Overview
Binary classification modeling with alookr.
Features:
- Clean and split data sets to train and test.
- Create several representative models.
- Evaluate the performance of the model to select the best model.
- Support the entire process of developing a binary classification model.
The name alookr comes from looking at the analytics process in the data analysis process.
Install alookr
The released version is available on CRAN. but not yet.
install.packages("alookr")
Or you can get the development version without vignettes from GitHub:
devtools::install_github("choonghyunryu/alookr")
Or you can get the development version with vignettes from GitHub:
install.packages(c("ISLR", "spelling", "mlbench"))
devtools::install_github("choonghyunryu/alookr", build_vignettes = TRUE)
Usage
alookr includes several vignette files, which we use throughout the documentation.
Provided vignettes is as follows.
- Cleansing the dataset
- Split the data into a train set and a test set
- Modeling and Evaluate, Predict
browseVignettes(package = "alookr")
Cleansing the dataset
Data: create example dataset
To illustrate basic use of the alookr package, create the data_exam with sample function. The data_exam dataset include 5 variables.
variables are as follows.:
id: characteryear: charactercount: numericalpha: characterflag: character
# create sample dataset
set.seed(123L)
id <- sapply(1:1000, function(x)
paste(c(sample(letters, 5), x), collapse = ""))
year <- "2018"
set.seed(123L)
count <- sample(1:10, size = 1000, replace = TRUE)
set.seed(123L)
alpha <- sample(letters, size = 1000, replace = TRUE)
set.seed(123L)
flag <- sample(c("Y", "N"), size = 1000, prob = c(0.1, 0.9), replace = TRUE)
data_exam <- data.frame(id, year, count, alpha, flag, stringsAsFactors = FALSE)
# structure of dataset
str(data_exam)
'data.frame': 1000 obs. of 5 variables:
$ id : chr "osncj1" "rvket2" "nvesi3" "chgji4" ...
$ year : chr "2018" "2018" "2018" "2018" ...
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: chr "o" "s" "n" "c" ...
$ flag : chr "N" "N" "N" "N" ...# summary of dataset
summary(data_exam)
id year count
Length:1000 Length:1000 Min. : 1.000
Class :character Class :character 1st Qu.: 3.000
Mode :character Mode :character Median : 6.000
Mean : 5.698
3rd Qu.: 8.000
Max. :10.000
alpha flag
Length:1000 Length:1000
Class :character Class :character
Mode :character Mode :character
Clean dataset
cleanse() cleans up the dataset before fitting the classification model.
The function of cleanse() is as follows.:
- remove variables whose unique value is one
- remove variables with high unique rate
- converts character variables to factor
- remove variables with missing value
Cleanse dataset with cleanse()
For example, we can cleanse all variables in data_exam:
── Checking unique value ─────────────────────────── unique value is one ──
• year
── Checking unique rate ─────────────────────────────── high unique rate ──
• id = 1000(1)
── Checking character variables ─────────────────────── categorical data ──
• alpha
• flag# structure of cleansing dataset
str(newDat)
'data.frame': 1000 obs. of 3 variables:
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: Factor w/ 26 levels "a","b","c","d",..: 15 19 14 3 10 18 22 11 5 20 ...
$ flag : Factor w/ 2 levels "N","Y": 1 1 1 1 2 1 1 1 1 1 ...remove variables whose unique value is one: The year variable has only one value, “2018”. Not needed when fitting the model. So it was removed.remove variables with high unique rate: If the number of levels of categorical data is very large, it is not suitable for classification model. In this case, it is highly likely to be an identifier of the data. So, remove the categorical (or character) variable with a high value of the unique rate defined as “number of levels / number of observations”.- The unique rate of the id variable with the number of levels of 1000 is 1. This variable is the object of the removal by identifier.
- The unique rate of the alpha variable is 0.026 and this variable is also removed.
converts character variables to factor: The character type flag variable is converted to a factor type.
For example, we can not remove the categorical data that is removed by changing the threshold of the unique rate:
# cleansing dataset
newDat <- cleanse(data_exam, uniq_thres = 0.03)
── Checking unique value ─────────────────────────── unique value is one ──
• year
── Checking unique rate ─────────────────────────────── high unique rate ──
• id = 1000(1)
── Checking character variables ─────────────────────── categorical data ──
• alpha
• flag# structure of cleansing dataset
str(newDat)
'data.frame': 1000 obs. of 3 variables:
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: Factor w/ 26 levels "a","b","c","d",..: 15 19 14 3 10 18 22 11 5 20 ...
$ flag : Factor w/ 2 levels "N","Y": 1 1 1 1 2 1 1 1 1 1 ...The alpha variable was not removed.
If you do not want to apply a unique rate, you can set the value of the uniq argument to FALSE.:
# cleansing dataset
newDat <- cleanse(data_exam, uniq = FALSE)
── Checking character variables ─────────────────────── categorical data ──
• id
• year
• alpha
• flag# structure of cleansing dataset
str(newDat)
'data.frame': 1000 obs. of 5 variables:
$ id : Factor w/ 1000 levels "ablnc282","abqym54",..: 594 715 558 94 727 270 499 882 930 515 ...
$ year : Factor w/ 1 level "2018": 1 1 1 1 1 1 1 1 1 1 ...
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: Factor w/ 26 levels "a","b","c","d",..: 15 19 14 3 10 18 22 11 5 20 ...
$ flag : Factor w/ 2 levels "N","Y": 1 1 1 1 2 1 1 1 1 1 ...If you do not want to force type conversion of a character variable to factor, you can set the value of the char argument to FALSE.:
# cleansing dataset
newDat <- cleanse(data_exam, char = FALSE)
── Checking unique value ─────────────────────────── unique value is one ──
• year
── Checking unique rate ─────────────────────────────── high unique rate ──
• id = 1000(1)# structure of cleansing dataset
str(newDat)
'data.frame': 1000 obs. of 3 variables:
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: chr "o" "s" "n" "c" ...
$ flag : chr "N" "N" "N" "N" ...If you want to remove a variable that contains missing values, specify the value of the missing argument as TRUE. The following example removes the flag variable that contains the missing value.
data_exam$flag[1] <- NA
# cleansing dataset
newDat <- cleanse(data_exam, missing = TRUE)
── Checking missing value ────────────────────────────────── included NA ──
• flag
── Checking unique value ─────────────────────────── unique value is one ──
• year
── Checking unique rate ─────────────────────────────── high unique rate ──
• id = 1000(1)
── Checking character variables ─────────────────────── categorical data ──
• alpha# structure of cleansing dataset
str(newDat)
'data.frame': 1000 obs. of 2 variables:
$ count: int 3 3 10 2 6 5 4 6 9 10 ...
$ alpha: Factor w/ 26 levels "a","b","c","d",..: 15 19 14 3 10 18 22 11 5 20 ...Diagnosis and removal of highly correlated variables
In the linear model, there is a multicollinearity if there is a strong correlation between independent variables. So it is better to remove one variable from a pair of variables where the correlation exists.
Even if it is not a linear model, removing one variable from a strongly correlated pair of variables can also reduce the overhead of the operation. It is also easy to interpret the model.
Cleanse dataset with treatment_corr()
treatment_corr() diagnose pairs of highly correlated variables or remove on of them.
treatment_corr() calculates correlation coefficient of pearson for numerical variable, and correlation coefficient of spearman for categorical variable.
For example, we can diagnosis and removal of highly correlated variables:
# numerical variable
x1 <- 1:100
set.seed(12L)
x2 <- sample(1:3, size = 100, replace = TRUE) * x1 + rnorm(1)
set.seed(1234L)
x3 <- sample(1:2, size = 100, replace = TRUE) * x1 + rnorm(1)
# categorical variable
x4 <- factor(rep(letters[1:20], time = 5))
set.seed(100L)
x5 <- factor(rep(letters[1:20 + sample(1:6, size = 20, replace = TRUE)], time = 5))
set.seed(200L)
x6 <- factor(rep(letters[1:20 + sample(1:3, size = 20, replace = TRUE)], time = 5))
set.seed(300L)
x7 <- factor(sample(letters[1:5], size = 100, replace = TRUE))
exam <- data.frame(x1, x2, x3, x4, x5, x6, x7)
str(exam)
'data.frame': 100 obs. of 7 variables:
$ x1: int 1 2 3 4 5 6 7 8 9 10 ...
$ x2: num 2.55 4.55 9.55 12.55 10.55 ...
$ x3: num 0.194 2.194 4.194 6.194 3.194 ...
$ x4: Factor w/ 20 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
$ x5: Factor w/ 13 levels "c","e","f","g",..: 1 5 3 2 4 7 6 8 9 8 ...
$ x6: Factor w/ 15 levels "c","d","f","g",..: 1 2 3 4 3 5 6 7 8 9 ...
$ x7: Factor w/ 5 levels "a","b","c","d",..: 2 2 1 4 5 1 4 3 1 5 ...head(exam)
x1 x2 x3 x4 x5 x6 x7
1 1 2.554297 0.1939687 a c c b
2 2 4.554297 2.1939687 b h d b
3 3 9.554297 4.1939687 c f f a
4 4 12.554297 6.1939687 d e g d
5 5 10.554297 3.1939687 e g f e
6 6 6.554297 10.1939687 f l h a# default case
exam_01 <- treatment_corr(exam)
head(exam_01)
x2 x3 x6 x7
1 2.554297 0.1939687 c b
2 4.554297 2.1939687 d b
3 9.554297 4.1939687 f a
4 12.554297 6.1939687 g d
5 10.554297 3.1939687 f e
6 6.554297 10.1939687 h a# not removing variables
treatment_corr(exam, treat = FALSE)
# Set a threshold to detecting variables when correlation greater then 0.9
treatment_corr(exam, corr_thres = 0.9, treat = FALSE)
# not verbose mode
exam_02 <- treatment_corr(exam, verbose = FALSE)
head(exam_02)
x2 x3 x6 x7
1 2.554297 0.1939687 c b
2 4.554297 2.1939687 d b
3 9.554297 4.1939687 f a
4 12.554297 6.1939687 g d
5 10.554297 3.1939687 f e
6 6.554297 10.1939687 h aremove variables whose strong correlation: x1, x4, x5 are removed.
