
들어가기
여러분은 NAVER의 오픈 API를 다루어 보았습니다.그것은 또 다른 오픈 API를 사용할 수 있다는 것을 의미합니다.
이제 여세를 몰아 여러분의 내공이 공공데이터의 수집을 갈망하게 됩니다.
공공데이터포털
공공데이터포털은 정부/지자체의 공공 데이터 제공을 목적으로 행정안전부에서 운영하는 사이트입니다.
2022-02-03일 기준으로 68,323건의 데이터를 공개하고 있으며, 오픈 API로는 8,745건을 공개하고 있습니다. 모든 데이터가 질적으로 우수하다고 단언하기는 어렵지만 몇몇 데이터는 인기가 많습니다.
데이터를 사용하기 위해서는 회원가입이 필수이며, 오픈 API를 사용하기 위해서는 활용신청 후 승인을 받아야 합니다.
아파트매매 실거래 상세 자료 수집
우리는 이제 국토교통부의 아파트매매 실거래 상세 자료를 수집하는 방법을 살펴봅니다. 별도의 아파트매매 실거래 자료 API가 있으므로 주의해야 합니다.
API 기본 정보
국토교통부_아파트매매 실거래 상세 자료 상세 페이지에서 여러 정보를 확인할 수 있습니다.
출력 포맷이 XML인 API이며, API 서비스 주소는 다음과 같습니다.
요청 변수 (request parameter)
요청 변수는 다음과 같습니다. 역시 인증을 위한 서비스키가 필요합니다.
영문명의 일관성이 떨어집니다. 대문자로만 구성된 영문명과 대소문자로 구성된 영문명이 혼재합니다. 단어의 결합 방법도 다릅니다. 언더라인(_) 사용한 것과 캡문자로 구분하는 방법이 섞여있습니다.
| 항목명(국문) | 항목명(영문) | 항목크기 | 항목구분 | 샘플데이터 | 항목설명 |
|---|---|---|---|---|---|
| 서비스키 | ServiceKey | 20 | 필수 | - | 공공데이터포털에서 받은 인증키 |
| 페이지 번호 | pageNo | 4 | 옵션 | 1 | 페이지번호 |
| 한 페이지 결과 수 | numOfRows | 4 | 옵션 | 10 | 한 페이지 결과 수 |
| 지역코드 | LAWD_CD | 5 | 필수 | 11110 | 지역코드 |
| 계약월 | DEAL_YMD | 6 | 필수 | 201512 | 계약월 |
출력 결과
출력 결과 정보는 너무 실망스럽습니다. 영문명은 일부 헤더 데이터만 제공하고, 실 데이터는 영문명없이 한글명으로 이루어져 있습니다. 이것은 한글사랑, 애국의 문제가 아닙니다.
API 프로그래밍을 위해서 변수명(영문명)은 영문으로 정의되어야 합니다. 변수명은 아스키(ASCII)1 문자 안에서의 알파벳, 숫자와 르포그램언어에서 지원하는 몇개의 문자로 구성해야 합니다.
더욱 심각한 문제는 이 정보가 현행화되어 있지 않습니다. 아마도 항목이 늘어난 것 같은데, 일부 데이터 항목이 이 상세 페이지의 출력결과에 누락되어 있습니다.
