
들어가기
공공 데이터 및 기업의 인터넷 서비스의 다수가 오픈 API를 통해서 관련 데이터를 제공합니다.이제는 데이터 수집을 위해서 오픈 API를 이용할 수 있는 기술을 습득해야 합니다.
이제 여러분은 NAVER의 오픈 API를 다룰 수 있게 됩니다.
오픈 API
오픈 API(Open Application Programming Interface, Open API, 공개 API) 또는 공개 API는 개발자라면 누구나 사용할 수 있도록 공개된 API를 말하며, 개발자에게 사유 응용 소프트웨어나 웹 서비스의 프로그래밍 적인 권한을 제공합니다.1
수년 전만해도 공동 데이터의 수집과 NAVER 웹 페이지의 데이터를 수집하기 위해서는 웹 페이지를 핸들링하는 기술을 통해서 데이터를 Scraping 해야 했습니다. 그러나 이제는 해당 기관과 업체에서 오픈 API를 제공하기 때문에, 합법적인 방법으로 원하는 데이터를 수집할 수 있는 세상이 되었습니다.
대상 API
- 네이버 뉴스 검색
- 네이버
- 아파트 실거래 데이터 가져오기
- 공공 데이터 포털
네이버 뉴스 검색
네이버 뉴스 검색 결과를 출력해주는 REST API를 이용해서 뉴스 데이터를 수집합니다. Documents > 서비스 API > 검색 > 뉴스에 해당 API에 대한 스팩이 설명되어 있습니다.
API 기본 정보
다음과 같은 두 가지의 API가 있습니다. 여기서는 출력 포맷이 XML인 API를 이용합니다.
| 메서드 | 인증 | 요청 URL | 출력 포맷 |
|---|---|---|---|
| GET | - | https://openapi.naver.com/v1/search/news.xml | XML |
| GET | - | https://openapi.naver.com/v1/search/news.json | JSON |
요청 변수 (request parameter)
| 요청 변수 | 타입 | 필수여부 | 기본값 | 설명 |
|---|---|---|---|---|
| query | string | Y | - | 검색을 원하는 문자열로서 UTF-8로 인코딩 |
| display | integer | N | 10(기본값), 100(최대) | 검색 결과 출력 건수 지정 |
| start | integer | N | 1(기본값), 1000(최대) | 검색 시작 위치로 최대 1000까지 가능 |
| sort | string | N | sim, date(기본값) | 정렬 옵션: sim (유사도순), date (날짜순) |
출력 결과
| 필드 | 타입 | 설명 |
|---|---|---|
| rss | - | 디버그를 쉽게 하고 RSS 리더기만으로 이용할 수 있게 하기 위해 만든 RSS 포맷의 컨테이너이며 그 외의 특별한 의미는 없다. |
| channel | - | 검색 결과를 포함하는 컨테이너이다. 이 안에 있는 title, link, description 등의 항목은 참고용으로 무시해도 무방하다. |
| lastBuildDate | datetime | 검색 결과를 생성한 시간이다. |
| total | integer | 검색 결과 문서의 총 개수를 의미한다. |
| start | integer | 검색 결과 문서 중, 문서의 시작점을 의미한다. |
| display | integer | 검색된 검색 결과의 개수이다. |
| item/items | - | XML 포멧에서는 item 태그로, JSON 포멧에서는 items 속성으로 표현된다. 개별 검색 결과이며 title, originallink, link, description, pubDate를 포함한다. |
| title | string | 개별 검색 결과이며, title, originallink, link, description, pubDate 를 포함한다. |
| originallink | string | 검색 결과 문서의 제공 언론사 하이퍼텍스트 link를 나타낸다. |
| link | string | 검색 결과 문서의 제공 네이버 하이퍼텍스트 link를 나타낸다. |
| description | string | 검색 결과 문서의 내용을 요약한 패시지 정보이다. 문서 전체의 내용은 link를 따라가면 읽을 수 있다. 패시지에서 검색어와 일치하는 부분은 태그로 감싸져 있다. |
| pubDate | datetime | 검색 결과 문서가 네이버에 제공된 시간이다. |
준비사항
- 애플리케이션 등록: 네이버 오픈 API로 개발하시려면 먼저 ‘Application-애플리케이션 등록’ 메뉴에서 애플리케이션을 등록하셔야 합니다.
