Dataholic
장강의 뒷물이 앞물을 밀어내며 흐르고
새로운 기술이 태동하여 기존의 방법을 대체하는 과정에서 나는 익숙했던 기존 방법을 고수하다가, 왜 좀 더 일찍 새로운 기술을 받아들이지 않았는가하는 생각을 하기도 합니다. 생각컨데 익숙함과 새로움 사이에서 적당한 줄타기를 해야하는 시대임은 틀림이 없습니다.

잃어버린 30분
데이터 타입이 날짜-시간인 데이터를 다루는 것은 여간 성가시지 않습니다. 그런데도 아주 가끔 사용하는지라 작업을 할 때마다 새롭기만 합니다. 그런데, 날짜-시간 데이터에 심오한 것이 숨어 있더군요. 무엇이 또 즐겁게 해줄까요?

고아 패키지를 아시나요?
R 패키지에도 고아가 있는 것을 알았습니다. 부모가 없는 즉, 관리자가 없는 패키지를 고아 패키지라 부르더군요. 어떻게 알아냈는지 궁금하시죠? 자세하게 알려드립니다.

R 패키지 개발의 희노애락
R 패키지를 개발하고 유지보수하는 패키지 관리자는 여러 이벤트에 접하게 됩니다. 즐겁고 보람있는 일도, 아쉽고 안타까운 일들도 접하게됩니다. 며칠 사이로 발생했던 그 이야기를 공유합니다.

learnr에서 한글 사용하기
learnr 패키지는 R 환경에서 데이터 분석 학습 튜토리얼이나 자기주도학습 교재를 만들기 위한 훌륭한 도구입니다. 물론 학습교재 저작에서 컨텐츠는 한글로 작성하겠으나, 메시지나 위젯은 영문으로 출력됩니다. 이제 이 영문 출력을 한글로 바꿔보시기 바랍니다.

한국 주가정보 가져오기
동학개미를 위한 국내 주식 시장의 거래 정보를 수집하고, 이 데이터를 이용해서 수익률과 Value-at-Risk, 연간 성장률을 구하는 방법을 다루어 봅니다.

미국 주가정보 가져오기
필자는 재테크에는 재능이 없습니다. 주식 투자도 하지 않습니다. 그러나 최근에는 동학개미, 서학개미라는 사회 이슈적인 신조어를 심심치 않게 듣습니다. 2017년도 금융 데이터 수집을 위해서 국내외 데이터 수집을 위한 프토토타입을 만든 적이 있습니다. 그 때의 기억을 소환해서 서학개미가 관심있을 미국 주식 데이터를 수집하는 방법을 다룹니다.

불암산 트래킹
노원구는 서울의 여러 명산으로서의 접근성이 높습니다. 주말에 노원구에 위치한 불암산 둘레길을 트래킹하였습니다. 가까운 곳에 소소한 행복을 누릴 수 있는 자연이 있어 즐거운 하루였습니다.
deprecated 종속성 오류 해결하기
dlookr 0.5.5 버전을 CRAN에 제출했습니다. 정상적으로 여러 패키지로 빌드되는 중에서, 이슈를 해결하라는 메일을 받았습니다. 이슈의 원인과 해결하는 방법을 살펴봅니다.

GitHub 개인 액세스 토큰 변경
GitHub의 개인 액세스 토큰을 변경한 후, R 환경에서 git에 토큰을 등록해서 RStudio에서 Github을 연동하는 방법을 다룹니다.

TensorFlow용 Metal 플러그인
궁하면 통한다고 했나요? 맥에 탑재된 AMD GPU가 딥러닝 분야에서 무용지물이었는데, 이제 하나둘씩 활용할 수 있는 대안이 나오고 있습니다. PlaidML에 이어서 tensorflow-metal PluggableDevice로 맥의 AMD GPU를 딥러닝 학습에 사용하는 방법을 다룹니다.
R을 위한 Python 설치하기
R과 Python은 데이터 분석을 위한 상호 보완재라고 생각합니다. 물론 단일 솔루션을 사용하여 데이터 분석을 수행할 수도 있으나, 서로의 장단점을 이해하고 적절하게 섞어 쓰면 좀더 효율적인 데이터 분석을 수행할 수 있습니다. 그래서 이번에는 R을 위한 Python을 설치하는 방법을 다룹니다.
맥북에서 GPU를 이용해서 딥러닝 수행하기
CUDA를 사용하는 Nvidia의 GPU가 딥러닝 세상을 평정한 지금, 맥북에 설치되어 있는 AMD GPU를 사용해서 딥러닝 학습을 수행할 수 있다는 것 만으로도 의미가 있습니다.
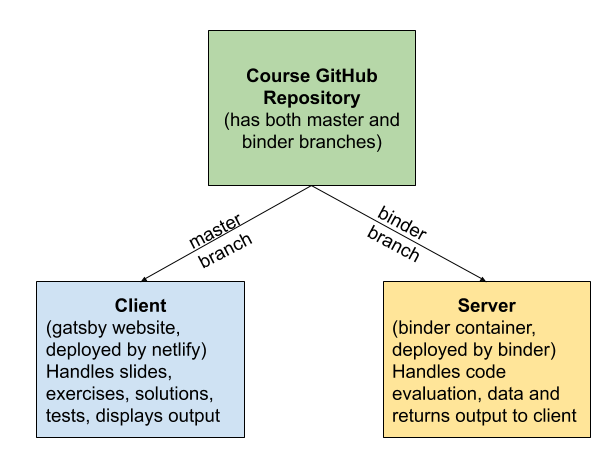
코스 서비스 배포하기
개발한 코스 서비스를 배포하여, 수강자가 코스 학습을 할 수 있는 환경을 구축합니다.
코스 커스트마이징하기
코스 템플리트를 사용자의 코스로 커스트마이징합니다.
코스 템플리트 실행하기
이네스 코스 개발 환경에서 코스 템플리트 앱을 실행합니다.
코스 개발환경 구축하기
이네스 코스 개발 환경을 구축합니다.

이네스 코스 플랫폼 이해
이네스 코스 플랫폼의 구성과 매커니즘을 이해합니다.
learnr 코스 플랫폼 이해
learnr 코스 플랫폼의 구성과 매커니즘을 이해합니다.
온라인 대화형 코스 플랫폼
온라인 데이터 과학 학습 플랫폼인 데이터캠프(DataCamp)는 R과 Python의 학습 커리큘럼이 풍부합니다. 그러나 2017년 CEO의 성추행 사건을 계기로, 몇몇 코스 컨텐츠 프로바이더들이 DataCamp와 결별하고 이네스 몬타니(Ines Montani)의 코스 플랫폼을 만들어 무료로 배포하고 있습니다.

배치 처리하기
R 스크립트를 배치 작업으로 수행해 봅니다. 이 방법은 정기적으로 데이터를 수집할 때 유용한 기법입니다.
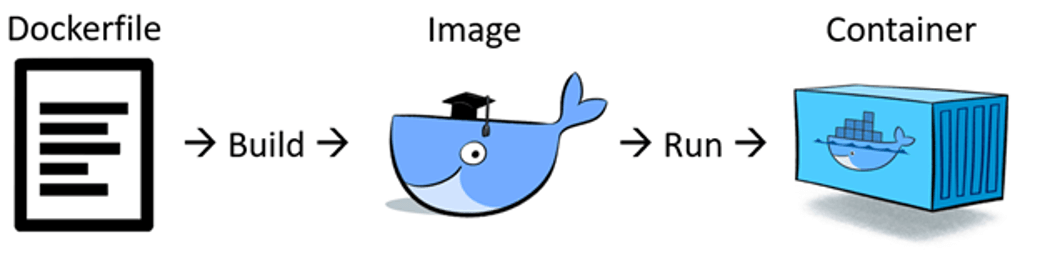
docker 이미지 만들기
Shiny 애플리케이션에 필요로 하는 R 패키지를 추가로 설치하여 새로운 docker 이미지를 생성합니다.

docker 컨테이너 환경 설정하기
docker 기반으로 Shiny 서버를 운영하기 위한 컨테이너 환경설정을 수행합니다.
docker 이미지 설치하기
docker 기반으로 Shiny 서버를 운영하기 위한 기초작업을 수행합니다.
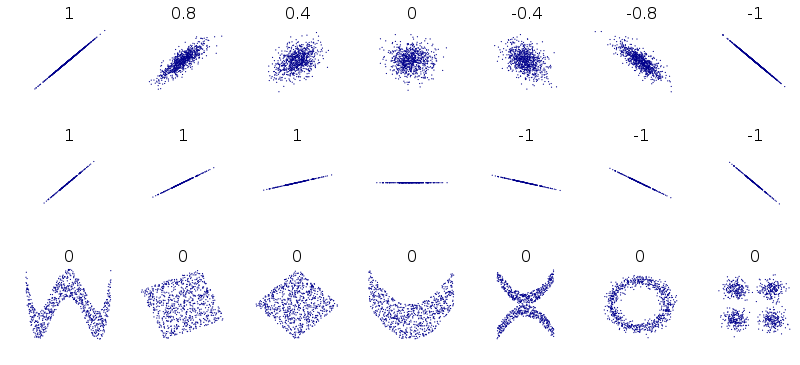
예측력 점수에 대해서
dlookr 0.5.5 버전에 예측력 점수관련 기능을 추가했습니다. 이제는 dlookr로 EDA 과정에서 예측력 점수를 사용할 수 있습니다. 예측력 점수는 비선형 상관관계를 파악할 수 있는 유용한 통계량입니다.
반응 출력
반응 출력을 이해합니다. 랜더링 함수의 종류와 기능도 숙지해야 합니다.
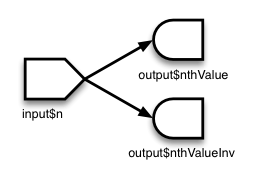
위젯 추가하기
위젯을 이해합니다. 입력 위젯을 패널에 추가하는 방법을 숙지해야 합니다.