Split the data into a train set and a test set
Data: Credit Card Default Data
Default of ISLR package is a simulated data set containing information on ten thousand customers. The aim here is to predict which customers will default on their credit card debt.
A data frame with 10000 observations on the following 4 variables.:
default: factor. A factor with levels No and Yes indicating whether the customer defaulted on their debtstudent: factor. A factor with levels No and Yes indicating whether the customer is a studentbalance: numeric. The average balance that the customer has remaining on their credit card after making their monthly paymentincome: numeric. Income of customer
default student balance income
1 No No 729.5265 44361.625
2 No Yes 817.1804 12106.135
3 No No 1073.5492 31767.139
4 No No 529.2506 35704.494
5 No No 785.6559 38463.496
6 No Yes 919.5885 7491.559'data.frame': 10000 obs. of 4 variables:
$ default: Factor w/ 2 levels "No","Yes": 1 1 1 1 1 1 1 1 1 1 ...
$ student: Factor w/ 2 levels "No","Yes": 1 2 1 1 1 2 1 2 1 1 ...
$ balance: num 730 817 1074 529 786 ...
$ income : num 44362 12106 31767 35704 38463 ... default student balance income
No :9667 No :7056 Min. : 0.0 Min. : 772
Yes: 333 Yes:2944 1st Qu.: 481.7 1st Qu.:21340
Median : 823.6 Median :34553
Mean : 835.4 Mean :33517
3rd Qu.:1166.3 3rd Qu.:43808
Max. :2654.3 Max. :73554 Split dataset
split_by() splits the data.frame or tbl_df into a training set and a test set.
Split dataset with split_by()
The split_df class is created, which contains the split information and criteria to separate the training and the test set.
library(alookr)
library(dplyr)
# Generate data for the example
sb <- ISLR::Default %>%
split_by(default, seed = 6534)
sb
# A tibble: 10,000 x 5
# Groups: split_flag [2]
default student balance income split_flag
<fct> <fct> <dbl> <dbl> <chr>
1 No No 730. 44362. train
2 No Yes 817. 12106. train
3 No No 1074. 31767. train
4 No No 529. 35704. train
# … with 9,996 more rowsThe attributes of the split_df class are as follows.:
- split_seed : integer. random seed used for splitting
- target : character. the name of the target variable
- binary : logical. whether the target variable is binary class
- minority : character. the name of the minority class
- majority : character. the name of the majority class
- minority_rate : numeric. the rate of the minority class
- majority_rate : numeric. the rate of the majority class
attr_names <- names(attributes(sb))
attr_names
[1] "names" "row.names" "groups" "class"
[5] "split_seed" "target" "binary" "minority"
[9] "majority" "minority_rate" "majority_rate"sb_attr <- attributes(sb)
# The third property, row.names, is excluded from the output because its length is very long.
sb_attr[!attr_names %in% "row.names"]
$names
[1] "default" "student" "balance" "income" "split_flag"
$groups
# A tibble: 2 x 2
split_flag .rows
<chr> <list<int>>
1 test [3,000]
2 train [7,000]
$class
[1] "split_df" "grouped_df" "tbl_df" "tbl" "data.frame"
$split_seed
[1] 6534
$target
default
"default"
$binary
[1] TRUE
$minority
[1] "Yes"
$majority
[1] "No"
$minority_rate
Yes
0.0333
$majority_rate
No
0.9667 summary() summarizes the information of two datasets splitted by split_by().
summary(sb)
** Split train/test set information **
+ random seed : 6534
+ split data
- train set count : 7000
- test set count : 3000
+ target variable : default
- minority class : Yes (0.033300)
- majority class : No (0.966700)Compare dataset
Train data and test data should be similar. If the two datasets are not similar, the performance of the predictive model may be reduced.
alookr provides a function to compare the similarity between train dataset and test dataset.
If the two data sets are not similar, the train dataset and test dataset should be splitted again from the original data.
Comparison of categorical variables with compare_target_category()
Compare the statistics of the categorical variables of the train set and test set included in the “split_df” class.
sb %>%
compare_target_category()
# A tibble: 4 x 5
variable level train test abs_diff
<chr> <fct> <dbl> <dbl> <dbl>
1 default No 96.7 96.7 0.00476
2 default Yes 3.33 3.33 0.00476
3 student No 70.0 71.8 1.77
4 student Yes 30.0 28.2 1.77 # compare variables that are character data types.
sb %>%
compare_target_category(add_character = TRUE)
# A tibble: 4 x 5
variable level train test abs_diff
<chr> <fct> <dbl> <dbl> <dbl>
1 default No 96.7 96.7 0.00476
2 default Yes 3.33 3.33 0.00476
3 student No 70.0 71.8 1.77
4 student Yes 30.0 28.2 1.77 # display marginal
sb %>%
compare_target_category(margin = TRUE)
# A tibble: 6 x 5
variable level train test abs_diff
<chr> <fct> <dbl> <dbl> <dbl>
1 default No 96.7 96.7 0.00476
2 default Yes 3.33 3.33 0.00476
3 default <Total> 100 100 0.00952
4 student No 70.0 71.8 1.77
# … with 2 more rows# student variable only
sb %>%
compare_target_category(student)
# A tibble: 2 x 5
variable level train test abs_diff
<chr> <fct> <dbl> <dbl> <dbl>
1 student No 70.0 71.8 1.77
2 student Yes 30.0 28.2 1.77sb %>%
compare_target_category(student, margin = TRUE)
# A tibble: 3 x 5
variable level train test abs_diff
<chr> <fct> <dbl> <dbl> <dbl>
1 student No 70.0 71.8 1.77
2 student Yes 30.0 28.2 1.77
3 student <Total> 100 100 3.54compare_target_category() returns tbl_df, where the variables have the following.:
- variable : character. categorical variable name
- level : factor. level of categorical variables
- train : numeric. the relative frequency of the level in the train set
- test : numeric. the relative frequency of the level in the test set
- abs_diff : numeric. the absolute value of the difference between two relative frequencies
Comparison of numeric variables with compare_target_numeric()
Compare the statistics of the numerical variables of the train set and test set included in the “split_df” class.
sb %>%
compare_target_numeric()
# A tibble: 2 x 7
variable train_mean test_mean train_sd test_sd train_z test_z
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 balance 836. 834. 487. 477. 1.72 1.75
2 income 33446. 33684. 13437. 13101. 2.49 2.57# balance variable only
sb %>%
compare_target_numeric(balance)
# A tibble: 1 x 7
variable train_mean test_mean train_sd test_sd train_z test_z
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 balance 836. 834. 487. 477. 1.72 1.75compare_target_numeric() returns tbl_df, where the variables have the following.:
- variable : character. numeric variable name
- train_mean : numeric. arithmetic mean of train set
- test_mean : numeric. arithmetic mean of test set
- train_sd : numeric. standard deviation of train set
- test_sd : numeric. standard deviation of test set
- train_z : numeric. the arithmetic mean of the train set divided by the standard deviation
- test_z : numeric. the arithmetic mean of the test set divided by the standard deviation
Comparison plot with compare_plot()
Plot compare information of the train set and test set included in the “split_df” class.