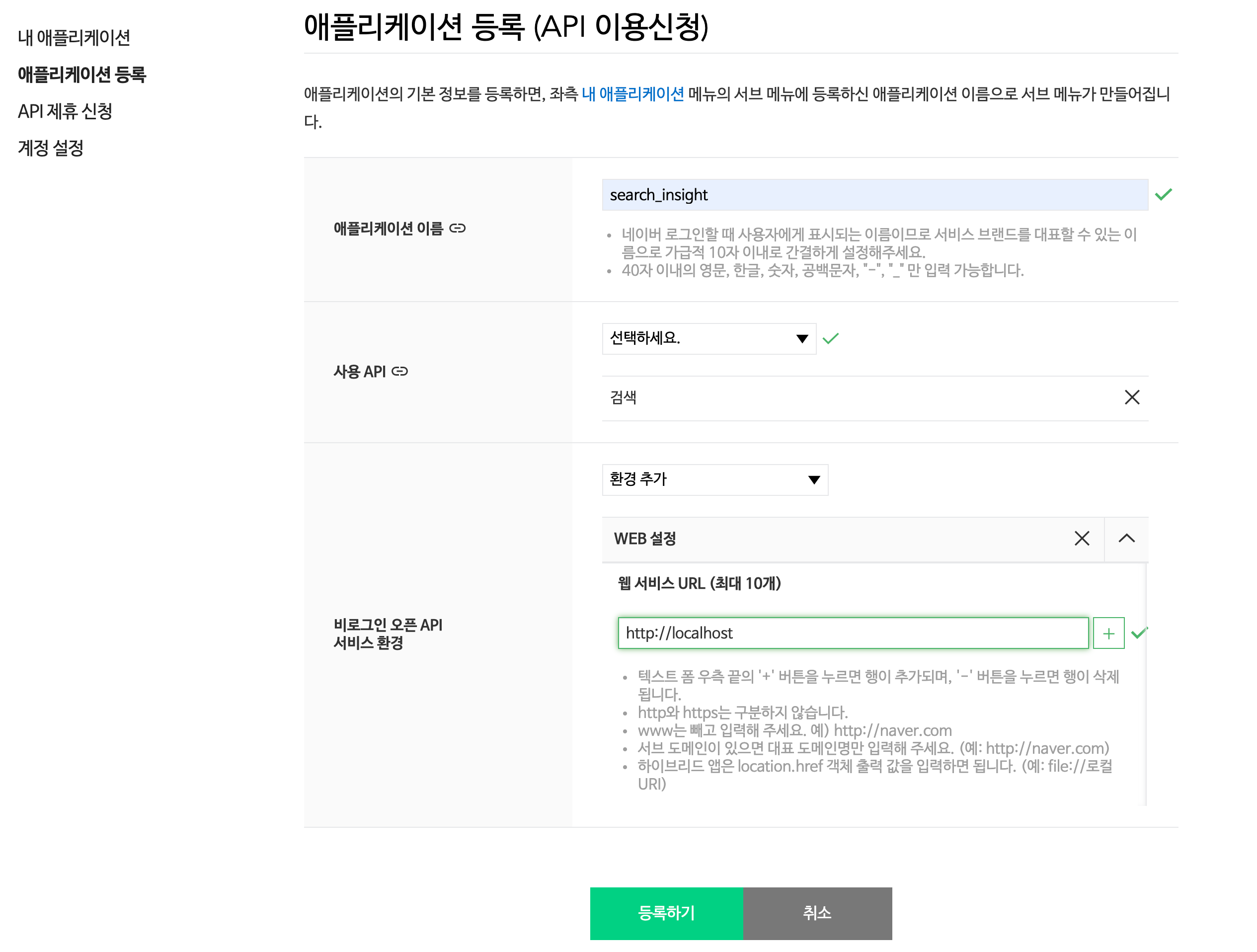
Figure 1: 애플리케이션 등록 (API 이용신청) 화면
- 클라이언트 ID와 secret 확인: ‘내 애플리케이션’에서 등록한 애플리케이션을 선택하면 Client ID와 Client Secret 값을 확인할 수 있습니다.