| 항목명(국문) | 항목명(영문) | 항목크기 | 항목구분 | 샘플데이터 | 항목설명 |
|---|---|---|---|---|---|
| 결과코드 | resultCode | 2 | 필수 | 00 | 결과코드 |
| 결과메시지 | resultMsg | 50 | 필수 | OK | 결과메시지 |
| 한 페이지 결과 수 | numOfRows | 4 | 필수 | 10 | 한 페이지 결과 수 |
| 페이지 번호 | pageNo | 4 | 필수 | 1 | 페이지번호 |
| 전체 결과 수 | totalCount | 4 | 필수 | 3 | 전체 결과 수 |
| 거래금액 | 거래금액 | 40 | 필수 | 82,500 | 거래금액 |
| 건축년도 | 건축년도 | 4 | 필수 | 2008 | 건축년도 |
| 년 | 년 | 4 | 필수 | 2015 | 년 |
| 도로명 | 도로명 | 40 | 필수 | 사직로8길 | 도로명 |
| 도로명건물본번호코드 | 도로명건물본번호코드 | 5 | 필수 | 00004 | 도로명건물본번호코드 |
| 도로명건물부번호코드 | 도로명건물부번호코드 | 5 | 필수 | 00000 | 도로명건물부번호코드 |
| 도로명시군구코드 | 도로명시군구코드 | 5 | 필수 | 11110 | 도로명시군구코드 |
| 도로명일련번호코드 | 도로명일련번호코드 | 2 | 필수 | 03 | 도로명일련번호코드 |
| 도로명지상지하코드 | 도로명지상지하코드 | 1 | 필수 | 0 | 도로명지상지하코드 |
| 도로명코드 | 도로명코드 | 7 | 필수 | 4100135 | 도로명코드 |
| 법정동 | 법정동 | 40 | 필수 | 사직동 | 법정동 |
| 법정동본번코드 | 법정동본번코드 | 4 | 필수 | 0009 | 법정동본번코드 |