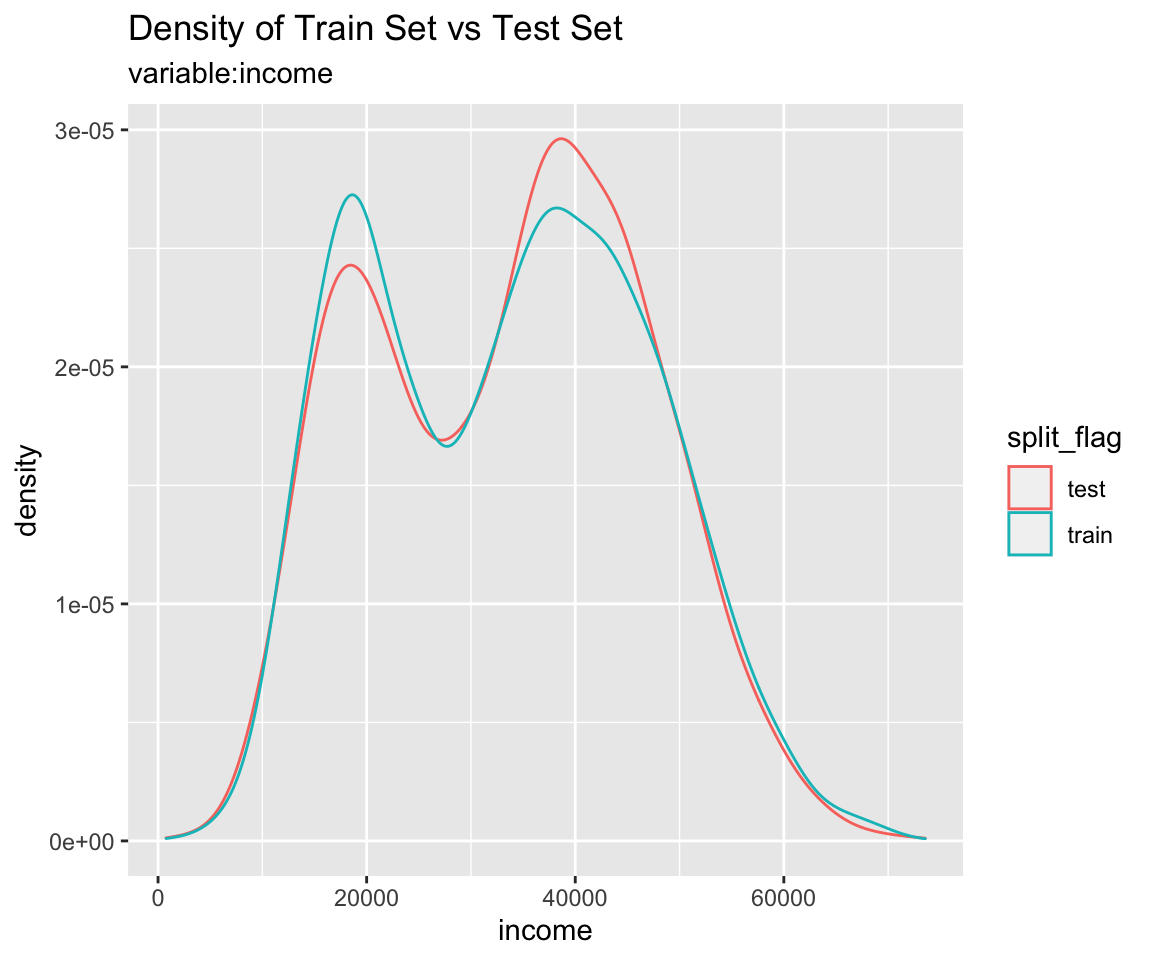
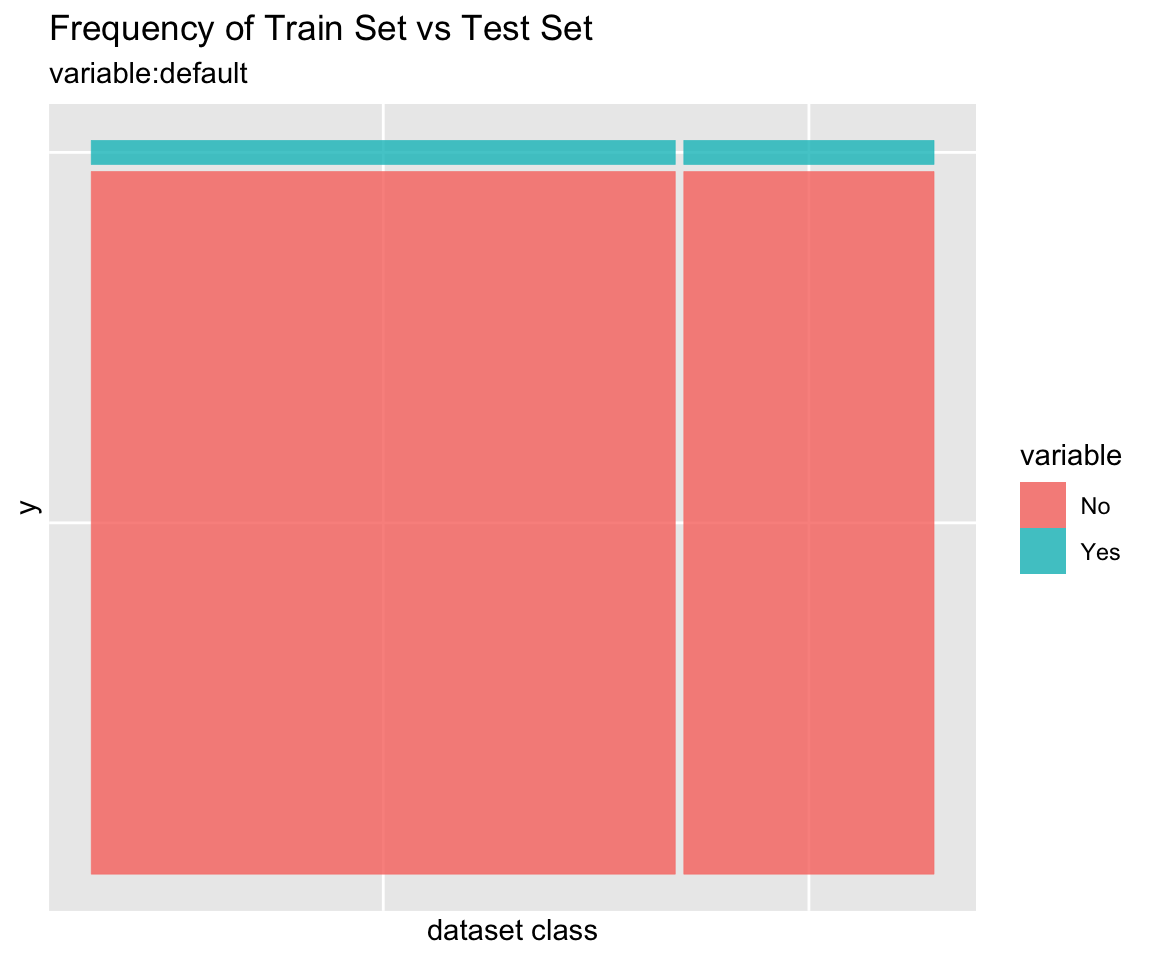
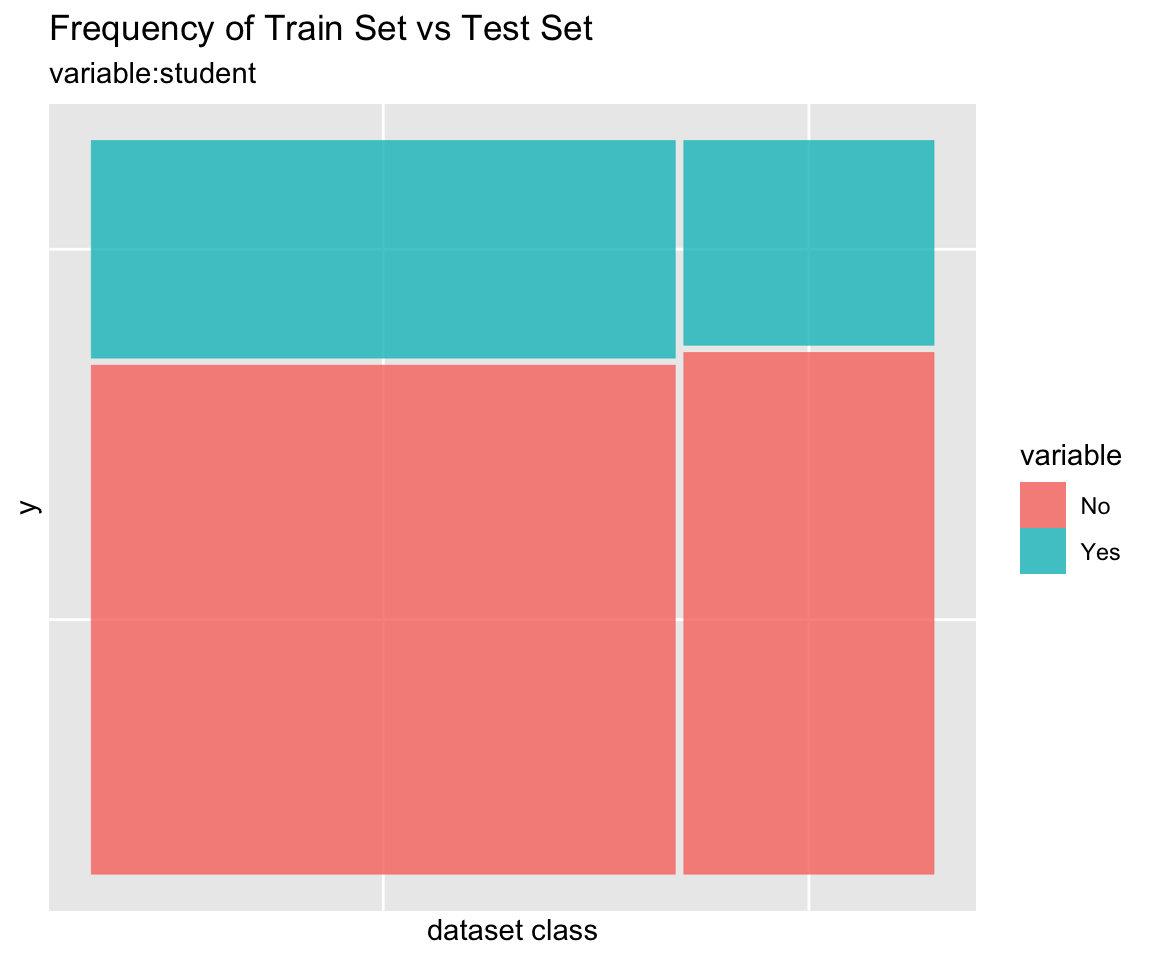
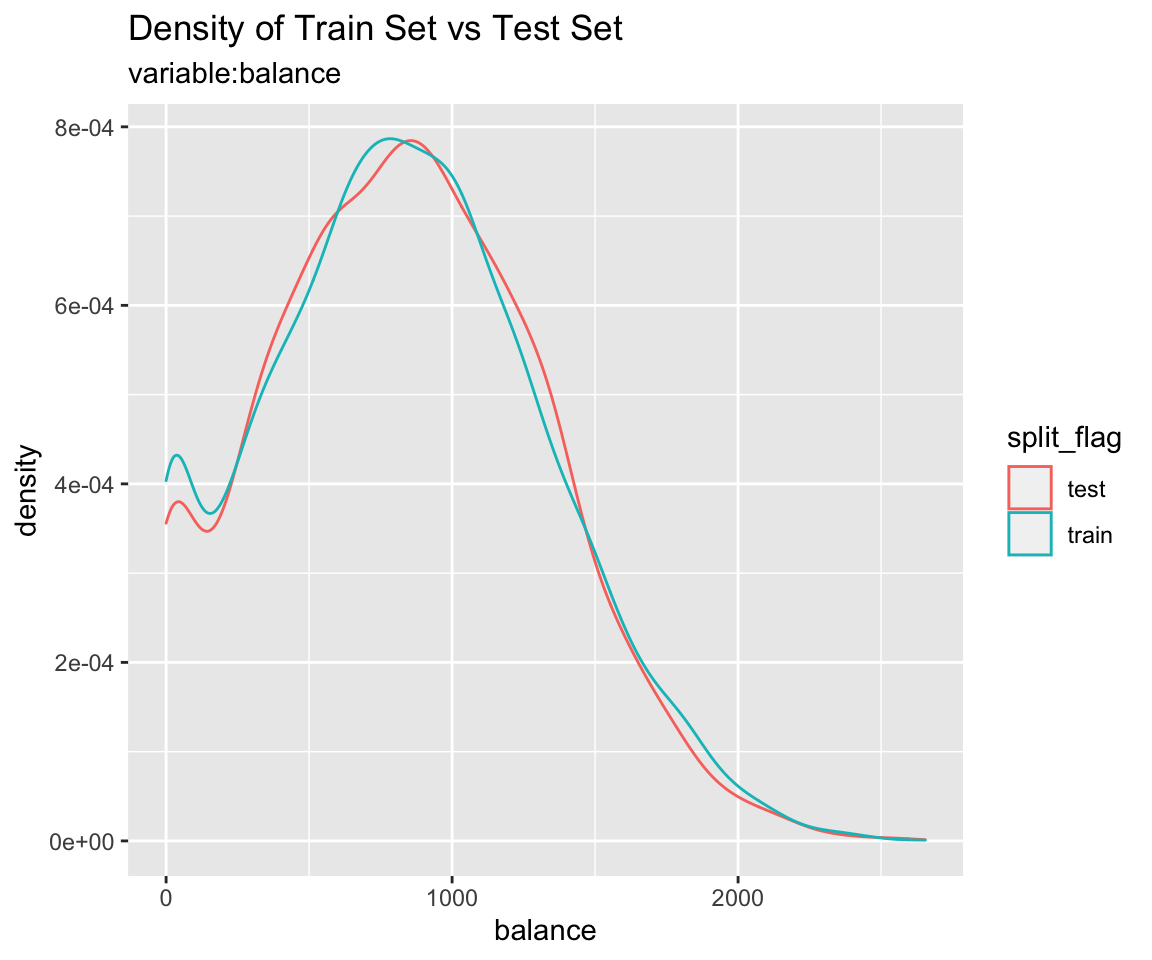
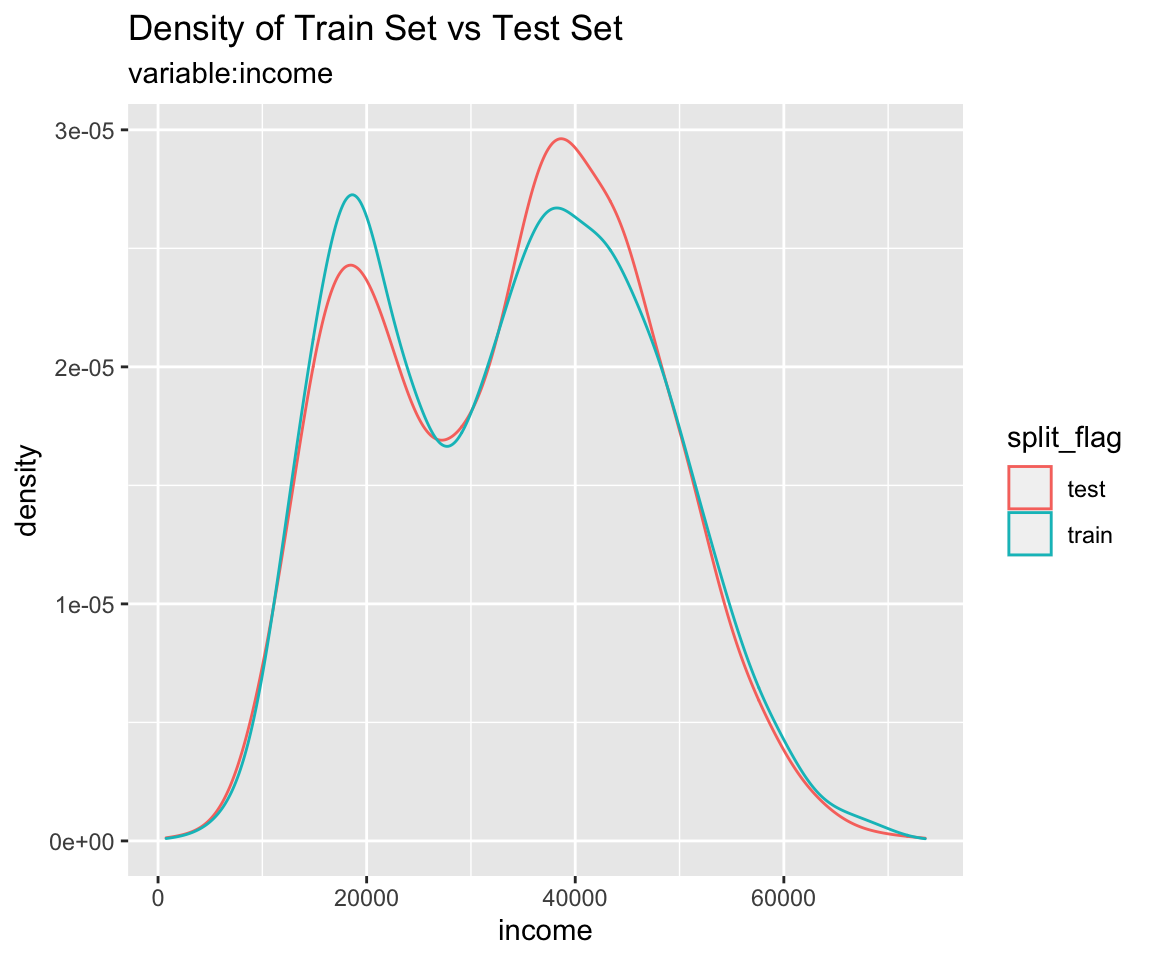
Diagnosis of train set and test set with compare_diag()
Diagnosis of similarity between datasets splitted by train set and set included in the “split_df” class.
defaults <- ISLR::Default
defaults$id <- seq(NROW(defaults))
set.seed(1)
defaults[sample(seq(NROW(defaults)), 3), "student"] <- NA
set.seed(2)
defaults[sample(seq(NROW(defaults)), 10), "balance"] <- NA
sb_2 <- defaults %>%
split_by(default)
sb_2 %>%
compare_diag()
$missing_value
# A tibble: 3 x 4
variables train_misscount train_missrate test_missrate
<chr> <int> <dbl> <dbl>
1 student 3 0.0429 NA
2 balance 8 0.114 NA
3 balance 2 NA 0.0667
$single_value
# A tibble: 0 x 3
# … with 3 variables: variables <chr>, train_uniq <lgl>,
# test_uniq <lgl>
$uniq_rate
# A tibble: 0 x 5
# … with 5 variables: variables <chr>, train_uniqcount <int>,
# train_uniqrate <dbl>, test_uniqcount <int>, test_uniqrate <dbl>
$missing_level
# A tibble: 1 x 4
variables n_levels train_missing_nlevel test_missing_nlevel
<chr> <int> <int> <int>
1 student 3 0 1sb_2 %>%
compare_diag(add_character = TRUE)
$missing_value
# A tibble: 3 x 4
variables train_misscount train_missrate test_missrate
<chr> <int> <dbl> <dbl>
1 student 3 0.0429 NA
2 balance 8 0.114 NA
3 balance 2 NA 0.0667
$single_value
# A tibble: 0 x 3
# … with 3 variables: variables <chr>, train_uniq <lgl>,
# test_uniq <lgl>
$uniq_rate
# A tibble: 0 x 5
# … with 5 variables: variables <chr>, train_uniqcount <int>,
# train_uniqrate <dbl>, test_uniqcount <int>, test_uniqrate <dbl>
$missing_level
# A tibble: 1 x 4
variables n_levels train_missing_nlevel test_missing_nlevel
<chr> <int> <int> <int>
1 student 3 0 1sb_2 %>%
compare_diag(uniq_thres = 0.0005)
$missing_value
# A tibble: 3 x 4
variables train_misscount train_missrate test_missrate
<chr> <int> <dbl> <dbl>
1 student 3 0.0429 NA
2 balance 8 0.114 NA
3 balance 2 NA 0.0667
$single_value
# A tibble: 0 x 3
# … with 3 variables: variables <chr>, train_uniq <lgl>,
# test_uniq <lgl>
$uniq_rate
# A tibble: 2 x 5
variables train_uniqcount train_uniqrate test_uniqcount
<chr> <int> <dbl> <int>
1 default NA NA 2
2 student NA NA 2
# … with 1 more variable: test_uniqrate <dbl>
$missing_level
# A tibble: 1 x 4
variables n_levels train_missing_nlevel test_missing_nlevel
<chr> <int> <int> <int>
1 student 3 0 1Extract train/test dataset