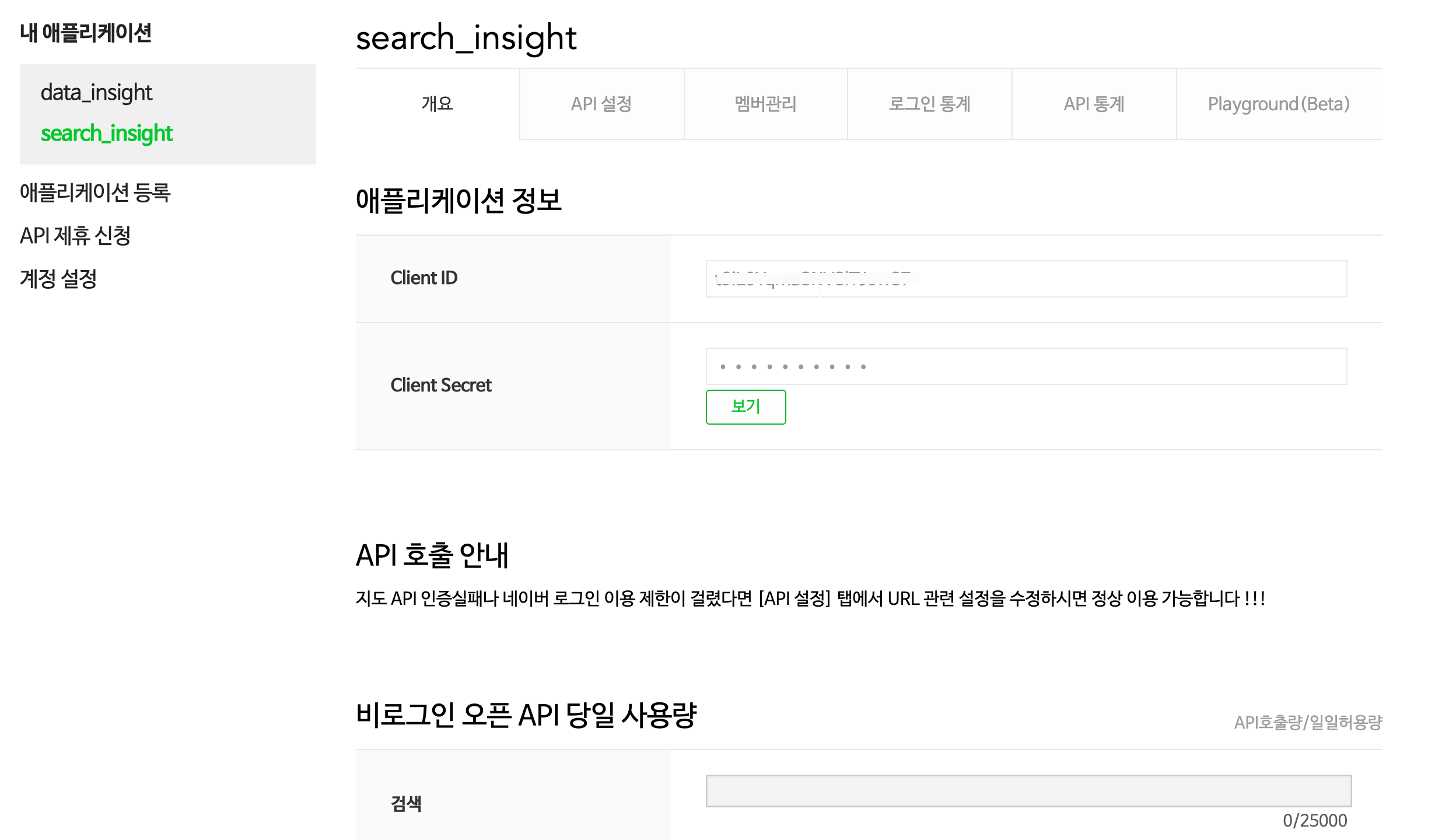
Figure 2: 애플리케이션 정보 화면
이 화면은 중요한 정보를 보여줍니다. 하루에 검색 API 호출이 25000회로 제한되어 있습니다.
주의
클라이언트 아이디(Client ID)와 클라이언트 보안키(Client Secret)는 개인 사용자에게 발급된 정보이므로 반드시 보안에 주의해야 합니다. 타인에게 공개 및 공유하면 안된 중요한 정보이므로 사용에 주의해야 합니다.네이버 뉴스 검색 프로그램 개발
요청 URL 생성
XML 출력 포맷을 사용하기 때문에 다음 요청 URL을 사용합니다.