| 법정동부번코드 | 법정동부번코드 | 4 | 필수 | 0000 | 법정동부번코드 |
| 법정동시군구코드 | 법정동시군구코드 | 5 | 필수 | 11110 | 법정동시군구코드 |
| 법정동읍면동코드 | 법정동읍면동코드 | 5 | 필수 | 11500 | 법정동읍면동코드 |
| 법정동지번코드 | 법정동지번코드 | 1 | 필수 | 1 | 법정동지번코드 |
| 아파트 | 아파트 | 40 | 필수 | 광화문풍림스페이스본(9-0) | 아파트 |
| 월 | 월 | 2 | 필수 | 12 | 월 |
| 일 | 일 | 6 | 필수 | 1~10 | 일 |
| 일련번호 | 일련번호 | 14 | 필수 | 11110-2203 | 일련번호 |
| 전용면적 | 전용면적 | 20 | 필수 | 94.51 | 전용면적 |
| 지번 | 지번 | 10 | 필수 | 9 | 지번 |
| 지역코드 | 지역코드 | 5 | 필수 | 11110 | 지역코드 |
| 층 | 층 | 4 | 필수 | 11 | 층 |
오픈API 상세 화면에서 참고문서인 아파트 매매 상세자료 조회 기술문서.hwp 파일을 다운로드하면 유용하게 활용할 수 있습니다.
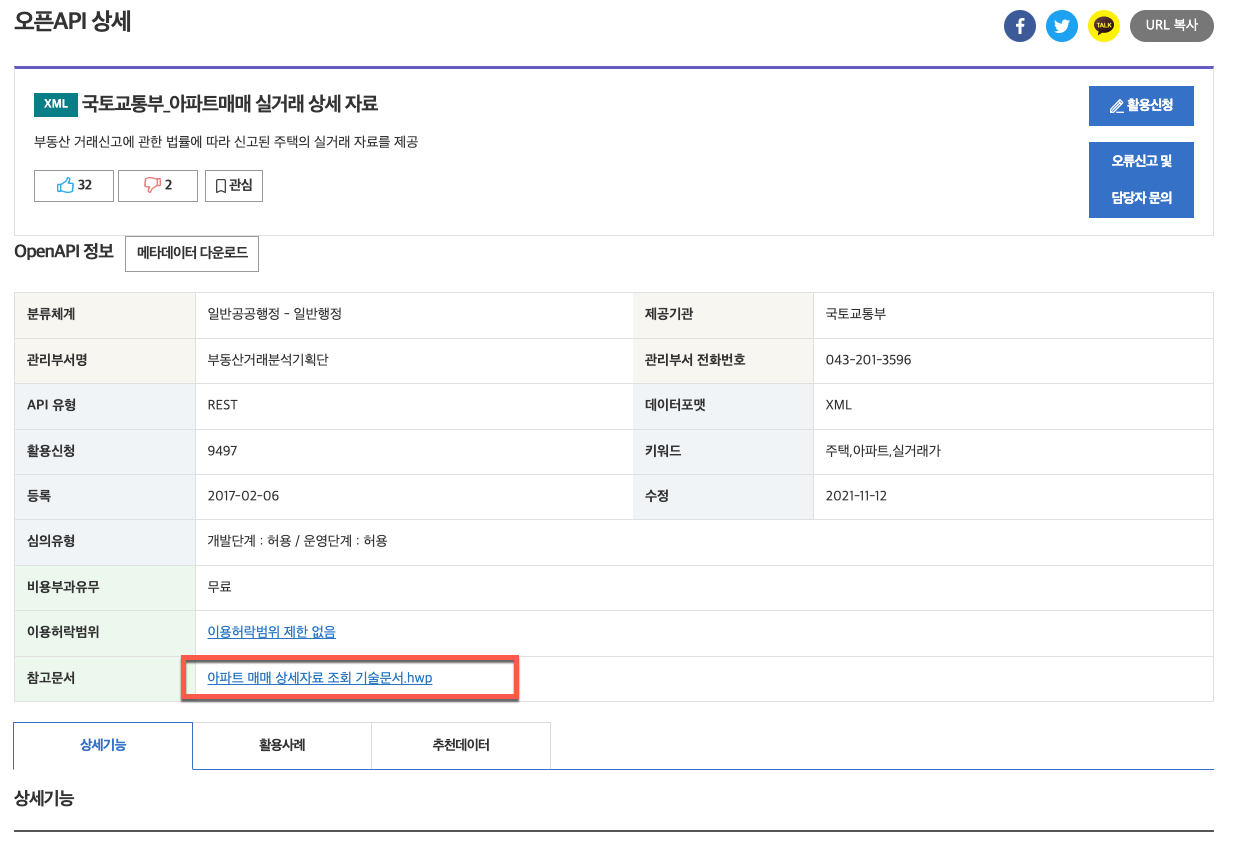
Figure 1: 오픈API 상세 화면
이 파일에는 홈페이지에서 누락된 출력 결과가 기술되어 있습니다. 다음은 파일에서의 출력결과 정보의 일부입니다.
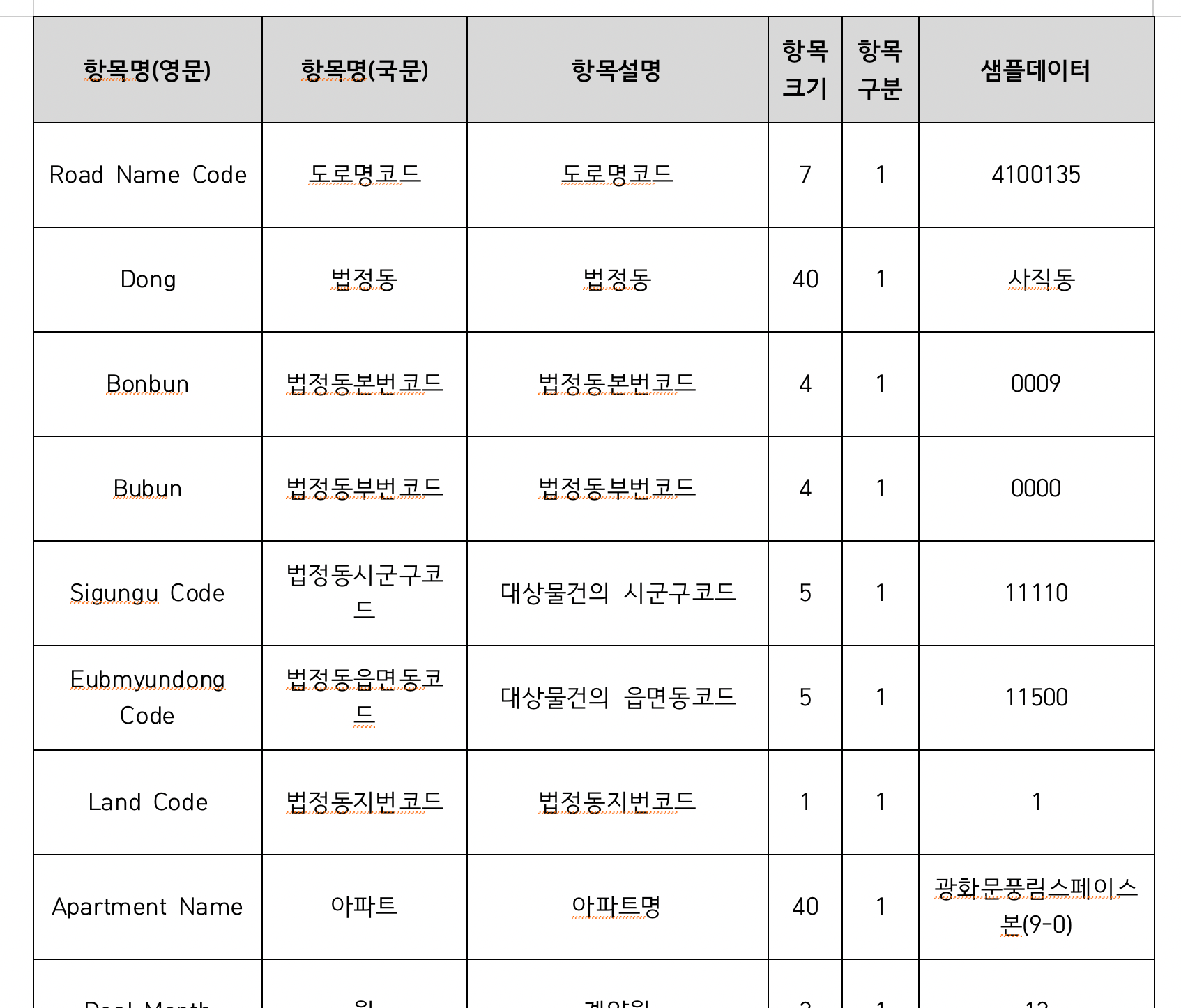
Figure 2: 출력결과 정보의 일부
파일의 정보에는 영문명이 있으나, 이것은 프로그래밍을 위한 변수 이름으로 사용할 수 없겠습니다. 결국은 API 프로그램 개발자가 변수 이름을 정의해야할 것 같습니다. 아쉬운 점이 많습니다.
