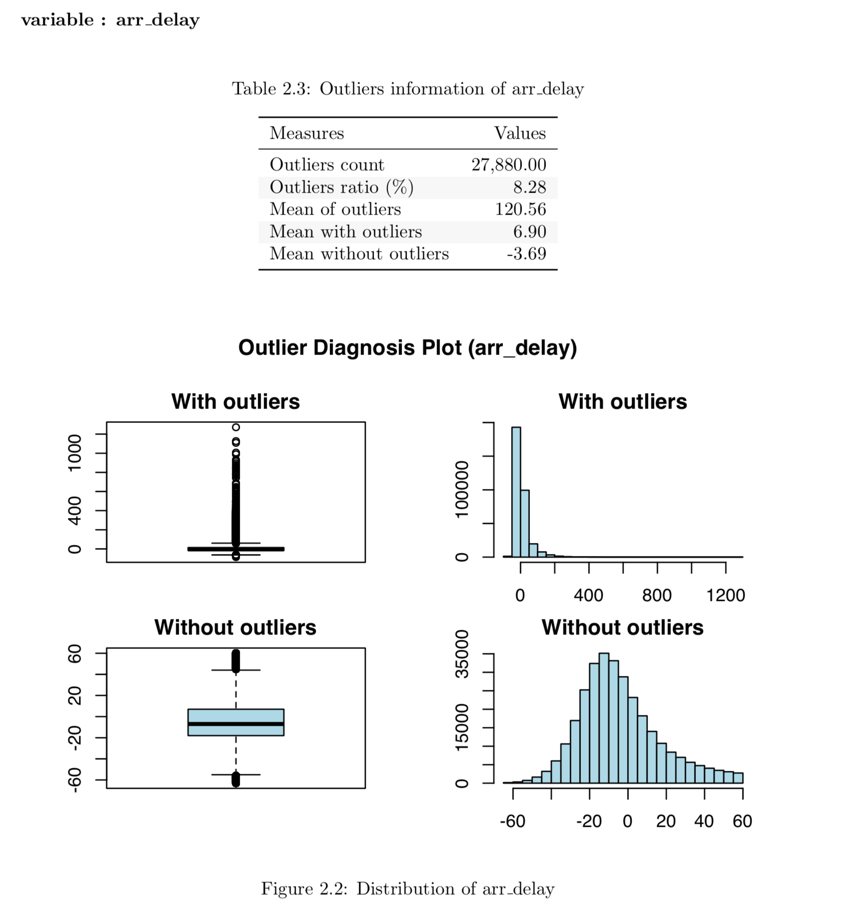
Figure 4: 데이터진단 보고서 이상치 진단 내용
html 파일의 내용
- 보고서의 타이틀과 목차는 다음 그림 5와 같다.

Figure 5: 데이터진단 보고서 타이틀과 목차
- 대부분의 정보는 보고서에서 표로 표현된다. html 파일에서 표의 예시는 다음 그림 6과 같다.
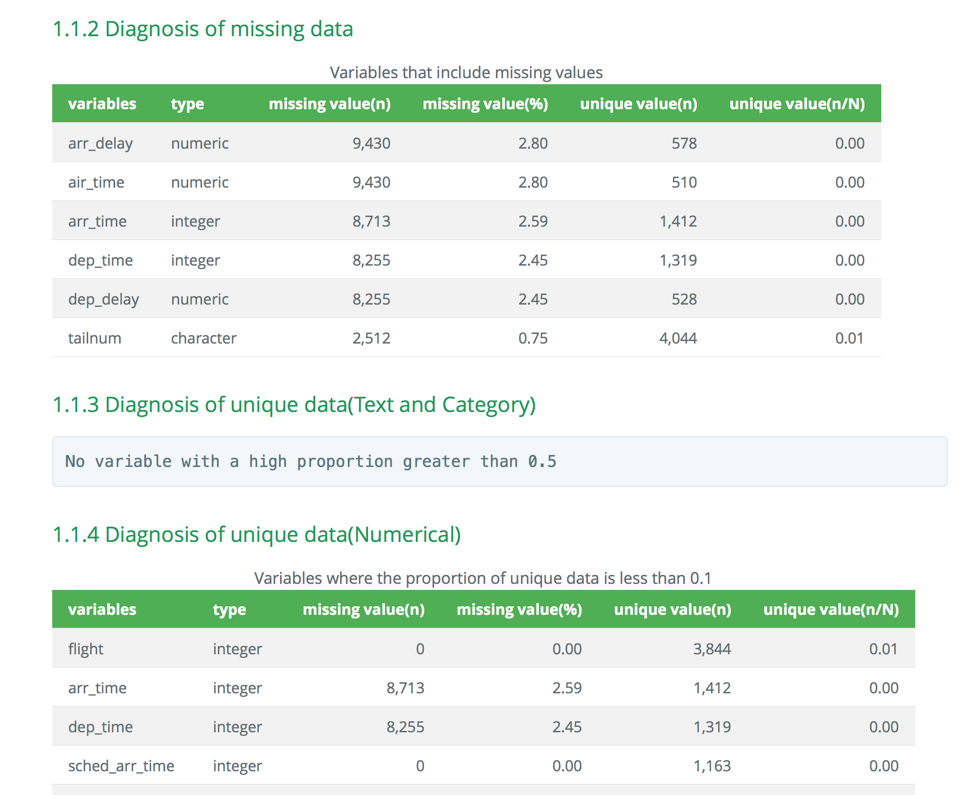
Figure 6: 데이터진단 보고서 도표 예시 (웹)
- 데이터진단 보고서에서 이상치 진단 내용은 시각화 결과를 포함한다. html 파일의 결과는 다음 그림 7과 같다.
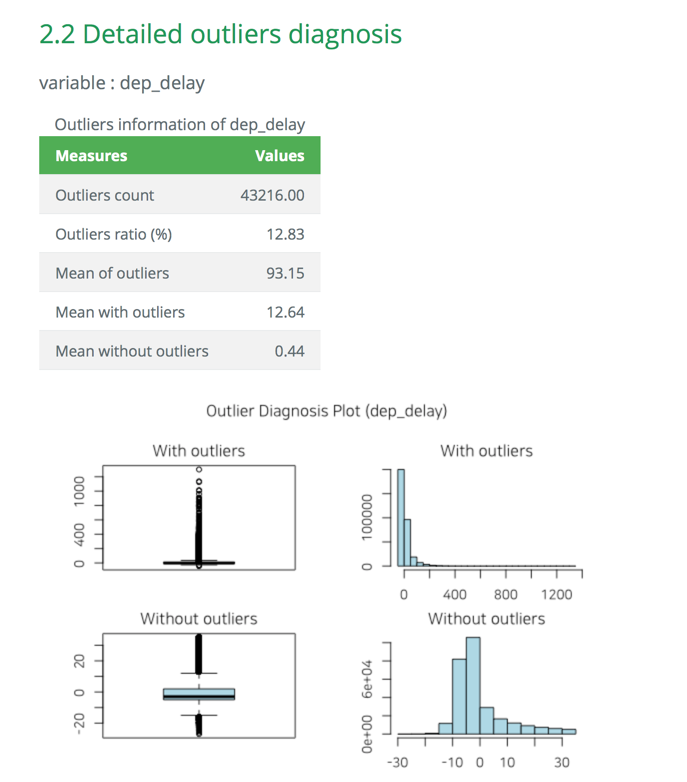
Figure 7: 데이터진단 보고서 이상치 진단 내용 (웹)