If you compare the train set with the test set and find that the two datasets are similar, extract the data from the split_df object.
Extract train set or test set with extract_set()
Extract train set or test set from split_df class object.
train <- sb %>%
extract_set(set = "train")
test <- sb %>%
extract_set(set = "test")
dim(train)
[1] 7000 4dim(test)
[1] 3000 4Extract the data to fit the model with sampling_target()
In a target class, the ratio of the majority class to the minority class is not similar and the ratio of the minority class is very small, which is called the imbalanced class.
If target variable is an imbalanced class, the characteristics of the majority class are actively reflected in the model. This model implies an error in predicting the minority class as the majority class. So we have to make the train dataset a balanced class.
sampling_target() performs sampling on the train set of split_df to resolve the imbalanced class.
# under-sampling with random seed
under <- sb %>%
sampling_target(seed = 1234L)
under %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 233
2 Yes 233# under-sampling with random seed, and minority class frequency is 40%
under40 <- sb %>%
sampling_target(seed = 1234L, perc = 40)
under40 %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 349
2 Yes 233# over-sampling with random seed
over <- sb %>%
sampling_target(method = "ubOver", seed = 1234L)
over %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 6767
2 Yes 6767# over-sampling with random seed, and k = 10
over10 <- sb %>%
sampling_target(method = "ubOver", seed = 1234L, k = 10)
over10 %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 6767
2 Yes 2330# SMOTE with random seed
smote <- sb %>%
sampling_target(method = "ubSMOTE", seed = 1234L)
smote %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 932
2 Yes 699# SMOTE with random seed, and perc.under = 250
smote250 <- sb %>%
sampling_target(method = "ubSMOTE", seed = 1234L, perc.under = 250)
smote250 %>%
count(default)
# A tibble: 2 x 2
default n
<fct> <int>
1 No 1165
2 Yes 699The argument that specifies the sampling method in sampling_target () is method. “ubUnder” is under-sampling, and “ubOver” is over-sampling, “ubSMOTE” is SMOTE(Synthetic Minority Over-sampling TEchnique).
Modeling and Evaluate, Predict
Data: Wisconsin Breast Cancer Data
BreastCancer of mlbench package is a breast cancer data. The objective is to identify each of a number of benign or malignant classes.