준비사항
국토교통부_아파트매매 실거래 상세 자료 상세 오픈 API를 사용하기 위해서는 활용신청을 통해서 미리 승인을 받아야 합니다.
승인이 되면 마이페이지에서 개발계정 상세보기에서 다음과 같은 정보를 확인할 수 있습니다. 일반 인증키 역시 외부로 노출되지 않도록 주의해야 합니다. 이 서비스는 일일 트래픽이 1000회로 제한되어 있습니다.
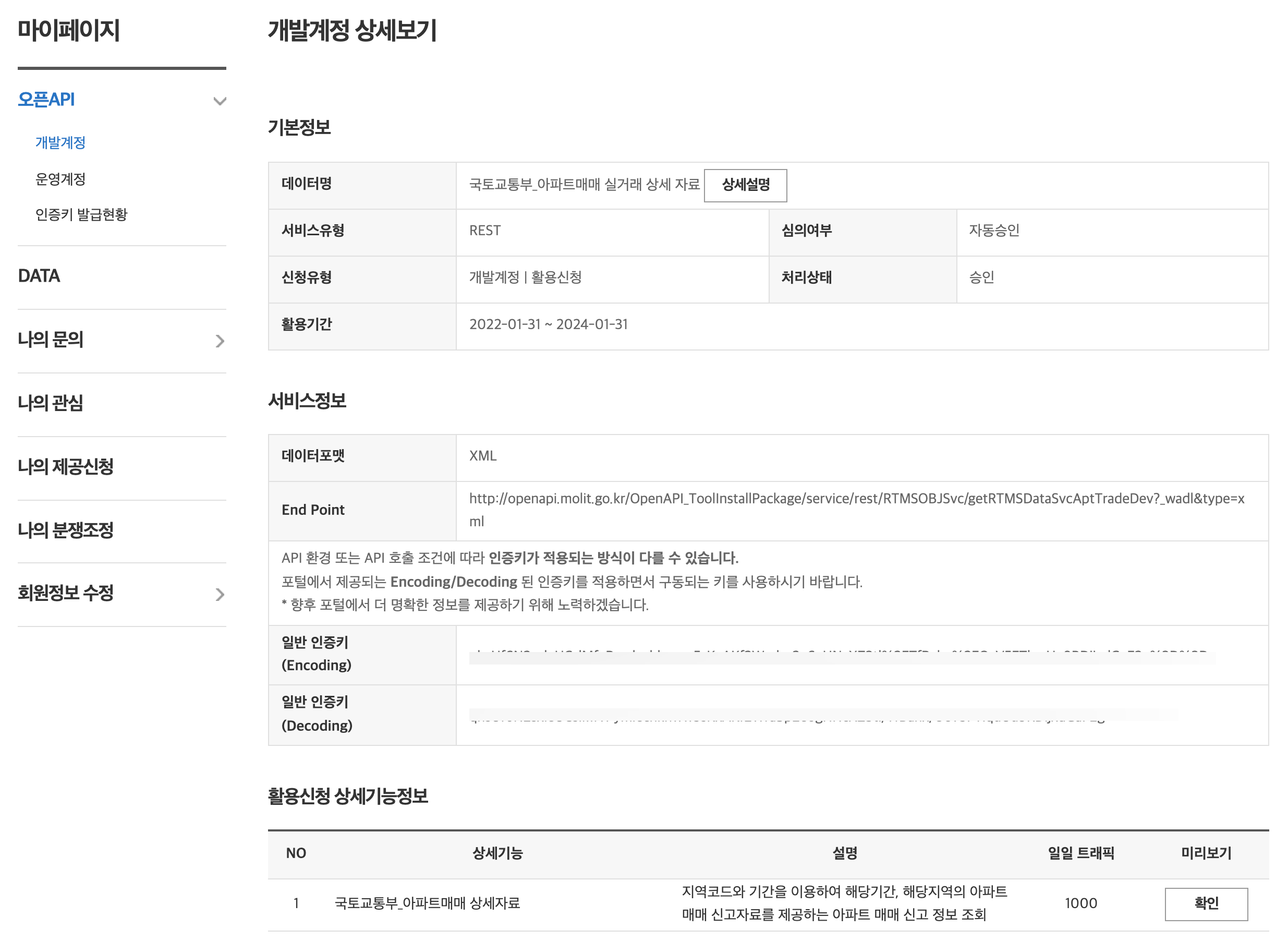
Figure 3: 개발계정 상세보기 화면
아파트매매 실거래 상세 자료 조회 프로그램 개발
요청 URL 생성
XML 출력 포맷을 사용하기 때문에 다음 요청 URL을 사용합니다.
GET 방식의 호출 URL이기 때문에 요청변수 영역을 ?로 구분하고, 요청 변수들은 &로 구분합니다. 요청변수는 다음과 같습니다.
- ServiceKey : 공공데이터포털에서 받은 인증키
- pageNo : 페이지번호
- numOfRows : 한 페이지 결과 수
- LAWD_CD : 지역코드
- DEAL_YMD : 계약월
api <- "http://openapi.molit.go.kr/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/getRTMSDataSvcAptTradeDev"
url <- glue::glue(
"{api}?ServiceKey={auth_key}&pageNo={chunk_no}&numOfRows={chunk}&LAWD_CD={LAWD_CD}&DEAL_YMD={DEAL_YMD}"
)
여기서 한가지 문제가 발생합니다. 서비스를 위해서는 지역코드가 필요합니다. 그나마 아파트 매매 상세자료 조회 기술문서.hwp 파일의 요청 메시지 명세 섹션에 “각 지역별 코드 행정표준코드관리시스템(www.code.go.kr)의 법정동코드 10자리 중 앞 5자리”라고 설명되어 있습니다.