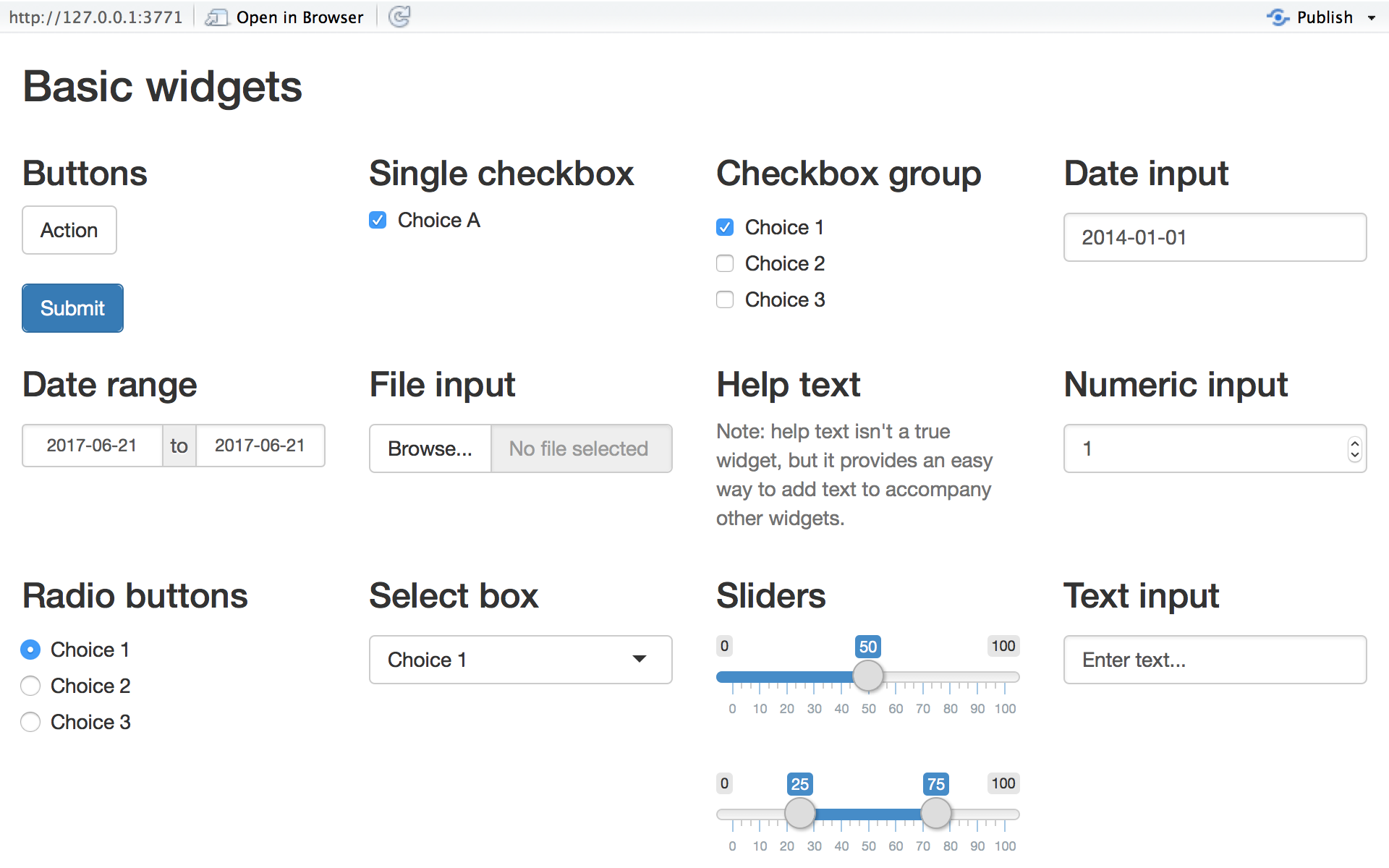
사용자 인터페이스 만들기
사용자 인터페이스(UI)를 이해합니다. page, layout, panel을 숙지해야 합니다.

Shiny 아키텍처 이해
Shiny 아키텍처를 이해합니다. UI, server, 입력 위젯(input widget), 출력 위젯(output widget), 렌더링(Rendering) 정도는 숙지해야 합니다.
distill 패키지의 활용
distill 패키지를 사용해서 Knowledge Base 구축을 위한 홈페이지를 만듭니다.

마크다운 태그 이해하기
마크다운 태그로 다양한 서식의 문서를 문들 수 있습니다.

YAML 이해하기
YMAL 헤더의 변경으로 문서의 형식과 모양이 바꾸는 것을 이해합니다.
청크 옵션 이해하기
knitr R 코드 청크의 옵션을 활용하는 방법을 익힙니다.

첫 R 마크다운 문서 만들기
RStudio에서 R 마크다운 문서를 활용하는 방법을 익힙니다.

Submit R package to CRAN
개발한 R 패키지를 CRAN에 등록하는 방법을 살펴봅니다.

R 패키지 개발하기
몇 가지 Open API를 이용한 데이터 수집 기능을 구현한 R 패키지를 만들어 봅니다.
R 코딩 스타일 가이드
패키지 개발에 앞서서, 중요하지만 간과하는 R 코딩 스타일을 살펴봅니다.

공공데이터포털 오픈 API를 이용한 데이터 수집
공공데이터포털 오픈 API를 이용한 데이터 수집 로직을 구현해 봅니다.

네이버 오픈 API를 이용한 데이터 수집
네이버 오픈 API를 이용한 데이터 수집 로직을 구현해 봅니다.

Wrangle factor with forcats
forcats 패키지로 범주형 데이터를 조작합니다.

Operate string with stringr
stringr 패키지로 문자를 조작하는 방법을 숙지합니다.

Functional programming with purrr
purrr 패키지로 함수형 프로그램하는 방법을 숙지합니다.

Wrangle data with tidyr
tidyr 패키지로 데이터를 정형화하는 방법을 숙지합니다.

Wrangle data with dplyr
dplyr 패키지로 데이터를 조작하는 방법을 숙지합니다.