A data frame with 699 observations on 11 variables, one being a character variable, 9 being ordered or nominal, and 1 target class.:
Id: character. Sample code numberCl.thickness: ordered factor. Clump ThicknessCell.size: ordered factor. Uniformity of Cell SizeCell.shape: ordered factor. Uniformity of Cell ShapeMarg.adhesion: ordered factor. Marginal AdhesionEpith.c.size: ordered factor. Single Epithelial Cell SizeBare.nuclei: factor. Bare NucleiBl.cromatin: factor. Bland ChromatinNormal.nucleoli: factor. Normal NucleoliMitoses: factor. MitosesClass: factor. Class. level isbenignandmalignant.
library(mlbench)
data(BreastCancer)
# class of each variables
sapply(BreastCancer, function(x) class(x)[1])
Id Cl.thickness Cell.size Cell.shape
"character" "ordered" "ordered" "ordered"
Marg.adhesion Epith.c.size Bare.nuclei Bl.cromatin
"ordered" "ordered" "factor" "factor"
Normal.nucleoli Mitoses Class
"factor" "factor" "factor" Preperation the data
Perform data preprocessing as follows.:
- Find and imputate variables that contain missing values.
- Split the data into a train set and a test set.
- To solve the imbalanced class, perform sampling in the train set of raw data.
- Cleansing the dataset for classification modeling.
Fix the missing value with dlookr::imputate_na()
find the variables that include missing value. and imputate the missing value using imputate_na() in dlookr package.
library(dlookr)
library(dplyr)
# variable that have a missing value
diagnose(BreastCancer) %>%
filter(missing_count > 0)
# A tibble: 1 x 6
variables types missing_count missing_percent unique_count
<chr> <chr> <int> <dbl> <int>
1 Bare.nuclei factor 16 2.29 11
# … with 1 more variable: unique_rate <dbl># imputation of missing value
breastCancer <- BreastCancer %>%
mutate(Bare.nuclei = imputate_na(BreastCancer, Bare.nuclei, Class,
method = "mice", no_attrs = TRUE, print_flag = FALSE))
Split data set
Splits the dataset into a train set and a test set with split_by()
split_by() in the alookr package splits the dataset into a train set and a test set.
The ratio argument of the split_by() function specifies the ratio of the train set.
split_by() creates a class object named split_df.
library(alookr)
# split the data into a train set and a test set by default arguments
sb <- breastCancer %>%
split_by(target = Class)
# show the class name
class(sb)
[1] "split_df" "grouped_df" "tbl_df" "tbl" "data.frame"# split the data into a train set and a test set by ratio = 0.6
tmp <- breastCancer %>%
split_by(Class, ratio = 0.6)
The summary() function displays the following useful information about the split_df object:
- random seed : The random seed is the random seed used internally to separate the data
- split data : Information of splited data
- train set count : number of train set
- test set count : number of test set
- target variable : Target variable name
- minority class : name and ratio(In parentheses) of minority class
- majority class : name and ratio(In parentheses) of majority class
# summary() display the some information
summary(sb)
** Split train/test set information **
+ random seed : 14818
+ split data
- train set count : 489
- test set count : 210
+ target variable : Class
- minority class : malignant (0.344778)
- majority class : benign (0.655222)# summary() display the some information
summary(tmp)
** Split train/test set information **
+ random seed : 44115
+ split data
- train set count : 419
- test set count : 280
+ target variable : Class
- minority class : malignant (0.344778)
- majority class : benign (0.655222)Check missing levels in the train set
In the case of categorical variables, when a train set and a test set are separated, a specific level may be missing from the train set.
In this case, there is no problem when fitting the model, but an error occurs when predicting with the model you created. Therefore, preprocessing is performed to avoid missing data preprocessing.
In the following example, fortunately, there is no categorical variable that contains the missing levels in the train set.
# list of categorical variables in the train set that contain missing levels
nolevel_in_train <- sb %>%
compare_target_category() %>%
filter(is.na(train)) %>%
select(variable) %>%
unique() %>%
pull
nolevel_in_train
character(0)# if any of the categorical variables in the train set contain a missing level,
# split them again.
while (length(nolevel_in_train) > 0) {
sb <- breastCancer %>%
split_by(Class)
nolevel_in_train <- sb %>%
compare_target_category() %>%
filter(is.na(train)) %>%
select(variable) %>%
unique() %>%
pull
}
Handling the imbalanced classes data with sampling_target()
Issue of imbalanced classes data
Imbalanced classes(levels) data means that the number of one level of the frequency of the target variable is relatively small. In general, the proportion of positive classes is relatively small. For example, in the model of predicting spam, the class of interest spam is less than non-spam.
Imbalanced classes data is a common problem in machine learning classification.
table() and prop.table() are traditionally useful functions for diagnosing imbalanced classes data. However, alookr’s summary() is simpler and provides more information.
# train set frequency table - imbalanced classes data
table(sb$Class)
benign malignant
458 241 # train set relative frequency table - imbalanced classes data
prop.table(table(sb$Class))
benign malignant
0.6552217 0.3447783 # using summary function - imbalanced classes data
summary(sb)
** Split train/test set information **
+ random seed : 14818
+ split data
- train set count : 489
- test set count : 210
+ target variable : Class
- minority class : malignant (0.344778)
- majority class : benign (0.655222)Handling the imbalanced classes data
Most machine learning algorithms work best when the number of samples in each class are about equal. And most algorithms are designed to maximize accuracy and reduce error. So, we requre handling an imbalanced class problem.
sampling_target() performs sampling to solve an imbalanced classes data problem.
Resampling - oversample minority class
Oversampling can be defined as adding more copies of the minority class.
Oversampling is performed by specifying “ubOver” in the method argument of the sampling_target() function.
# to balanced by over sampling
train_over <- sb %>%
sampling_target(method = "ubOver")
# frequency table
table(train_over$Class)
benign malignant
319 319 Resampling - undersample majority class
Undersampling can be defined as removing some observations of the majority class.
Undersampling is performed by specifying “ubUnder” in the method argument of the sampling_target() function.
# to balanced by under sampling
train_under <- sb %>%
sampling_target(method = "ubUnder")
# frequency table
table(train_under$Class)
benign malignant
170 170 Generate synthetic samples - SMOTE
SMOTE(Synthetic Minority Oversampling Technique) uses a nearest neighbors algorithm to generate new and synthetic data.
SMOTE is performed by specifying “ubSMOTE” in the method argument of the sampling_target() function.
# to balanced by SMOTE
train_smote <- sb %>%
sampling_target(seed = 1234L, method = "ubSMOTE")
# frequency table
table(train_smote$Class)
benign malignant
680 510 Cleansing the dataset for classification modeling with cleanse()
The cleanse() cleanse the dataset for classification modeling.
This function is useful when fit the classification model. This function does the following.:
- Remove the variable with only one value.
- And remove variables that have a unique number of values relative to the number of observations for a character or categorical variable.
- In this case, it is a variable that corresponds to an identifier or an identifier.
- And converts the character to factor.
In this example, The cleanse() function removed a variable ID with a high unique rate.
# clean the training set
train <- train_smote %>%
cleanse
── Checking unique value ─────────────────────────── unique value is one ──
No variables that unique value is one.
── Checking unique rate ─────────────────────────────── high unique rate ──
• Id = 437(0.367226890756303)
── Checking character variables ─────────────────────── categorical data ──
No character variables.Extract test set for evaluation of the model with extract_set()
# extract test set
test <- sb %>%
extract_set(set = "test")
Binary classification modeling with run_models()
run_models() performs some representative binary classification modeling using split_df object created by split_by().
run_models() executes the process in parallel when fitting the model. However, it is not supported in MS-Windows operating system and RStudio environment.
Currently supported algorithms are as follows.:
- logistic : logistic regression using
statspackage - rpart : Recursive Partitioning Trees using
rpartpackage - ctree : Conditional Inference Trees using
partypackage - randomForest :Classification with Random Forest using
randomForestpackage - ranger : A Fast Implementation of Random Forests using
rangerpackage
run_models() returns a model_df class object.
The model_df class object contains the following variables.:
- step : character. The current stage in the classification modeling process.
- For objects created with
run_models(), the value of the variable is “1.Fitted”.
- For objects created with
- model_id : model identifiers
- target : name of target variable
- positive : positive class in target variable
- fitted_model : list. Fitted model object by model_id’s algorithms
result <- train %>%
run_models(target = "Class", positive = "malignant")
result
# A tibble: 7 x 7
step model_id target is_factor positive negative fitted_model
<chr> <chr> <chr> <lgl> <chr> <chr> <list>
1 1.Fitted logistic Class TRUE maligna… benign <glm>
2 1.Fitted rpart Class TRUE maligna… benign <rpart>
3 1.Fitted ctree Class TRUE maligna… benign <BinaryTr>
4 1.Fitted randomFore… Class TRUE maligna… benign <rndmFrs.>
# … with 3 more rowsEvaluate the model
Evaluate the predictive performance of fitted models.
Predict test set using fitted model with run_predict()
run_predict() predict the test set using model_df class fitted by run_models().
run_predict () is executed in parallel when predicting by model. However, it is not supported in MS-Windows operating system and RStudio environment.
The model_df class object contains the following variables.:
- step : character. The current stage in the classification modeling process.
- For objects created with
run_predict(), the value of the variable is “2.Predicted”.
- For objects created with
- model_id : character. Type of fit model.
- target : character. Name of target variable.
- positive : character. Level of positive class of binary classification.
- fitted_model : list. Fitted model object by model_id’s algorithms.
- predicted : result of predcit by each models
pred <- result %>%
run_predict(test)
pred
# A tibble: 7 x 8
step model_id target is_factor positive negative fitted_model
<chr> <chr> <chr> <lgl> <chr> <chr> <list>
1 2.Predic… logistic Class TRUE maligna… benign <glm>
2 2.Predic… rpart Class TRUE maligna… benign <rpart>
3 2.Predic… ctree Class TRUE maligna… benign <BinaryTr>
4 2.Predic… randomFor… Class TRUE maligna… benign <rndmFrs.>
# … with 3 more rows, and 1 more variable: predicted <list>Calculate the performance metric with run_performance()
run_performance() calculate the performance metric of model_df class predicted by run_predict().
run_performance () is performed in parallel when calculating the performance evaluation index. However, it is not supported in MS-Windows operating system and RStudio environment.