법정동 코드 준비하기
만약에 서울특별시 노원구의 아파트매매 실거래 상세 자료를 조회하기 위해서는 노원구의 지역코드를 알아야 합니다.
행정표준코드관리시스템에서 아주 어렵게 법정동 코드를 조회하는 법정동코드목록조회 화면을 찾았습니다.
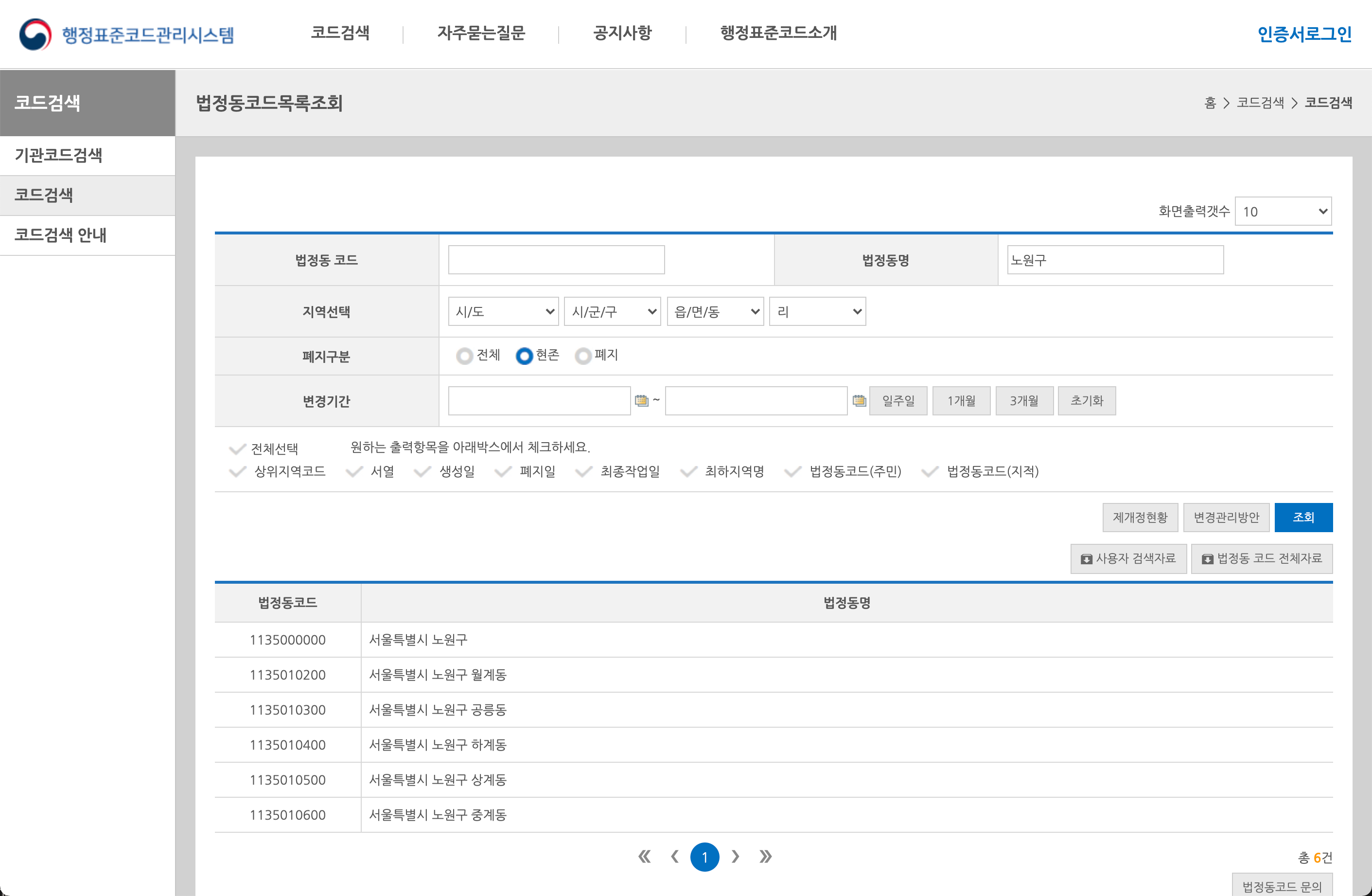
Figure 4: 법정동코드목록조회 화면
노원구의 법정동코드가 “1135000000”임을 알았습니다. 그리고 API를 이용하기 위해서는 이 코드의 앞 다섯자리인 “11350”을 사용해야 합니다. 그런데 매번 특정 지역의 정보를 확인하기 위해서 행정표준코드관리시스템에 접속해야할까요? 그래서 “법정동 코드 전체자료”를 다운로드했습니다.
해당 파일의 압축을 풀고, 데이터 프레임 객체를 만든 다음 R 데이터 파일과 SQLite DBMS의 테이블에 저장해 두었습니다.
library(dplyr)
fname <- here::here("inst", "meta", "법정동코드 전체자료.txt")
legal_divisions <- fname %>%
read.table(sep = "\t", header = TRUE, fileEncoding = "cp949",
col.names = c("DIVISION_ID", "DIVISION_NM", "MAINTAIN")) %>%
mutate(DIVISION_ID = format(DIVISION_ID, scientific = FALSE, trim = TRUE)) %>%
mutate(MAINTAIN = case_when(