Import data with readr
readr 패키지로 데이터를 R로 가져오는 방법을 숙지합니다.
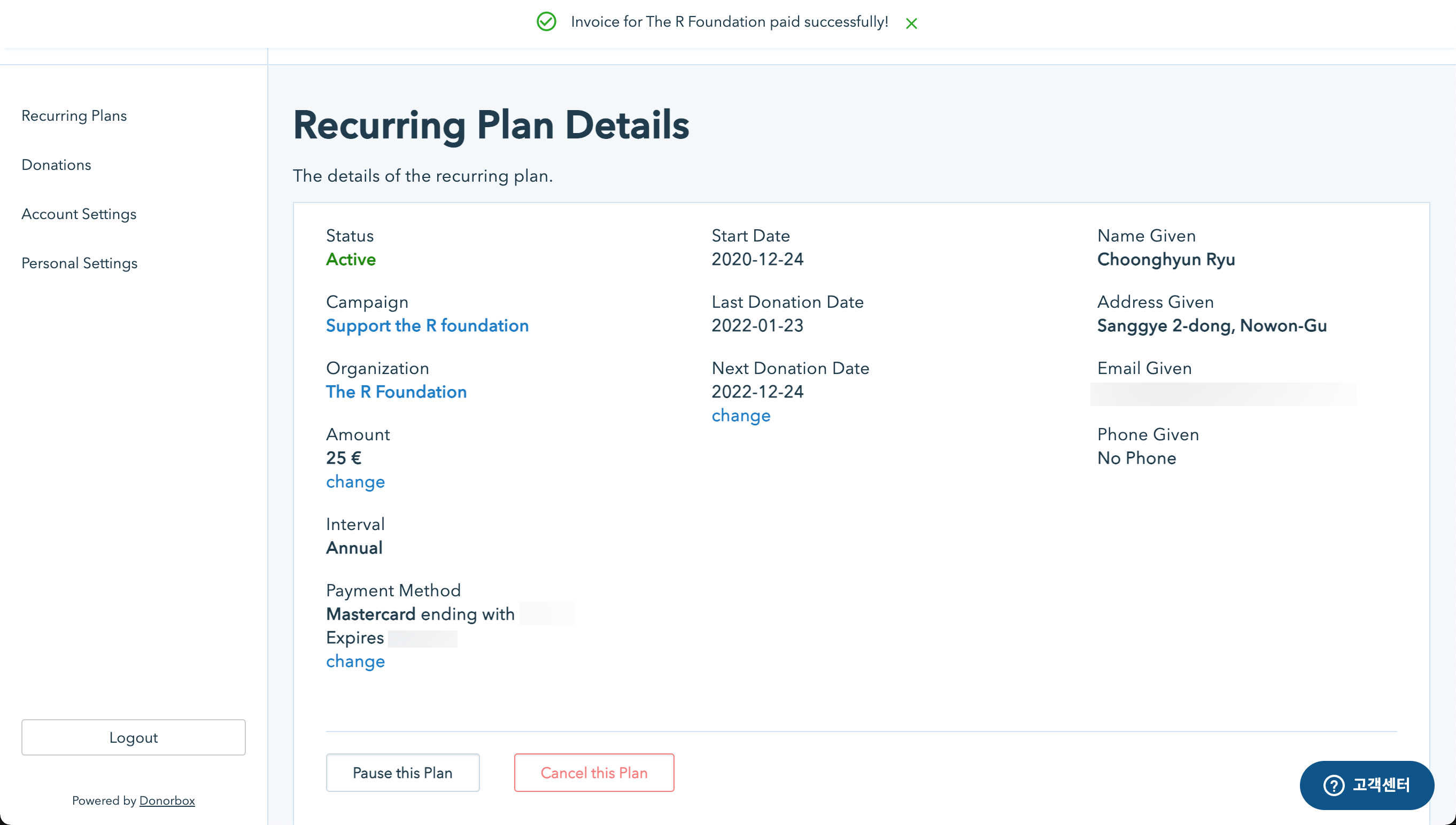
R 재단에 기부하기
우리가 사항하는 즐겨 사용하는 R을 위해서 R 재단에 기부하는 방법을 살펴봅니다.
Shiny 애플리케이션 서버에서 구동하기
로컬 호스트에서 구동되는 Shiny 애플리케이션을 Remote 서버에서 구현할 때의 이슈와 대안을 살펴봅니다.
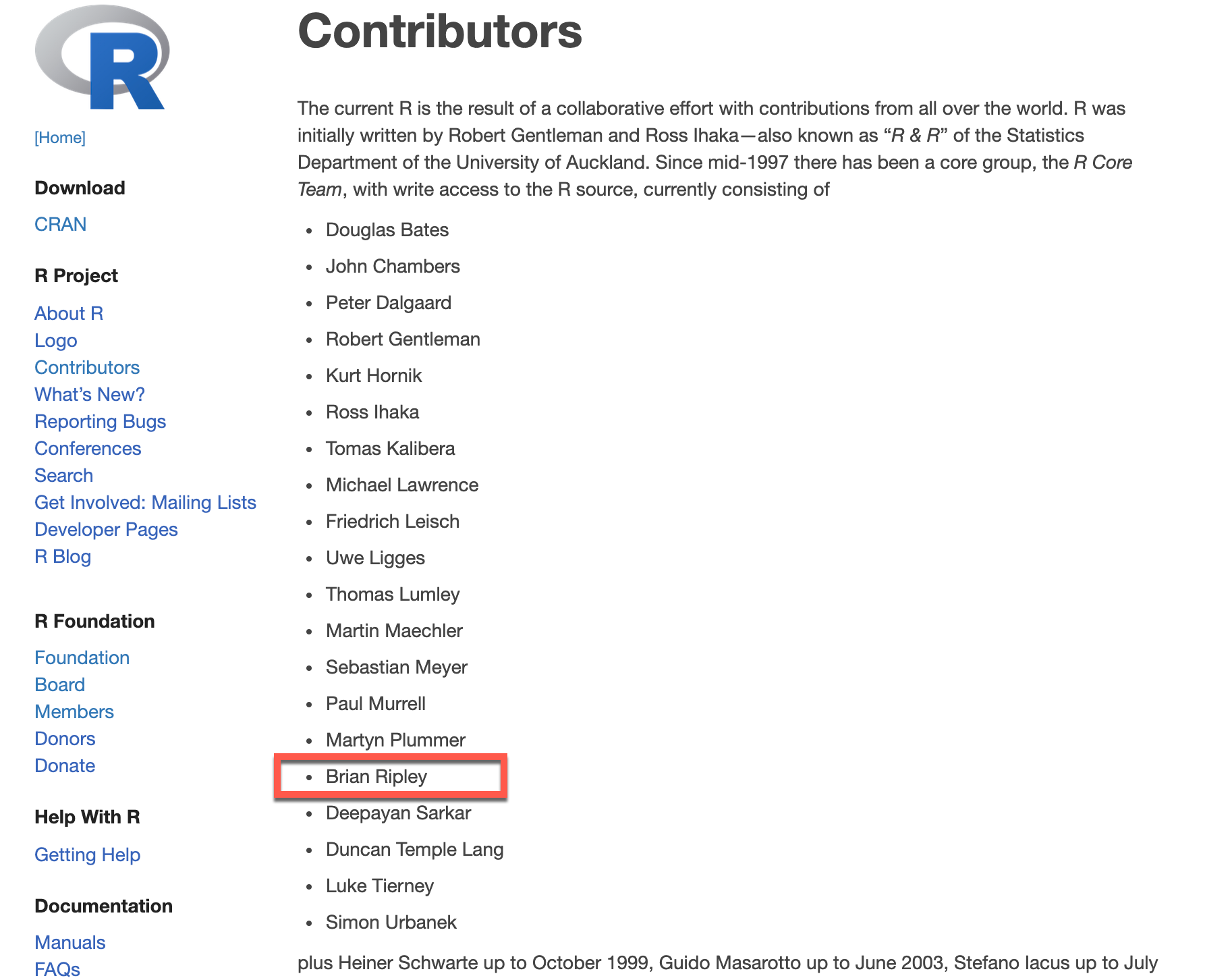
R 패키지 유지보수하기
CRAN에 올라간 패키지를 유지보수하는 에피소드를 소개합니다.