The model_df class object contains the following variables.:
- step : character. The current stage in the classification modeling process.
- For objects created with
run_performance(), the value of the variable is “3.Performanced”.
- For objects created with
- model_id : character. Type of fit model.
- target : character. Name of target variable.
- positive : character. Level of positive class of binary classification.
- fitted_model : list. Fitted model object by model_id’s algorithms
- predicted : list. Predicted value by individual model. Each value has a predict_class class object.
- performance : list. Calculate metrics by individual model. Each value has a numeric vector.
# Calculate performace metrics.
perf <- run_performance(pred)
perf
# A tibble: 7 x 7
step model_id target positive fitted_model predicted performance
<chr> <chr> <chr> <chr> <list> <list> <list>
1 3.Perf… logistic Class maligna… <glm> <fct [21… <dbl [15]>
2 3.Perf… rpart Class maligna… <rpart> <fct [21… <dbl [15]>
3 3.Perf… ctree Class maligna… <BinaryTr> <fct [21… <dbl [15]>
4 3.Perf… randomFo… Class maligna… <rndmFrs.> <fct [21… <dbl [15]>
# … with 3 more rowsThe performance variable contains a list object, which contains 15 performance metrics:
- ZeroOneLoss : Normalized Zero-One Loss(Classification Error Loss).
- Accuracy : Accuracy.
- Precision : Precision.
- Recall : Recall.
- Sensitivity : Sensitivity.
- Specificity : Specificity.
- F1_Score : F1 Score.
- Fbeta_Score : F-Beta Score.
- LogLoss : Log loss / Cross-Entropy Loss.
- AUC : Area Under the Receiver Operating Characteristic Curve (ROC AUC).
- Gini : Gini Coefficient.
- PRAUC : Area Under the Precision-Recall Curve (PR AUC).
- LiftAUC : Area Under the Lift Chart.
- GainAUC : Area Under the Gain Chart.
- KS_Stat : Kolmogorov-Smirnov Statistic.
# Performance by analytics models
performance <- perf$performance
names(performance) <- perf$model_id
performance
$logistic
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.04285714 0.95714286 0.90789474 0.97183099 0.97183099
Specificity F1_Score Fbeta_Score LogLoss AUC
0.94964029 0.93877551 0.93877551 1.43320622 0.96402878
Gini PRAUC LiftAUC GainAUC KS_Stat
0.94426994 0.01722128 1.17472123 0.80714286 92.86655183
$rpart
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.05238095 0.94761905 0.90540541 0.94366197 0.94366197
Specificity F1_Score Fbeta_Score LogLoss AUC
0.94964029 0.92413793 0.92413793 0.17443373 0.96879116
Gini PRAUC LiftAUC GainAUC KS_Stat
0.93677171 0.21381856 1.37318550 0.81029510 90.67788023
$ctree
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.04761905 0.95238095 0.90666667 0.95774648 0.95774648
Specificity F1_Score Fbeta_Score LogLoss AUC
0.94964029 0.93150685 0.93150685 0.33106801 0.97446550
Gini PRAUC LiftAUC GainAUC KS_Stat
0.95602391 0.64924384 1.87066074 0.81405097 90.73867666
$randomForest
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.03333333 0.96666667 0.92105263 0.98591549 0.98591549
Specificity F1_Score Fbeta_Score LogLoss AUC
0.95683453 0.95238095 0.95238095 0.10045446 0.99234978
Gini PRAUC LiftAUC GainAUC KS_Stat
0.98459824 0.75554241 1.88370599 0.82588867 95.71385145
$ranger
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.03333333 0.96666667 0.93243243 0.97183099 0.97183099
Specificity F1_Score Fbeta_Score LogLoss AUC
0.96402878 0.95172414 0.95172414 0.09562285 0.99260310
Gini PRAUC LiftAUC GainAUC KS_Stat
0.98520620 0.91071380 2.01842792 0.82605634 95.02482521
$xgboost
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.02857143 0.97142857 0.92207792 1.00000000 1.00000000
Specificity F1_Score Fbeta_Score LogLoss AUC
0.95683453 0.95945946 0.95945946 0.10796171 0.98895531
Gini PRAUC LiftAUC GainAUC KS_Stat
0.97730266 0.93589644 2.07536078 0.82364185 95.68345324
$lasso
ZeroOneLoss Accuracy Precision Recall Sensitivity
0.03333333 0.96666667 0.93243243 0.97183099 0.97183099
Specificity F1_Score Fbeta_Score LogLoss AUC
0.96402878 0.95172414 0.95172414 0.09325757 0.99392036
Gini PRAUC LiftAUC GainAUC KS_Stat
0.98784071 0.97152128 2.05577211 0.82692824 95.02482521 If you change the list object to tidy format, you’ll see the following at a glance:
# Convert to matrix for compare performace.
sapply(performance, "c")
logistic rpart ctree randomForest
ZeroOneLoss 0.04285714 0.05238095 0.04761905 0.03333333
Accuracy 0.95714286 0.94761905 0.95238095 0.96666667
Precision 0.90789474 0.90540541 0.90666667 0.92105263
Recall 0.97183099 0.94366197 0.95774648 0.98591549
Sensitivity 0.97183099 0.94366197 0.95774648 0.98591549
Specificity 0.94964029 0.94964029 0.94964029 0.95683453
F1_Score 0.93877551 0.92413793 0.93150685 0.95238095
Fbeta_Score 0.93877551 0.92413793 0.93150685 0.95238095
LogLoss 1.43320622 0.17443373 0.33106801 0.10045446
AUC 0.96402878 0.96879116 0.97446550 0.99234978
Gini 0.94426994 0.93677171 0.95602391 0.98459824
PRAUC 0.01722128 0.21381856 0.64924384 0.75554241
LiftAUC 1.17472123 1.37318550 1.87066074 1.88370599
GainAUC 0.80714286 0.81029510 0.81405097 0.82588867
KS_Stat 92.86655183 90.67788023 90.73867666 95.71385145
ranger xgboost lasso
ZeroOneLoss 0.03333333 0.02857143 0.03333333
Accuracy 0.96666667 0.97142857 0.96666667
Precision 0.93243243 0.92207792 0.93243243
Recall 0.97183099 1.00000000 0.97183099
Sensitivity 0.97183099 1.00000000 0.97183099
Specificity 0.96402878 0.95683453 0.96402878
F1_Score 0.95172414 0.95945946 0.95172414
Fbeta_Score 0.95172414 0.95945946 0.95172414
LogLoss 0.09562285 0.10796171 0.09325757
AUC 0.99260310 0.98895531 0.99392036
Gini 0.98520620 0.97730266 0.98784071
PRAUC 0.91071380 0.93589644 0.97152128
LiftAUC 2.01842792 2.07536078 2.05577211
GainAUC 0.82605634 0.82364185 0.82692824
KS_Stat 95.02482521 95.68345324 95.02482521compare_performance() return a list object(results of compared model performance). and list has the following components:
- recommend_model : character. The name of the model that is recommended as the best among the various models.
- top_count : numeric. The number of best performing performance metrics by model.
- mean_rank : numeric. Average of ranking individual performance metrics by model.
- top_metric : list. The name of the performance metric with the best performance on individual performance metrics by model.
In this example, compare_performance() recommend the “ranger” model.
# Compaire the Performance metrics of each model
comp_perf <- compare_performance(pred)
comp_perf
$recommend_model
[1] "lasso"
$top_metric_count
logistic rpart ctree randomForest ranger
0 0 0 1 2
xgboost lasso
5 7
$mean_rank
logistic rpart ctree randomForest ranger
5.846154 6.461538 5.615385 2.961538 2.615385
xgboost lasso
2.423077 2.076923
$top_metric
$top_metric$logistic
NULL
$top_metric$rpart
NULL
$top_metric$ctree
NULL
$top_metric$randomForest
[1] "KS_Stat"
$top_metric$ranger
[1] "Precision" "Specificity"
$top_metric$xgboost
[1] "ZeroOneLoss" "Accuracy" "Recall" "F1_Score"
[5] "LiftAUC"
$top_metric$lasso
[1] "Precision" "Specificity" "LogLoss" "AUC"
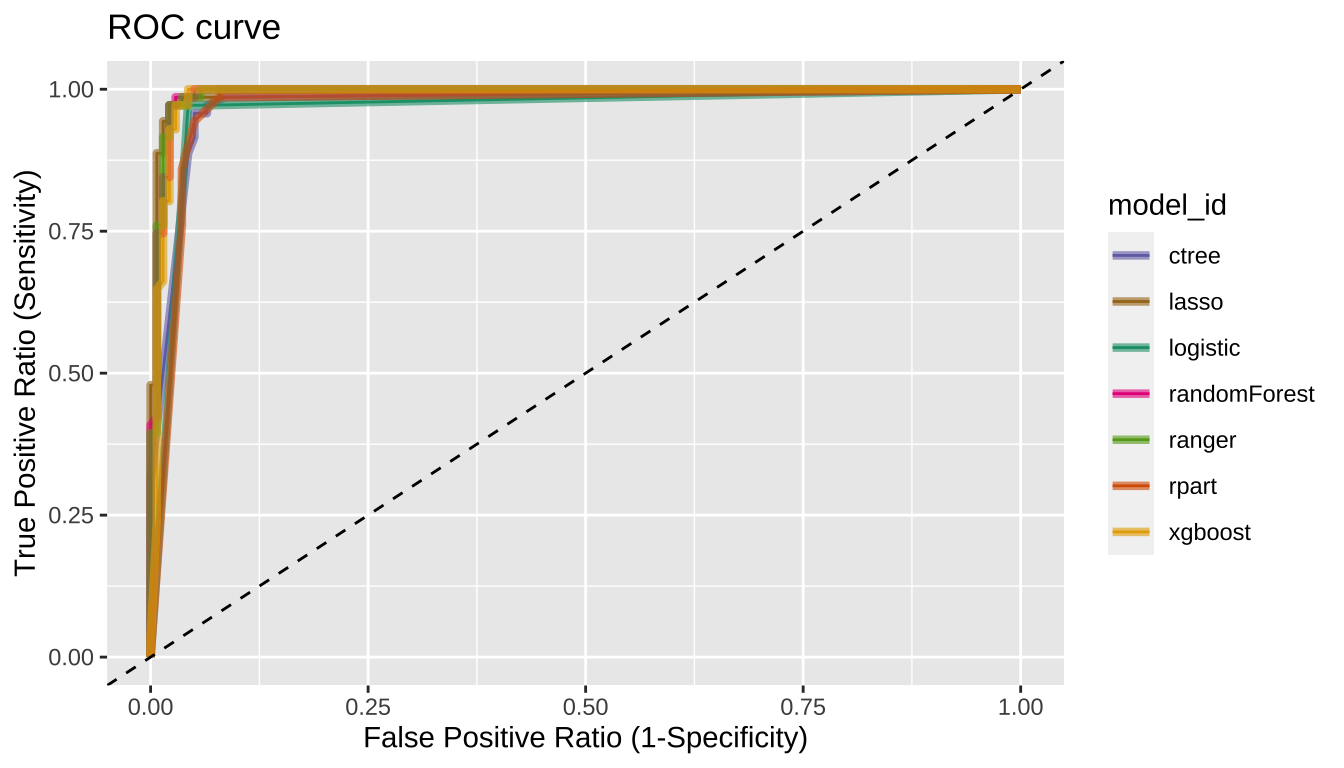
[5] "Gini" "PRAUC" "GainAUC" Plot the ROC curve with plot_performance()
compare_performance() plot ROC curve.