MAINTAIN == "존재" ~ "Y",
MAINTAIN == "폐지" ~ "N")
) %>%
mutate(MEGA_CD = substr(DIVISION_ID, 1, 2),
MEGA_NM = stringr::str_extract(DIVISION_NM, "^[\\w]+")) %>%
mutate(CTY_CD = substr(DIVISION_ID, 1, 5),
CTY_NM = stringr::str_extract(DIVISION_NM, " [\\w]+") %>%
stringr::str_remove("\\s")) %>%
mutate(ADMI_CD = substr(DIVISION_ID, 1, 8),
ADMI_NM = stringr::str_remove(DIVISION_NM, "^[\\w]+ [\\w]+ ")) %>%
filter(!stringr::str_detect(DIVISION_ID, "000000$"))
save(legal_divisions, file = "data/legal_divisions.rda")
db_name <- here::here("inst", "meta", "GISDB.sqlite")
con <- DBI::dbConnect(RSQLite::SQLite(), db_name)
DBI::dbWriteTable(con, "TB_LEGAL_DIVISIONS", legal_divisions, overwrite = TRUE)
DBI::dbDisconnect(con)
API 호출
만들어 놓은 url을 XML 패키지의 xmlParse()로 API를 호출합니다. 만약에 호출 결과가 정상이 아닐 경우에는 에러를 발생시킵니다. 이때, 결과에 대한 메시지를 보여줍니다.