R Markdown의 이해
재현가능한 연구의 개념과 Sweave, knitr, rmarkdown을 통해 R Markdown을 이해합니다.
distill을 이용한 블로깅
"그동안 blogdown 패키지를 이용해서 블로그를 운영해왔으나, 이번에 distill 패키지를 이용해서 블로그를 리뉴얼했습니다. 사실 그동안 블로그 운영이 활발하지 않았습니다. 이번 리뉴얼을 계기로 좀 더 분발해 보겠습니다."
Wireframe 도구 PowerMockup 소개
"웹앱이나 앱을 개발할 때 UI/UX를 설계를 목적으로 화면 단위의 레이아웃을 디자인하는 것을 와이어프레임(wireframe)이라 합니다. 와이어프레임이 좀더 정적으로 구체화되면 목업(mockup)이라고 합니다. 용어는 차이가 있으나 두 개 모두 화면을 설계한다는 것에는 차이가 없습니다."
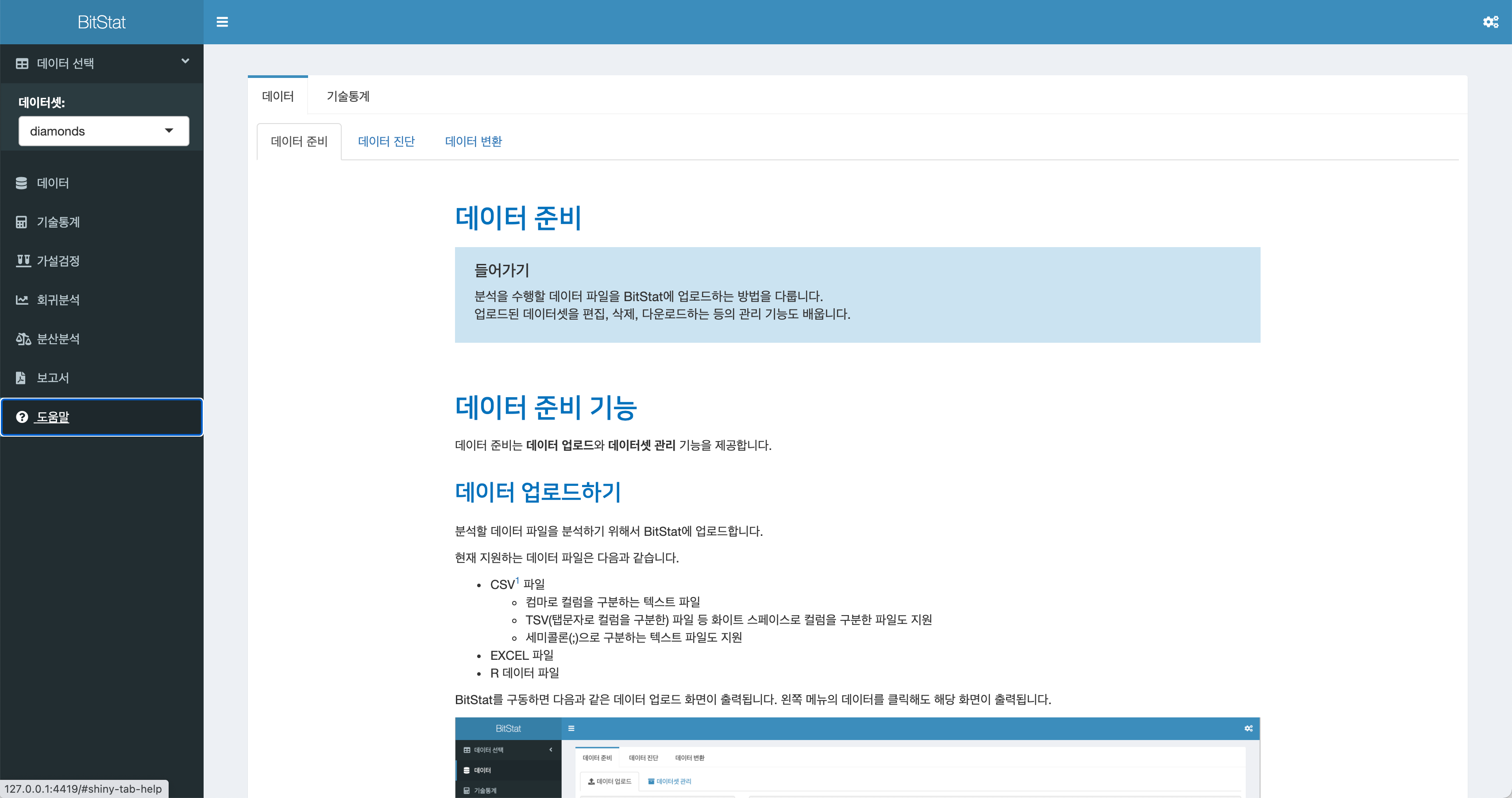
Shiny 웹앱에 정적 HTML 문서 넣기
"Shiny 웹앱을 개발할 때, 기능에 대한 설명을 위한 도움말 기능의 구현이 필요할 수 있다. 아마도 Rmarkdown으로 HTML 기반의 웹 문서를 떠올릴 것이다. 이 글에서 해당 솔루션을 제시한다."
glm predict 시 발생하는 에러 사례
"이진분류에 lasso regression을 이용하기 위해서 glmnet 패키지를 이용하여 모델을 적합한 후 predict할 경우에 발생할 수 있는 오류와 해결 방법을 제시한다."
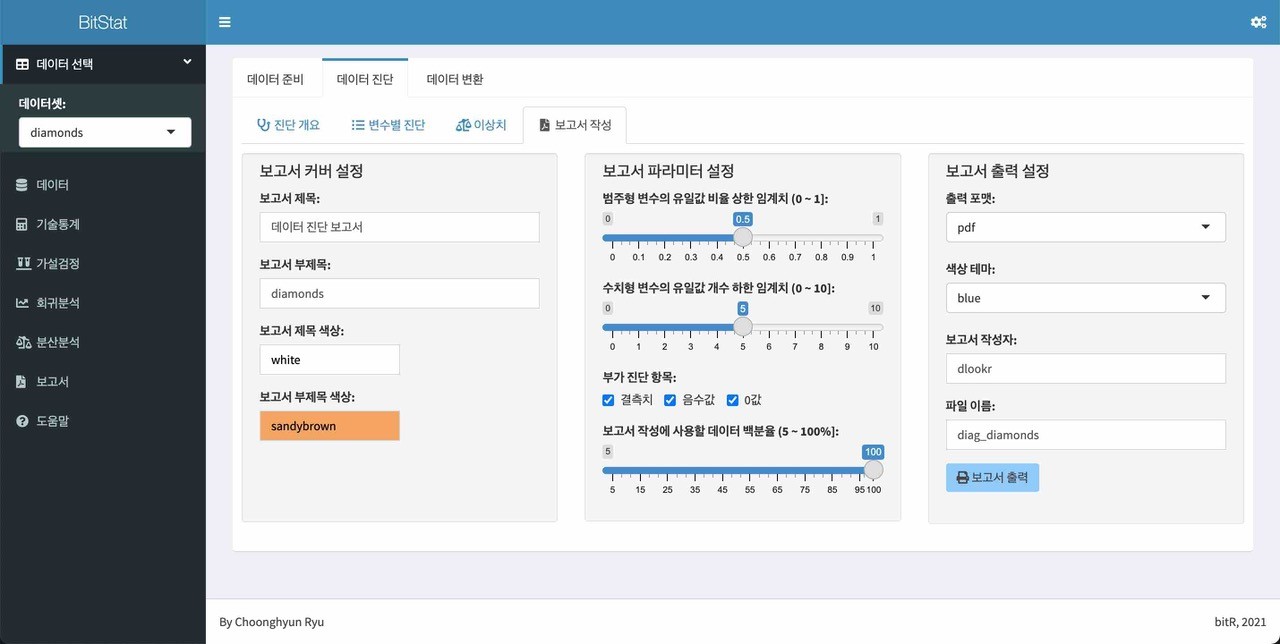
BitStat 패키지 소개
"부족함이 많이 있다. 하지만 이 책이 훌륭한 통계적 알고리즘의 개발과 성능 좋은 한국형 통계분석기 개발에 일말의 보탬이 되었으면 좋겠다. 한 것 없이 길고 고독한 시간이었다. 이제 밖에 나가 쏟아지는 별들을 가슴에 담고 들어오리라. 통계분석기도 만들어 봐야겠다. 언제까지나 SAS만 돌릴 수 없을 테니까."
ggplot과 동적 데이터
"R 데이터 분석에서의 시각화는 ggplot2 패키지다." 이 명제는 부정할 수 없는 현실이다. lattice 패키지가 S-PLUS의 Trellis 그래프를 R에 구현하였기에 늘 감사한 마음으로 애용했었다. 그런데 언젠가부터 ggplot2 패키지가 lattice 패키지를 대체하게 되었고, 이제는 ggplot2 패키지 이전과 이후로 나눌 정도로 표준이 되어 버렸다.
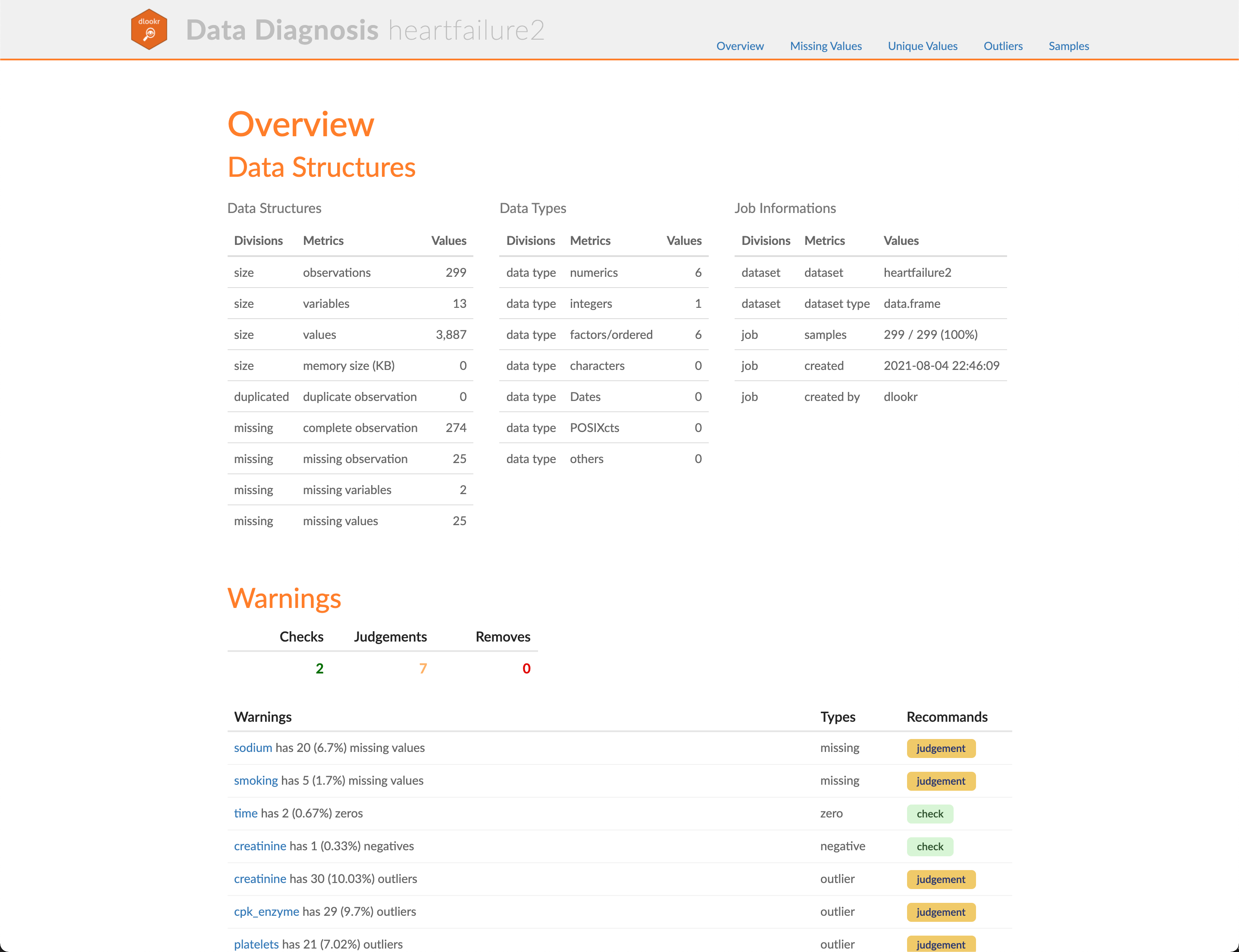
dlookr과 데이터분석 리포트
0.5.0 버전에서는 데이터 진단, EDA, 데이터 변환을 지원하는 리포트의 개선이 가장 두드러진 변화다. 이번 포스트에서 변화된 새로운 리포트에 대해서 소개한다.