# Plot ROC curve
plot_performance(pred)
Tunning the cut-off
In general, if the prediction probability is greater than 0.5 in the binary classification model, it is predicted as positive class. In other words, 0.5 is used for the cut-off value. This applies to most model algorithms. However, in some cases, the performance can be tuned by changing the cut-off value.
plot_cutoff () visualizes a plot to select the cut-off value, and returns the cut-off value.
pred_best <- pred %>%
filter(model_id == comp_perf$recommend_model) %>%
select(predicted) %>%
pull %>%
.[[1]] %>%
attr("pred_prob")
cutoff <- plot_cutoff(pred_best, test$Class, "malignant", type = "mcc")
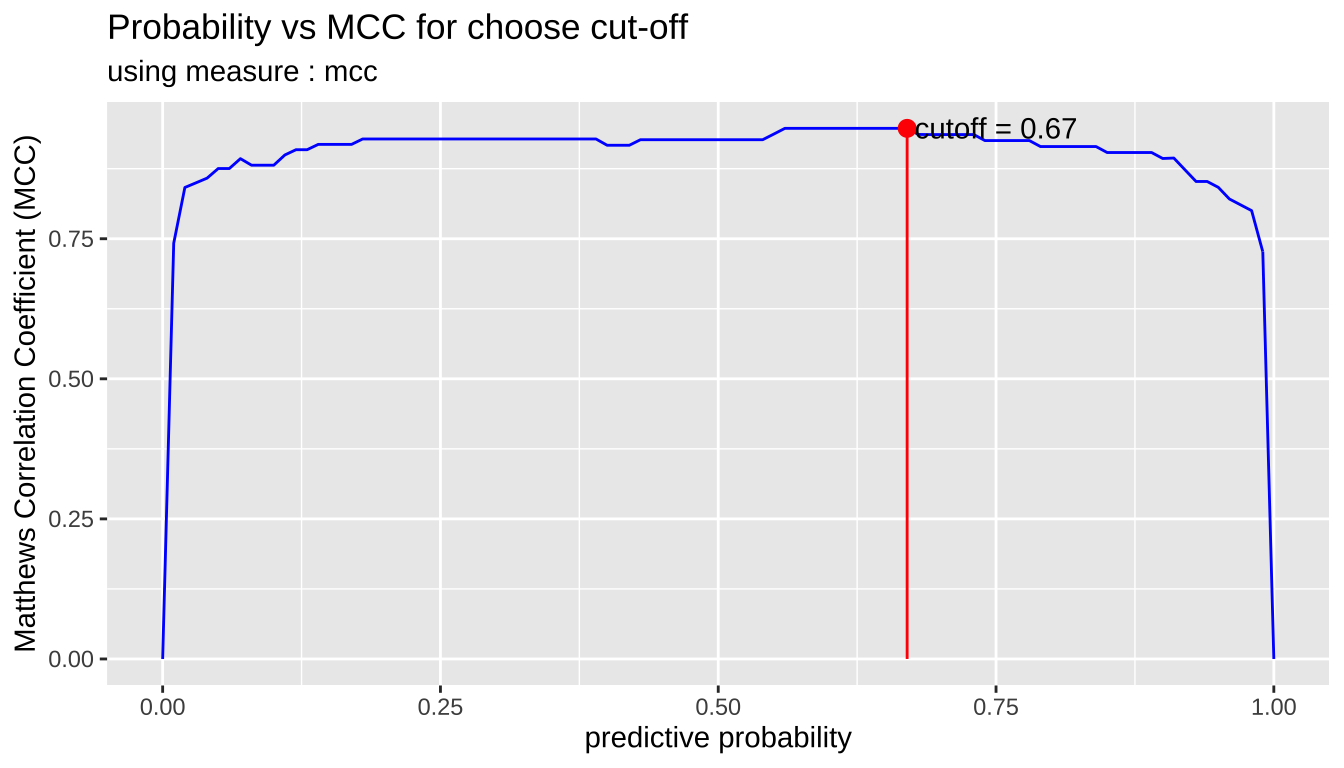
cutoff
[1] 0.67cutoff2 <- plot_cutoff(pred_best, test$Class, "malignant", type = "density")
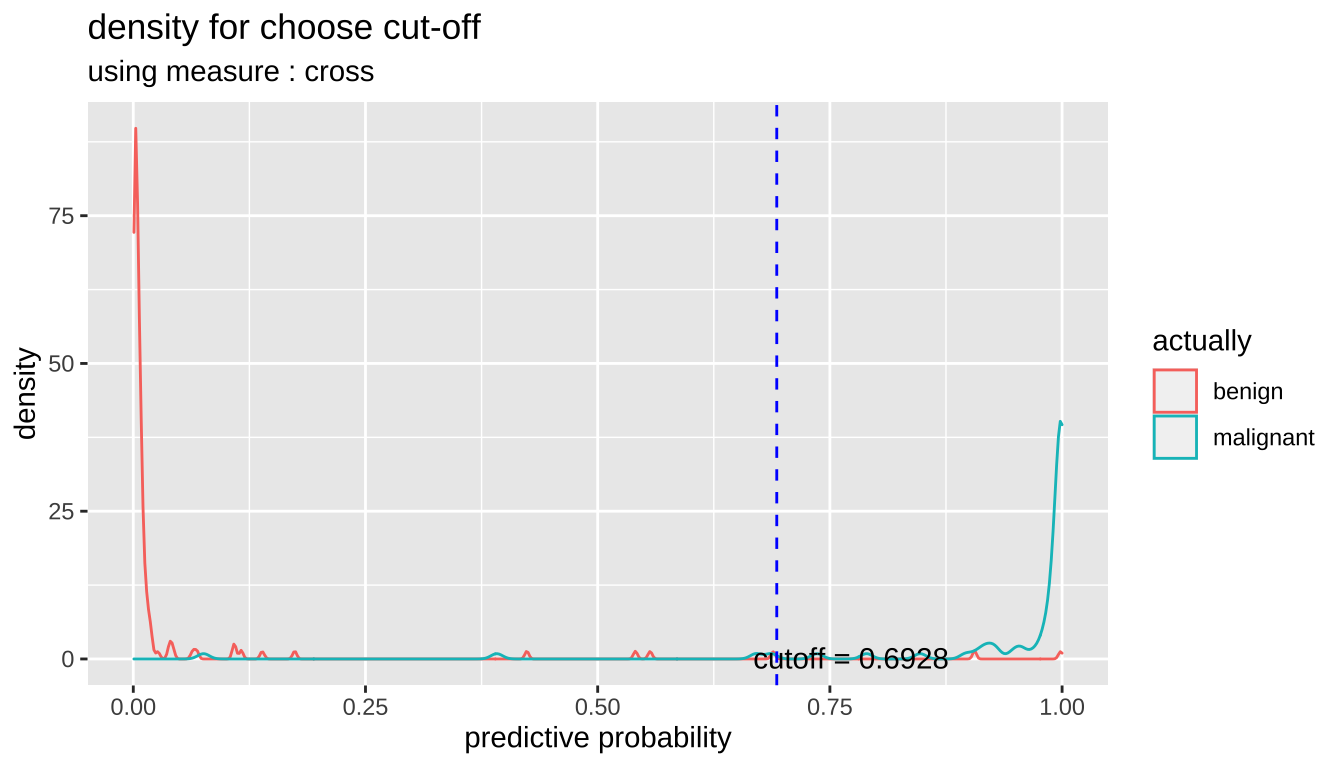
cutoff2
[1] 0.6928cutoff3 <- plot_cutoff(pred_best, test$Class, "malignant", type = "prob")
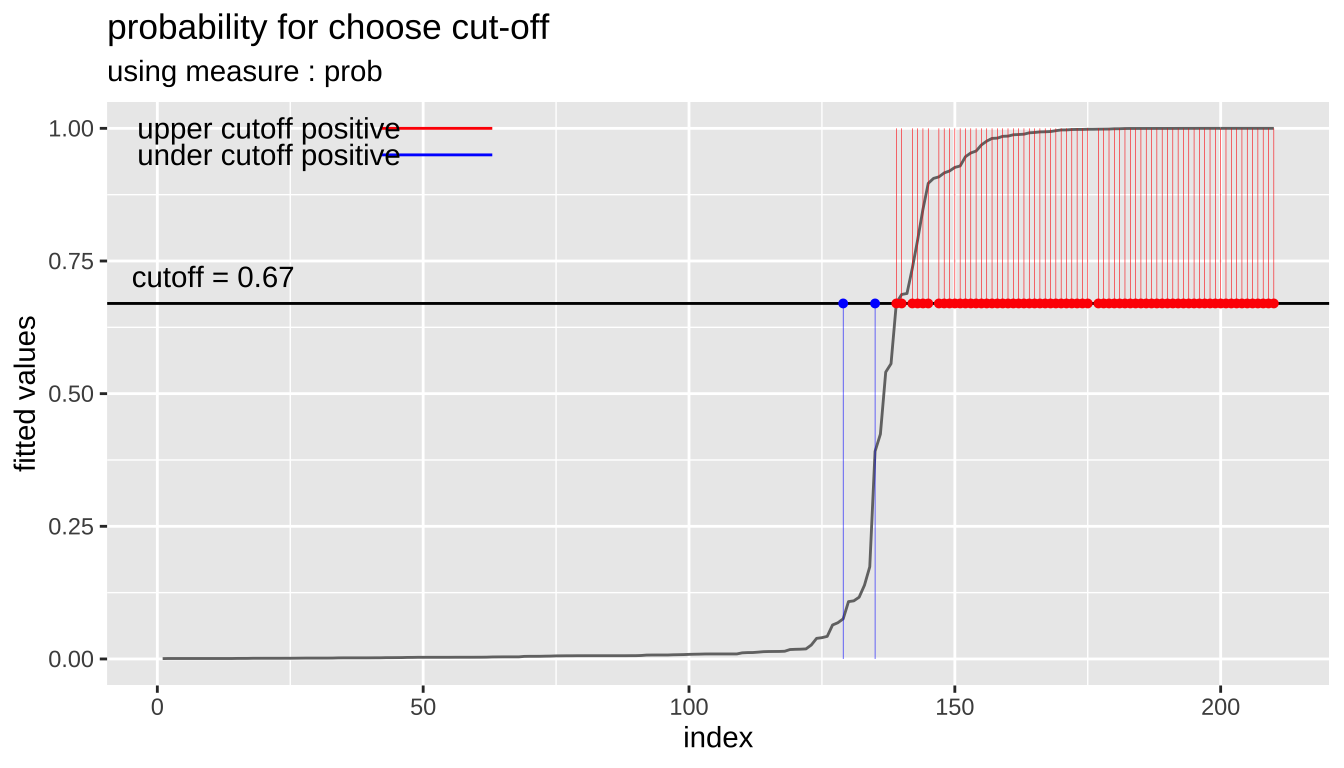
cutoff3
[1] 0.67Performance comparison between prediction and tuned cut-off with performance_metric()
Compare the performance of the original prediction with that of the tuned cut-off. Compare the cut-off with the non-cut model for the model with the best performance comp_perf$recommend_model.