doc <- XML::xmlParse(url)
resultCode <- doc %>%
XML::getNodeSet("//resultCode") %>%
XML::xmlValue()
if (resultCode != "00") {
result_msg <- doc %>%
XML::getNodeSet("//resultMsg") %>%
XML::xmlValue()
stop(result_msg)
}
XML 파싱
조회된 매매정보의 건수를 가져옵니다. 지역코드에 따라 매매정보의 건수에 대한 편차가 클 것입니다. 도심의 대규모 아파트단지를 포함한 지역은 매매건수가 많을 것이고, 아파트 수가 적은 지방의 지역은 매매건수가 적을 것입니다.
total_count <- doc %>%
XML::getNodeSet("//totalCount") %>%
XML::xmlValue() %>%
as.integer()
XML 포멧에서는 item 태그로 개별 검색 결과를 반환합니다. 역시 getNodeSet()로 item 노드를 가져다 조작합니다. xmlToDataFrame()가 이들 개별 결과들을 데이터 프레임 객체로 변환합니다.
get_list() 함수를 정의했습니다. 이 함수의 로직은 한글명을 영문 변수명으로 변경하는 로직과 필요한 항목만 가져오는 로직이 있습니다.
get_list <- function(doc) {
doc %>%
XML::getNodeSet("//item") %>%
XML::xmlToDataFrame() %>%
mutate(거래금액 = stringr::str_remove(거래금액, ",") %>%
as.integer()) %>%
mutate(DEAL_DATE = glue::glue(
"{년}-{str_pad(월, width = 2, pad = '0')}-{str_pad(일, width = 2, pad = '0')}")
) %>%
mutate(층 = as.integer(층)) %>%
mutate(건축년도 = as.integer(건축년도)) %>%
select(-년, -월, -일) %>%
select("LAWD_CD" = 지역코드,
DEAL_DATE,
"SERIAL" = 일련번호,
"DEAL_TYPE" = 거래유형,
"BUILD_NM" = 아파트,
"FLOOR" = 층,
"BUILD_YEAR" = 건축년도,
"AREA" = 전용면적,
"AMOUNT" = 거래금액,
"ROAD_CD" = 도로명코드,
"ROAD_NM" = 도로명,
"BUILD_MAJOR" = 도로명건물본번호코드,
"BUILD_MINOR" = 도로명건물부번호코드,
"ROAD_SEQ" = 도로명일련번호코드,
"BASEMENT_FLAG" = 도로명지상지하코드,
"LAND_NO" = 지번,
"DONG_NM" = 법정동,
"DONG_MAJOR" = 법정동본번코드,
"DONG_MINOR" = 법정동부번코드,
"EUBMYNDONG_CD" = 법정동읍면동코드,
"DONG_LAND_NO" = 법정동지번코드,
"DEALER_ADDR" = 중개사소재지,
"CANCEL_DEAL" = 해제여부,
"CANCEL_DATE" = 해제사유발생일)
}
deal_list <- doc %>%
get_list()
다건 처리 로직
다음은 chunk 사이즈보다 큰 다건의 검색 결과 처리를 위한 로직입니다. NAVER 뉴스 검색 로직과 유사합니다.
records <- NROW(deal_list)
if (!do_done | records >= total_count) {
return(deal_list)
} else {
cnt <- total_count %/% chunk
if (total_count %% chunk == 0) {
cnt <- cnt - 1
}
add_list <- (seq(cnt) + 1) %>%
purrr::map_df({
function(x) {
url <- glue::glue(
"{api}?ServiceKey={auth_key}&pageNo={x}&numOfRows={chunk}&LAWD_CD={LAWD_CD}&DEAL_YMD={DEAL_YMD}"
)
XML::xmlParse(url) %>%
get_list()
}
})
deal_list %>%
bind_rows(
add_list
) %>%
return()
}
함수의 완성
이상의 로직을 통합해서 아파트매매 실거래 상세 자료를 조회하는 함수를 다음과 같이 정의하였습니다.