수치 정밀도에 대해서
R의 수치연산에서 32-비트의 정수와 IEC 60559 스팩의 부동 소수점(배정밀도)의 산술연산을 사용한다. R이 설치된 모든 머신에서 공통적으로 적용된다.
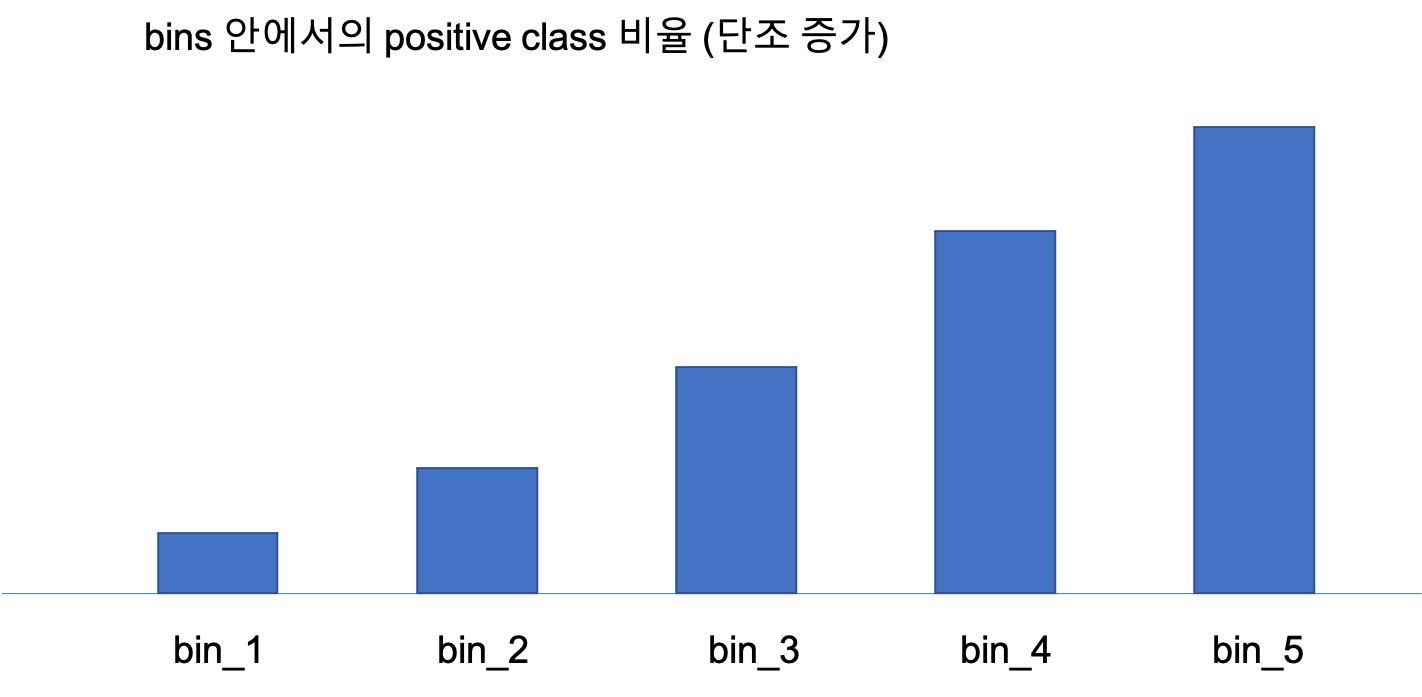
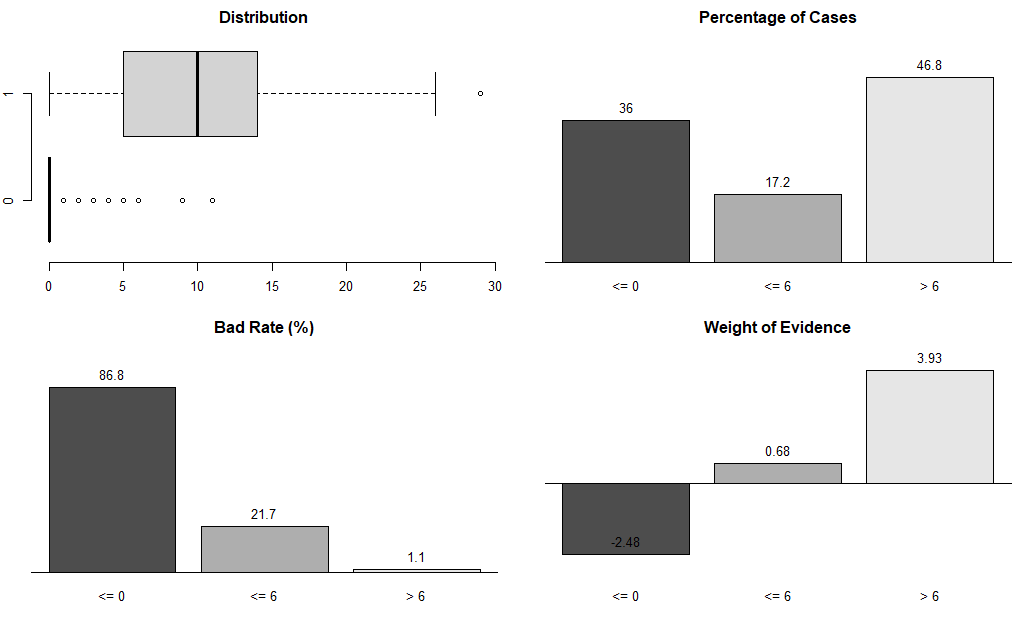
스코어카드와 최적 비닝
금융권에서 사용하는 스코어카드(scorecard) 기법에서는 연속형 변수를 범주형 변수로 변환하는 작업을 빈번히 사용한다. 이번에는 일반적인 비닝 방법이 아닌 최적 비닝(optimal binning) 방법을 사용한다.
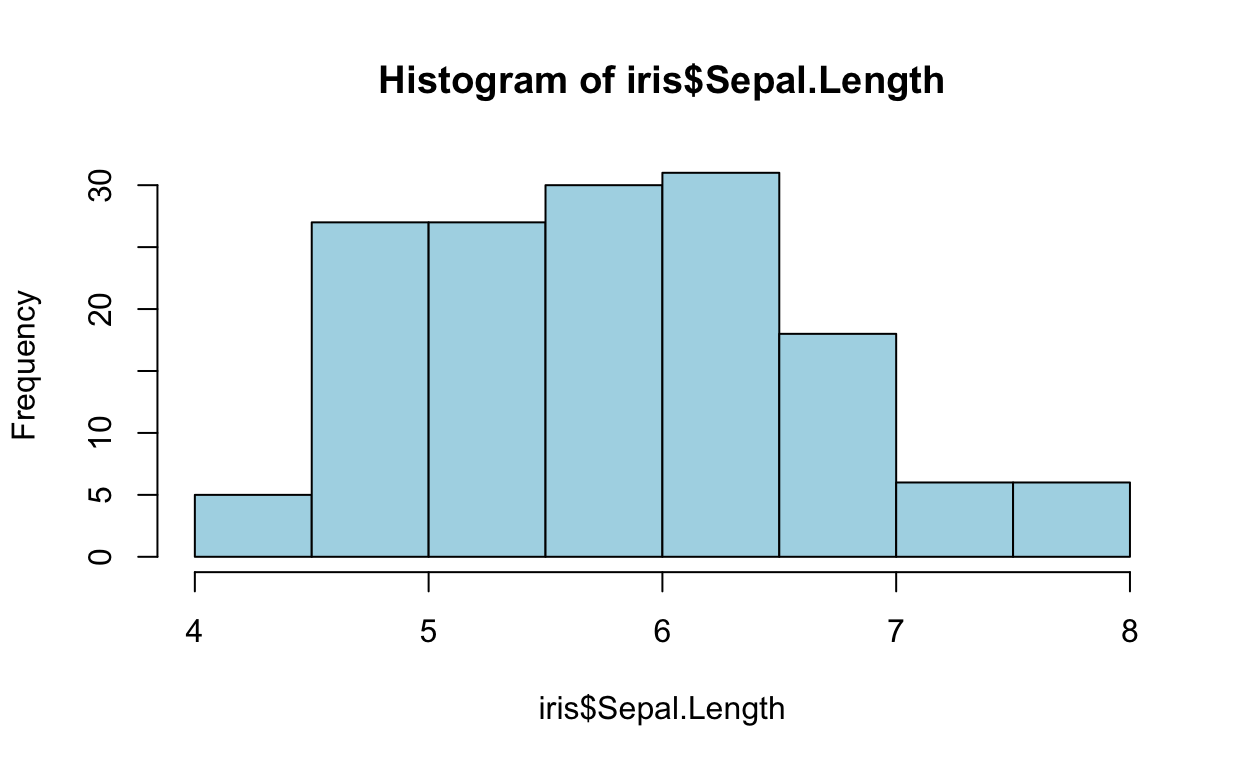
비닝(Binning)
모든 경우는 아니지만 연속형 변수를 비닝하면, 데이터의 분포에 따라서 이상치(outliers)로 발생할 수 있는 이슈를 회피하거나 과적합(over fitting)을 완화시켜주기도 한다. 