comp_perf$recommend_model
[1] "lasso"# extract predicted probability
idx <- which(pred$model_id == comp_perf$recommend_model)
pred_prob <- attr(pred$predicted[[idx]], "pred_prob")
# or, extract predicted probability using dplyr
pred_prob <- pred %>%
filter(model_id == comp_perf$recommend_model) %>%
select(predicted) %>%
pull %>%
"[["(1) %>%
attr("pred_prob")
# predicted probability
pred_prob
[1] 0.0177546700 0.0189495146 0.0073209366 0.9999504268 0.0039579715
[6] 0.9759609573 0.0037722474 0.0094413466 0.0013023718 0.9998300604
[11] 0.6869421814 0.9998437927 0.0050499002 0.9853830303 0.9999959690
[16] 0.9985322958 0.7361849175 0.0140288334 0.0682727187 0.0078550012
[21] 0.1095384107 0.9999980415 0.0017374737 0.0755990146 0.9979659465
[26] 0.9977689915 0.0024806916 0.1080620891 0.9997972486 0.9998449540
[31] 0.0022109726 0.0021955342 0.9999393703 0.0054353242 0.0061165962
[36] 0.0020909665 0.0026223736 0.4237392464 0.9999997369 0.5406384477
[41] 0.0020909665 0.0031319356 0.9983299419 0.9992408490 0.9815634328
[46] 0.0094413466 0.0074795138 0.9983517936 0.0039579715 0.0031319356
[51] 0.0141696118 0.9999996480 0.0401139369 0.9998134264 0.9999917474
[56] 0.9810653114 0.9997727754 0.9889991960 0.6705777033 0.9935469003
[61] 0.8472658494 0.0074795138 0.9997773947 0.9987562540 0.0388247105
[66] 0.0031319356 0.0062207276 0.9085271128 0.9939917427 0.7895163765
[71] 0.9849519886 0.9196712296 0.0426028985 0.9998039298 0.0031319356
[76] 0.0032162770 0.0008728069 0.0013156114 0.9996734281 0.0062098409
[81] 0.9057298818 0.9263995279 0.8963795408 0.0016539309 0.9536035605
[86] 0.9970293842 0.9160360574 0.0008728069 0.9465787759 0.0031319356
[91] 0.0013511064 0.0008728069 0.9999824436 0.0010416530 0.9290444876
[96] 0.5564421412 0.9998324636 0.0093933413 0.9915908881 0.9999999440
[101] 0.9999828204 0.0013023718 0.0121131663 0.0013156114 0.0128678209
[106] 0.0008728069 0.0013511064 0.0640210122 0.0181963668 0.0006941589
[111] 0.0029548680 0.0058004220 0.0015602932 0.9999995036 0.0021181708
[116] 0.0013156114 0.1737380284 0.0016539309 0.1388836367 0.0038492779
[121] 0.9999988443 0.0029063415 0.9922099008 0.0032346583 0.0008728069
[126] 0.0050007783 0.0080339252 0.0050007783 0.3913793670 0.0074468436
[131] 0.0082491823 0.0052869014 0.9999791314 0.9986223232 0.0020200395
[136] 0.0039492874 0.0032346583 0.0059867407 0.9979949108 0.0184287353
[141] 0.9999999995 0.9999033596 0.0061032049 0.0008728069 0.0061165962
[146] 0.0061165962 0.0008728069 0.0094413466 0.0031498364 0.9993123673
[151] 0.0032826657 0.0010973809 0.9878714634 0.0032346583 0.0089302538
[156] 0.0039579715 0.0059973997 0.0061165962 0.0145468547 0.0020909665
[161] 0.0061165962 0.0094413466 0.0010746645 0.0016633982 0.1163940612
[166] 0.0025591913 0.0031319356 0.0140979073 0.0016539309 0.9969724915
[171] 0.0020909665 0.9999955230 0.0115430114 0.9883739882 0.9572209234
[176] 0.0061032049 0.9687516430 0.0262744005 0.0086594371 0.0013156114
[181] 0.0061165962 0.9955646856 0.9999412377 0.0008728069 0.0091034557
[186] 0.0061165962 0.0094413466 0.0008728069 0.0034200790 0.0137333220
[191] 0.0008728069 0.9999961243 0.0061165962 0.0074795138 0.0094413466
[196] 0.0008728069 0.0016539309 0.0024669885 0.0065334373 0.0008728069
[201] 0.0048422415 0.0058840711 0.0008728069 0.9999999972 0.6887804967
[206] 0.0014436550 0.0020909665 0.0120277662 0.0033144614 0.9932804070# compaire Accuracy
performance_metric(pred_prob, test$Class, "malignant", "Accuracy")
[1] 0.9666667performance_metric(pred_prob, test$Class, "malignant", "Accuracy",
cutoff = cutoff)
[1] 0.9761905# compaire Confusion Matrix
performance_metric(pred_prob, test$Class, "malignant", "ConfusionMatrix")
actual
predict benign malignant
benign 134 2
malignant 5 69performance_metric(pred_prob, test$Class, "malignant", "ConfusionMatrix",
cutoff = cutoff)
actual
predict benign malignant
benign 136 2
malignant 3 69# compaire F1 Score
performance_metric(pred_prob, test$Class, "malignant", "F1_Score")
[1] 0.9517241performance_metric(pred_prob, test$Class, "malignant", "F1_Score",
cutoff = cutoff)
[1] 0.965035performance_metric(pred_prob, test$Class, "malignant", "F1_Score",
cutoff = cutoff2)
[1] 0.9571429If the performance of the tuned cut-off is good, use it as a cut-off to predict positives.
Predict
If you have selected a good model from several models, then perform the prediction with that model.
Create data set for predict
Create sample data for predicting by extracting 100 samples from the data set used in the previous under sampling example.
data_pred <- train_under %>%
cleanse
── Checking unique value ─────────────────────────── unique value is one ──
No variables that unique value is one.
── Checking unique rate ─────────────────────────────── high unique rate ──
• Id = 331(0.973529411764706)
── Checking character variables ─────────────────────── categorical data ──
No character variables.Predict with alookr and dplyr
Do a predict using the dplyr package. The last factor() function eliminates unnecessary information.
pred_actual <- pred %>%
filter(model_id == comp_perf$recommend_model) %>%
run_predict(data_pred) %>%
select(predicted) %>%
pull %>%
"[["(1) %>%
factor()
pred_actual
[1] benign benign benign malignant malignant benign
[7] benign benign malignant malignant benign malignant
[13] benign benign malignant malignant benign benign
[19] malignant malignant benign malignant benign benign
[25] malignant benign benign benign benign benign
[31] malignant benign benign malignant benign benign
[37] malignant benign malignant benign malignant benign
[43] benign benign malignant malignant malignant benign
[49] benign benign
Levels: benign malignantIf you want to predict by cut-off, specify the cutoff argument in the run_predict() function as follows.:
In the example, there is no difference between the results of using cut-off and not.
pred_actual2 <- pred %>%
filter(model_id == comp_perf$recommend_model) %>%
run_predict(data_pred, cutoff) %>%
select(predicted) %>%
pull %>%
"[["(1) %>%
factor()
pred_actual2
[1] benign benign benign malignant malignant benign
[7] benign benign malignant malignant benign malignant
[13] benign benign malignant malignant benign benign
[19] malignant malignant benign malignant benign benign
[25] malignant benign benign benign benign benign
[31] malignant benign benign malignant benign benign
[37] malignant benign malignant benign malignant benign
[43] benign benign malignant malignant malignant benign
[49] benign benign
Levels: benign malignantsum(pred_actual != pred_actual2)
[1] 0