검색 질의어인 query는 UTF-8로 인코딩해야 하기 때문에 enc2utf8()와 URLencode()을 사용합니다. GET 방식의 호출 URL이기 때문에 요청변수 영역을 ?로 구분하고, 요청 변수들은 &로 구분합니다.
API 호출
GET으로 호출할 때 HTTP Header에 애플리케이션 등록 시 발급받은 Client ID와 Client Secret 값을 같이 전송해야 합니다. 그러므로 httr 패키지를 사용합니다.
XML 파싱
키워드로 검색된 뉴스의 건수를 가져옵니다. 아마도 많은 경우는 대체로 많은 건수의 뉴스가 검색될 것입니다.
검색 결과 문서의 총 개수를 의미하는 total 노드를 가져다가 정수로 변환합니다.
total_count <- doc %>%
XML::getNodeSet("//total") %>%
XML::xmlValue() %>%
as.integer()
XML 포멧에서는 item 태그로 개별 검색 결과를 반환합니다. 역시 getNodeSet()로 item 노드를 가져다 조작합니다.
xmlToDataFrame()가 이들 개별 결과들을 데이터 프레임 객체로 변환합니다.
그리고 다음과 같은 데이터 변환을 수행합니다.
- pubDate:
- 날짜-시간을 표현하는 POSIXct 객체로 변환
- title:
- HTML 태그 들을 제거한 텍스트 생성하여,
- title_text 변수 파생
- description:
- HTML 태그 들을 제거한 텍스트 생성하여,
- description_text 변수 파생
doc %>%
XML::getNodeSet("//item") %>%
XML::xmlToDataFrame() %>%
rename("publish_date" = pubDate) %>%
mutate(publish_date = as.POSIXct(publish_date,
format = "%a, %d %b %Y %H:%M:%S %z")) %>%
mutate(title_text = stringr::str_remove_all(
title, "&\\w+;|<[[:punct:]]*b>")) %>%
mutate(title_text = stringr::str_remove_all(
title_text, "[[:punct:]]*")) %>%
mutate(description_text = stringr::str_remove_all(
description,
"&\\w+;|<[[:punct:]]*b>|[“”]"))
다건 처리 로직
요청 변수의 display는 API 호출에서 가져올 결과의 건수입니다. 한번 호출에 최대 100건까지 가져올 수 있습니다. 그러므로 검색 결과가 100건이 넘는 경우에는 여러번 호출을 통해서 해당하는 모든 건을 가져올 수 있습니다.
이 경우 검색 시작 위치인 start로 분할해서 가져올 페이지 번호를 지정할 수 있습니다. 만약 100건을 가져왔다면 다음 호출의 start는 101이어야 합니다.
start의 최대값은 1000으로 제한되어 있습니다. 그러므로 API로 가져올 수 있는 뉴스의 개별 결과는 100,000건입니다.
- Max(start) * Max(display) = 1000 * 100 = 100,000
주의
R은 눈사람을 만드는 것처럼 데이터를 키워나가면 안됩니다.rbind() 함수를 이용해서 API를 순차적으로 호출하면서 데이터 프레임에 결과를 붙여나가면 안됩니다. R 데이터 프레임에 관측치를 붙여나가면서 데이터를 크게 불리는 작업은 치명적인 성능 감소를 가져옵니다.
다음은 chunk 사이즈보다 큰 다건의 검색 결과 처리를 위한 로직입니다.
purrr 패키지의 map_df()의 프로그래밍 함수를 이용해서, 여러 번 API를 호출합니다. 이 로직은 주의에서 언급한 방법을 회피하는 로직입니다.
search_list <- doc %>%
get_list()
records <- NROW(search_list)
if (!do_done | records >= total_count | records >= max_record) {
return(search_list)
} else {
total_count <- min(total_count, max_record)
cnt <- total_count %/% chunk
if (total_count %% chunk == 0) {
cnt <- cnt - 1
}
idx <- (seq(cnt) + 1)
add_list <- idx[idx <= 1000] %>%
purrr::map_df({
function(x) {
if (verbose) {
glue::glue(" - ({chunk * x}/{total_count})건 호출을 진행합니다.\n\n") %>%
cat()
}
glue::glue(
"{searchUrl}?query={query}&display={chunk}&start={x}&sort={sort}"
) %>%
httr::GET(
httr::add_headers(
"X-Naver-Client-Id" = client_id,
"X-Naver-Client-Secret" = client_secret
)
) %>%
toString() %>%
XML::xmlParse() %>%
get_list()
}
})
search_list %>%
bind_rows(
add_list
) %>%
return()
}
함수의 완성
이상의 로직을 통합해서 네이버 뉴스를 검색하는 함수를 다음과 같이 정의하였습니다.