그래서 흔하지 않지만, 가끔은 연속형 변수를 범주형 변수로 변환할 필요가 있다. 특히 금융권에서 사용하는 스코어카드 기법에서는 연속형 변수를 범주형 변수로 변환하는 작업을 빈번히 사용한다.
추가 폰트 사용하기
R로 그린 플롯에서 우리는 기하학적인 요소로 데이터의 현황을 이해한다. 그런데 라벨이나 제목, 범례, 축의 구간 단위에 표현하는 텍스트도 데이터를 이해하는 데 중요한 역할을 한다. 플롯의 텍스트는 폰트로 그리는데, R에서의 폰트와 폰트를 시각화하는 매커니즘을 다룬다.
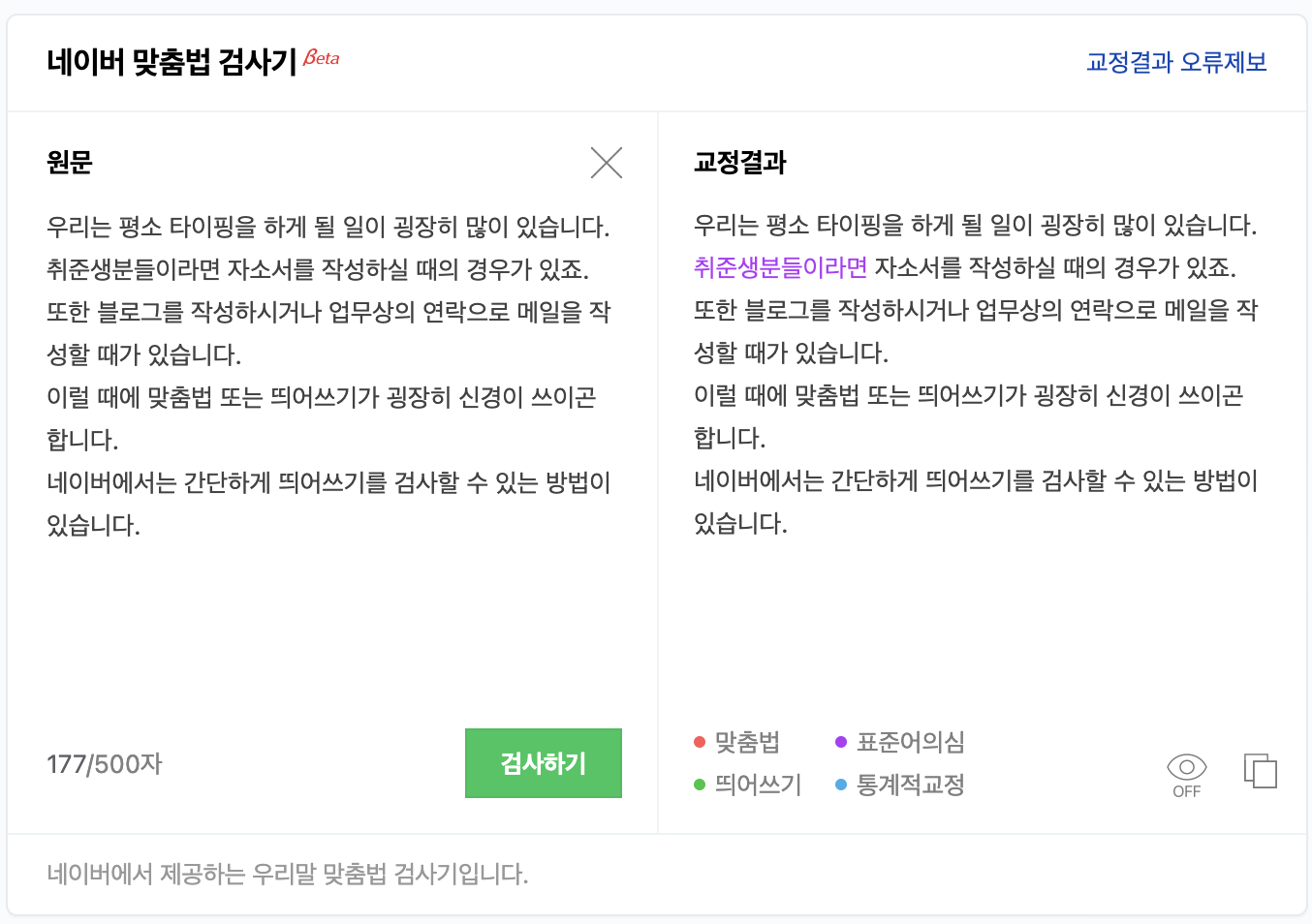
Mecab으로 한글 띄어쓰기 검사기 만들기
한글 띄어쓰기는 정말 어려운 작업이다. 한글은 영어처럼 독립된 단어 기반의 언어가 아니라 조사, 접두어, 접미어 등이 결합되어 구현되기 때문에 정확한 띄어쓰기 구사를 장담하기 어렵다. 그래서 여러 맞춤법 검사 엔진이 개발되어 배포되거나, 포탈 등의 채널에서 서비스로 제공되고 있다.