trade_apt <- function(auth_key, LAWD_CD = "11110", DEAL_YMD = "202112",
chunk_no = 1, chunk = 100, do_done = FALSE) {
library(dplyr)
get_list <- function(doc) {
doc %>%
XML::getNodeSet("//item") %>%
XML::xmlToDataFrame() %>%
mutate(거래금액 = stringr::str_remove(거래금액, ",") %>%
as.integer()) %>%
mutate(DEAL_DATE = glue::glue(
"{년}-{str_pad(월, width = 2, pad = '0')}-{str_pad(일, width = 2, pad = '0')}")
) %>%
mutate(층 = as.integer(층)) %>%
mutate(건축년도 = as.integer(건축년도)) %>%
select(-년, -월, -일) %>%
select("LAWD_CD" = 지역코드,
DEAL_DATE,
"SERIAL" = 일련번호,
"DEAL_TYPE" = 거래유형,
"BUILD_NM" = 아파트,
"FLOOR" = 층,
"BUILD_YEAR" = 건축년도,
"AREA" = 전용면적,
"AMOUNT" = 거래금액,
"ROAD_CD" = 도로명코드,
"ROAD_NM" = 도로명,
"BUILD_MAJOR" = 도로명건물본번호코드,
"BUILD_MINOR" = 도로명건물부번호코드,
"ROAD_SEQ" = 도로명일련번호코드,
"BASEMENT_FLAG" = 도로명지상지하코드,
"LAND_NO" = 지번,
"DONG_NM" = 법정동,
"DONG_MAJOR" = 법정동본번코드,
"DONG_MINOR" = 법정동부번코드,
"EUBMYNDONG_CD" = 법정동읍면동코드,
"DONG_LAND_NO" = 법정동지번코드,
"DEALER_ADDR" = 중개사소재지,
"CANCEL_DEAL" = 해제여부,
"CANCEL_DATE" = 해제사유발생일)
}
api <- "http://openapi.molit.go.kr/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/getRTMSDataSvcAptTradeDev"
url <- glue::glue(
"{api}?ServiceKey={auth_key}&pageNo={chunk_no}&numOfRows={chunk}&LAWD_CD={LAWD_CD}&DEAL_YMD={DEAL_YMD}"
)
doc <- XML::xmlParse(url)
resultCode <- doc %>%
XML::getNodeSet("//resultCode") %>%
XML::xmlValue()
if (resultCode != "00") {
result_msg <- doc %>%
XML::getNodeSet("//resultMsg") %>%
XML::xmlValue()
stop(result_msg)
}
total_count <- doc %>%
XML::getNodeSet("//totalCount") %>%
XML::xmlValue() %>%
as.integer()
deal_list <- doc %>%
get_list()
records <- NROW(deal_list)
if (!do_done | records >= total_count) {
return(deal_list)
} else {
cnt <- total_count %/% chunk
if (total_count %% chunk == 0) {
cnt <- cnt - 1
}
add_list <- (seq(cnt) + 1) %>%
purrr::map_df({
function(x) {
url <- glue::glue(
"{api}?ServiceKey={auth_key}&pageNo={x}&numOfRows={chunk}&LAWD_CD={LAWD_CD}&DEAL_YMD={DEAL_YMD}"
)
XML::xmlParse(url) %>%
get_list()
}
})
deal_list %>%
bind_rows(
add_list
) %>%
return()
}
}
함수의 호출
다음은 2021년 4월 서울 용산구의 아파트매매 실거래 상세 자료를 조회하는 예제입니다. 실행하면 100건의 결과를 가져옵니다.
# Your authorized API keys
auth_key <- "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
result <- trade_apt(auth_key, LAWD_CD = "11170", DEAL_YMD = "200603")
다음은 총 312건의 결과를 가져옵니다. 즉, chunk가 300이므로 함수 내부에서 2번의 API 호출이 이루어집니다.
result <- trade_apt(auth_key, LAWD_CD = "11170", DEAL_YMD = "200603", chunk = 300, do_done = TRUE)
미국정보교환표준부호(영어: American Standard Code for Information Interchange), 또는 줄여서 ASCII( /ˈæski/, 아스키)는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다. 아스키는 컴퓨터와 통신 장비를 비롯한 문자를 사용하는 많은 장치에서 사용되며, 대부분의 문자 인코딩이 아스키에 기초를 두고 있다. 출처: https://ko.wikipedia.org/wiki/ASCII↩︎