search_naver <- function(query = NULL, chunk = 100, chunk_no = 1,
sort = c("date", "sim"), do_done = FALSE,
max_record = 1000L, client_id = NULL,
client_secret = NULL, verbose = TRUE) {
if (is.null(query)) {
stop("검색 키워드인 query를 입력하지 않았습니다.")
}
if (chunk < 1 & chunk > 100) {
stop("chunk 요청 변수값이 허용 범위(1~100)인지 확인해 보세요.")
}
if (chunk_no < 1 & chunk_no > 100) {
stop("chunk_no 요청 변수값이 허용 범위(1~1000)인지 확인해 보세요.")
}
sort <- match.arg(sort)
get_list <- function(doc) {
doc %>%
XML::getNodeSet("//item") %>%
XML::xmlToDataFrame() %>%
rename("publish_date" = pubDate) %>%
mutate(publish_date = as.POSIXct(publish_date,
format = "%a, %d %b %Y %H:%M:%S %z")) %>%
mutate(title_text = stringr::str_remove_all(
title, "&\\w+;|<[[:punct:]]*b>")) %>%
mutate(title_text = stringr::str_remove_all(
title_text, "[[:punct:]]*")) %>%
mutate(description_text = stringr::str_remove_all(
description,
"&\\w+;|<[[:punct:]]*b>|[“”]"))
}
searchUrl <- "https://openapi.naver.com/v1/search/news.xml"
query <- query %>%
enc2utf8() %>%
URLencode()
url <- glue::glue("{searchUrl}?query={query}&display={chunk}&start={chunk_no}&sort={sort}")
doc <- url %>%
httr::GET(
httr::add_headers(
"X-Naver-Client-Id" = client_id,
"X-Naver-Client-Secret" = client_secret
)
) %>%
toString() %>%
XML::xmlParse()
total_count <- doc %>%
XML::getNodeSet("//total") %>%
XML::xmlValue() %>%
as.integer()
if (verbose) {
glue::glue("* 검색된 총 기사 건수는 {total_count}건입니다.\n\n") %>%
cat()
glue::glue(" - ({chunk}/{min(total_count, max_record)})건 호출을 진행합니다.\n\n") %>%
cat()
}
search_list <- doc %>%
get_list()
records <- NROW(search_list)
if (!do_done | records >= total_count | records >= max_record) {
return(search_list)
} else {
total_count <- min(total_count, max_record)
cnt <- total_count %/% chunk
if (total_count %% chunk == 0) {
cnt <- cnt - 1
}
idx <- (seq(cnt) + 1)
add_list <- idx[idx <= 1000] %>%
purrr::map_df({
function(x) {
if (verbose) {
glue::glue(" - ({chunk * x}/{total_count})건 호출을 진행합니다.\n\n") %>%
cat()
}
glue::glue(
"{searchUrl}?query={query}&display={chunk}&start={x}&sort={sort}"
) %>%
httr::GET(
httr::add_headers(
"X-Naver-Client-Id" = client_id,
"X-Naver-Client-Secret" = client_secret
)
) %>%
toString() %>%
XML::xmlParse() %>%
get_list()
}
})
search_list %>%
bind_rows(
add_list
) %>%
return()
}
}
함수의 호출
다음은 불평등이라는 단어가 포함된 네이버 뉴스를 검색하는 예제입니다. 실행하면 100건의 결과를 가져옵니다.
# Your authorized API keys
client_id <- "XXXXXXXXXXXXXXXXXXXXXXX"
client_secret <- "XXXXXXXXX"
search_list <- search_naver(
"불평등", client_id = client_id, client_secret = client_secret
)
다음은 불평등이라는 단어가 포함된 네이버 뉴스를 검색하는 예제입니다. 총 3000건의 결과를 가져옵니다. 그러므로 함수 내부에서 30번의 API 호출이 이루어집니다.
search_list <- search_naver(
"불평등", client_id = client_id, client_secret = client_secret,
do_done = TRUE, max_record = 3000
)