겸제 정선의 울산바위
고등학교 역사 시간에 조선시대 산수화가인 `겸제 정선`의 `진경산수화(眞景山水畵)`에 대해서 배운 적이 있다. 요즘은 인터넷 검색을 통해서 쉽게 겸제의 작품을 감상할 수 있지만 그 시절은 유면 화가의 작품을 교과서가 아닌 곳에서 쉽게 접할 수 없었다. 나는 아직도 그 시절 교과서에 실린 `인왕제색도`의 감동은 아직도 잊지 못한다.
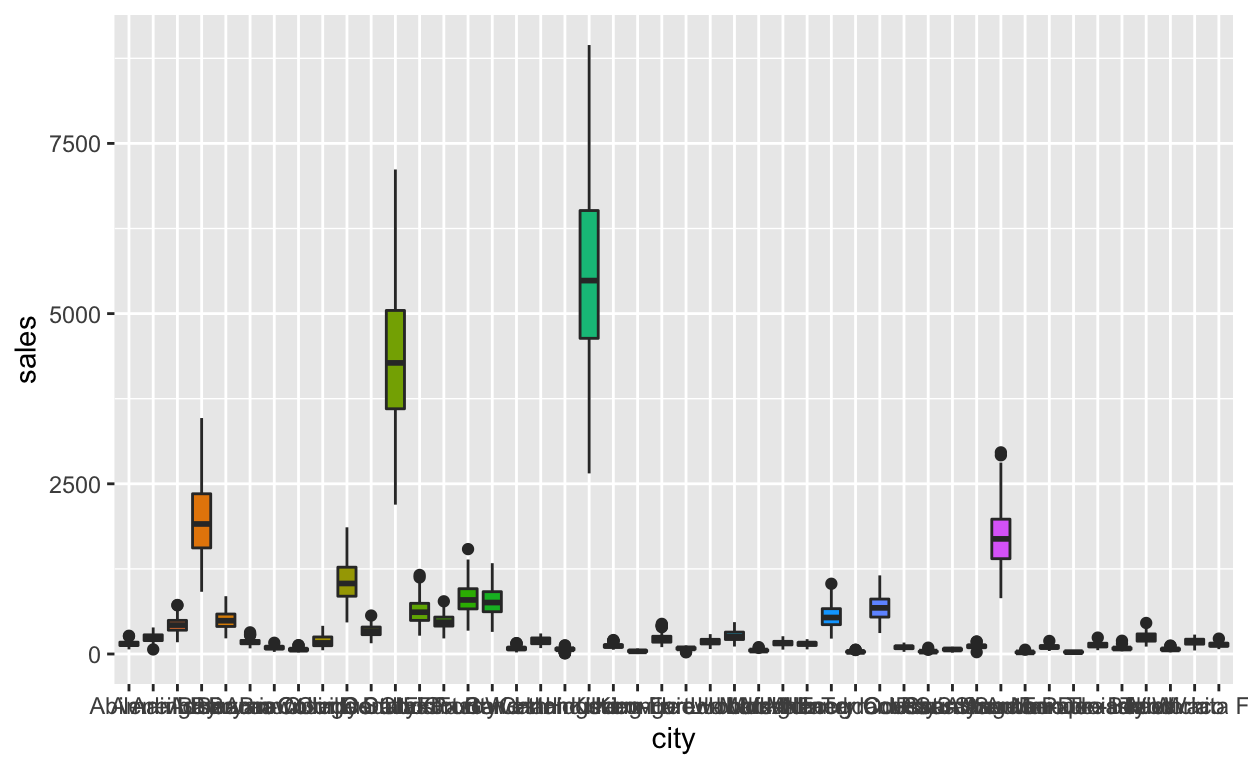
몇 개의 ggplot tips
R에서 데이터를 조작할 때, 가장 까다로운 것이 범주형 데이터를 표현하는 factor다. 이번 이야기에서는 시각화를 위해서 factor를 다루는 방법과 몇몇 ggplot2 패키지를 사용할 때의 몇 가지 팁을 소개한다.
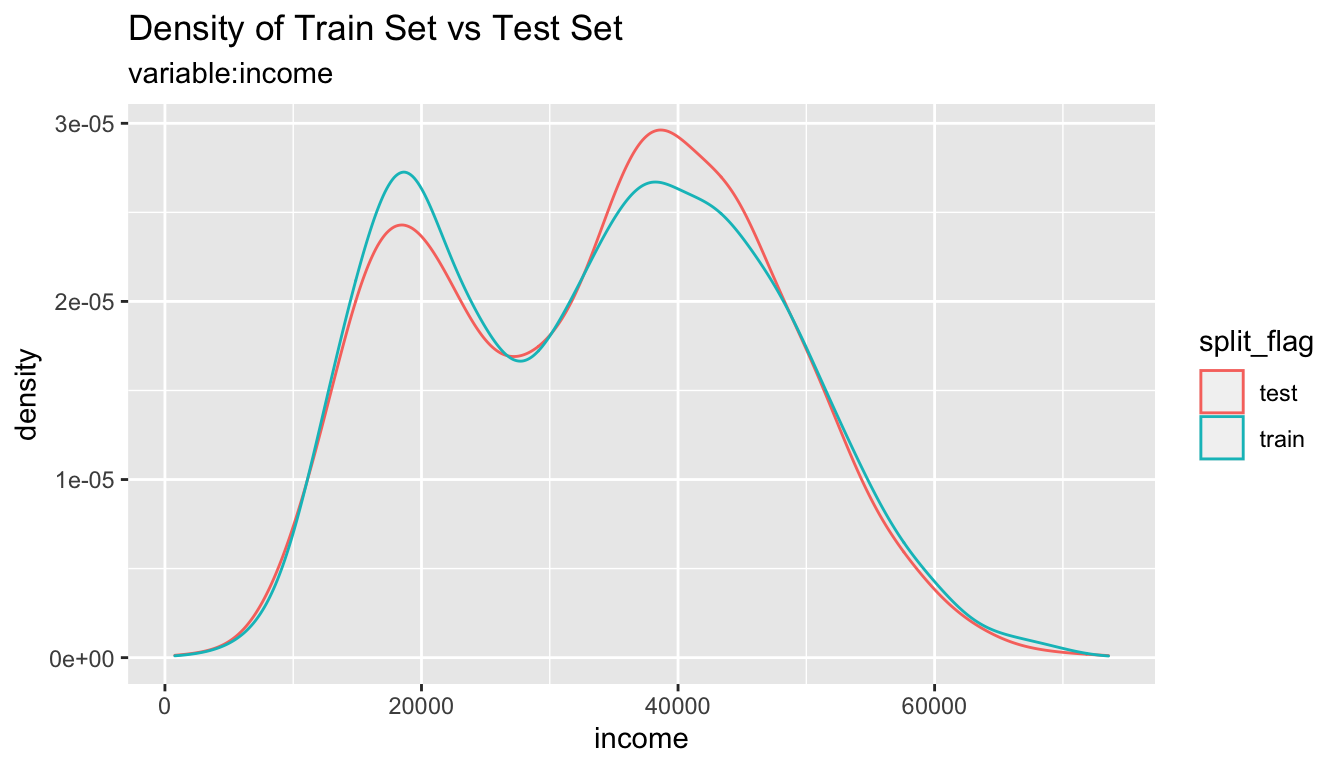
alookr - Binary classification modeling
`alookr`은 이진분류 모델의 개발 과정에서 데이터 정제, 데이터의 traning set과 test set으로의 분리, 모델 적합, 적합된 모델의 평가 및 최적의 모델을 선정한다. 이 패키지는 `dplyr` 패키지와 협업하여 이진분류 데이터 분석 프로세스를 유연하게 처리해 준다.
Introduce window function
"데이터 분석의 중요성이 대두되면서 1990년대 말부터 많은 DBMS는 행과 행간의 관계를 정의하거나 행과 행간을 비교하고 연산하는 함수의 기능을 SQL에 추가하기 시작했다. 그리고 이들을 `window function`이라 불렀다."
R 웹 어플리케이션 개발에 대한 연구
"RSS(R StatServer)란 R의 RServe 라이브러리를 이용해서 Java/JSP 기반의 웹 어플리케이션 구축을 위해서 개발한 서버 환경이다."
Introduce dbplyr package
`dbplyr` 패키지는 `DBMS`를 위한 `dplyr` 패키지의 `Backend`다. `dplyr` 패키지의 R 환경에서 data.frame 객체에서 상속된 데이터 객체를 조작해서 데이터 분석을 수행하는 패키지라면, `dbplyr` 패키지는 `dplyr` 패키지의 문법으로 DBMS 환경의 `Tables` 자원을 액세스하여 데이터 분석을 수행하게 도와 준다.

draw the complex function
`복소수 함수(complex function)`를 이용한 시각화의 대표적인 것에 `망델브로 세트`가 있다. 이번에 소개할 이미지도 몇 개의 복소수 함수를 좌표에 출력한 이미지다.
finance analytics
`finance` 분석을 위한 여러 R 패키지의 설치 및 `finance data`를 수집하기 위한 몇 가지의 방법에 대해서 살펴 본다.

데이터 연산 및 조작
`벡터`의 조작과 `행렬`의 조작은 기본적인 데이터 조작의 방법이다. 일차원으로서의 벡터와 이차원으로서의 행렬의 조작에 익숙하면 데이터 프레임이나 여기서 상속된 `tibble` 객체의 데이터 조작을 쉽게 수행할 수 있을 것이다. 물론 `tibble`이나 여기서 파생된 `data_df`는 `dplyr` 패키지로 또 다른 방법에 의한 데이터 조작을 지원하기도 한다.

Documents Taxonomy
`Documents Taxonomy`는 `문서(텍스트)들을 분류체계 기준으로 분류`하는 것으로, 대표적인 것에 콜센터의 상담 내용을 상담 분류 체계로 분류하는 것이 있다. 엄밀하게 구분하면 Taxonomy와 Classification은 다른 개념이지만, 여기서는 `Classification Model로 Documents Taxonomy의 가능성을 진단`해 본다.
대통령 연설문 분석하기
비정형 텍스트 데이터를 조작할 경우에 종종 발생하는 요건으로, `character 벡터의 개별 원소`를 특정 구분자로 나누어서 `여러 개의 원소로 만들거나`, 데이터 프레임에서 상속된 객체에서 특정 `character 변수`를 동일한 방법으로 나누어서 `여러 관측치로 만들 필요성` 있다.
하나에서 여러 개를 파생하기
비정형 텍스트 데이터를 조작할 경우에 종종 발생하는 요건으로, `character 벡터의 개별 원소`를 특정 구분자로 나누어서 `여러 개의 원소로 만들거나`, 데이터 프레임에서 상속된 객체에서 특정 `character 변수`를 동일한 방법으로 나누어서 `여러 관측치로 만들 필요성` 있다.

데이터 조작하기
`외부 데이터`를 읽어들여 `데이터 프레임`을 만들고, 이를 조작하여 데이터 분석을 위한 데이터 셋을 생성하는 것은 데이터 분석 과정에서 대단히 중요한 과정이다.
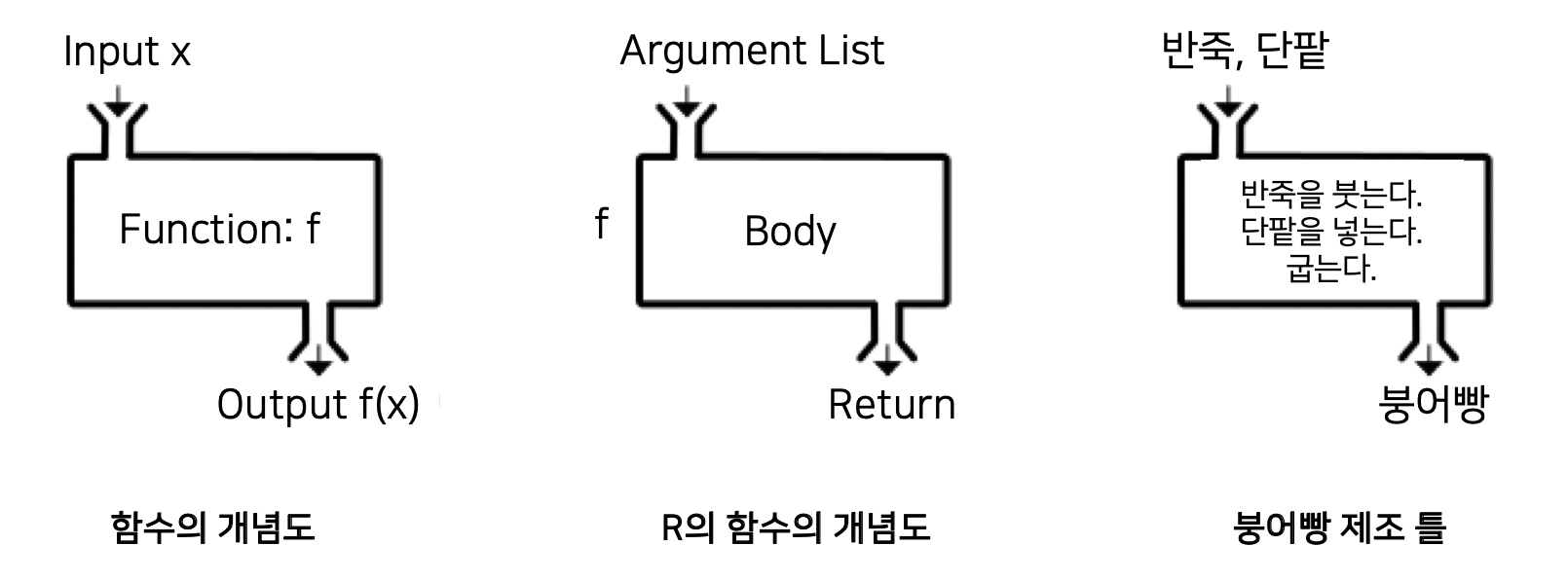
모든 연산자는 함수다
UNIX나 Linux의 쉘 스크립트에서의 파이프의 기능은 필수 불가결하다. 마치 파이프라인을 엮어서 물을 원하는 방향으로 흘려보내는 듯한 자유로운 파이프의 구사는 스크립트의 성능을 배가시켜 준다.

tridokus
스도쿠에서 각 셀에 할당된 숫자에 색상을 적용하면 제법 보기 좋은 그림이 그려진다. 그리고 각 셀에 중복으로 숫자를 할당하면 더 멋진 그림을 그릴 수 있다. 각 셀에 세개의 숫자를 할당한 `트라이도쿠스(tridokus)`를 중심으로 스도쿠의 그림에 빠져 보자.
neural style transfer
`Neural Network` 알고리즘으로 사진이나 그림을 변형시키는 기법에 대한 `A Neural Algorithm of Artistic Style`이라는 논문이 히트친 적이 있다. 고호의 화풍으로 사진의 변형하여 예술적인 이미지를 만들어내는 것이다.

망델브로 세트
고교 시절에 일본의 과학 잡지인 `Newton`을 번역해서 만든 `월간과학`이라는 잡지를 열독한 적이 있다. 그 잡지에서 본 망델브로 세트라는 Fractal 이미지에 매료되었었다. 마치 미술 작품처럼 아름다운 색채의 기하학적 무늬는 아직도 잊지 못하고 있다.

고향집 풍경, 텃밭과 담장 밑의 숨소리
강원도 홍천의 본가는 변두리 시골 마을에 있다. 아무 생각없이 아침 마실길에 카메라에 식물들을 담아 보았다.
dlookr 0.3.2 - DBMS 테이블의 품질진단
이번에 개선된 0.3.2 버전에서는 DBMS의 테이블로 존재하는 데이터의 진단과 EDA를 지원한다. 본 포스트는 DBMS의 테이블에 대한 품질진단과 EDA를 수행하는 방법을 제시한다.
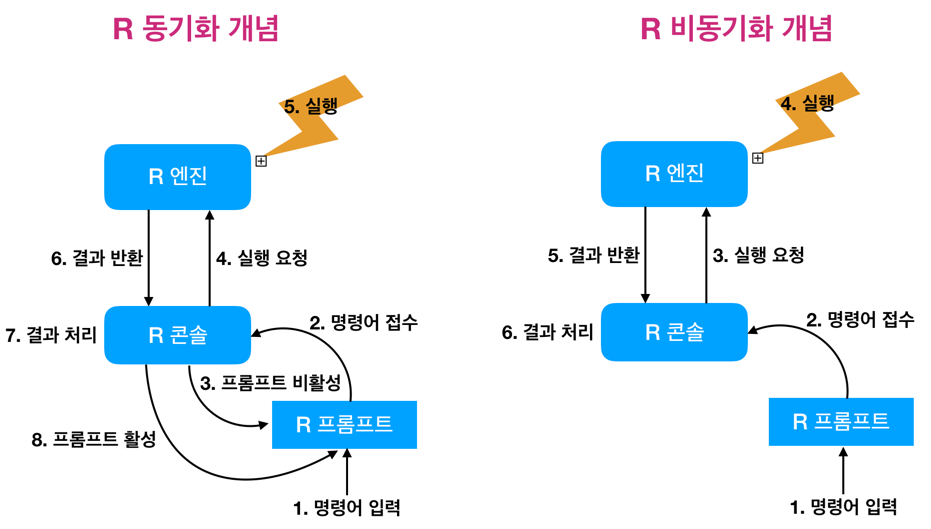
Asynchronous programming in R
오늘 소개할 포스트는 수십분에서 수 시간의 run-time을 요구하는 작업을 대기 상태없이 수행하여, 바로 다른 작업을 수행할 수 있는 방법을 제시한다.
dlookr - 데이터진단, EDA, 데이터변환을 위한 패키지
`dlookr`은 데이터 분석과정에서 데이터 품질진단, EDA 및 변수변환을 지원하는 신규 패키지다. 이 패키지는 `dplyr` 패키지와 협업하여 데이터를 탐색하고 조작할 수있는 유연한 기능을 제공한다. 특히 자동화된 3종의 보고서는 `데이터 품질진단`, `탐색적 데이터분석(EDA)`, `데이터 변환`을 수행하는데 훌륭한 가이드를 제공한다.
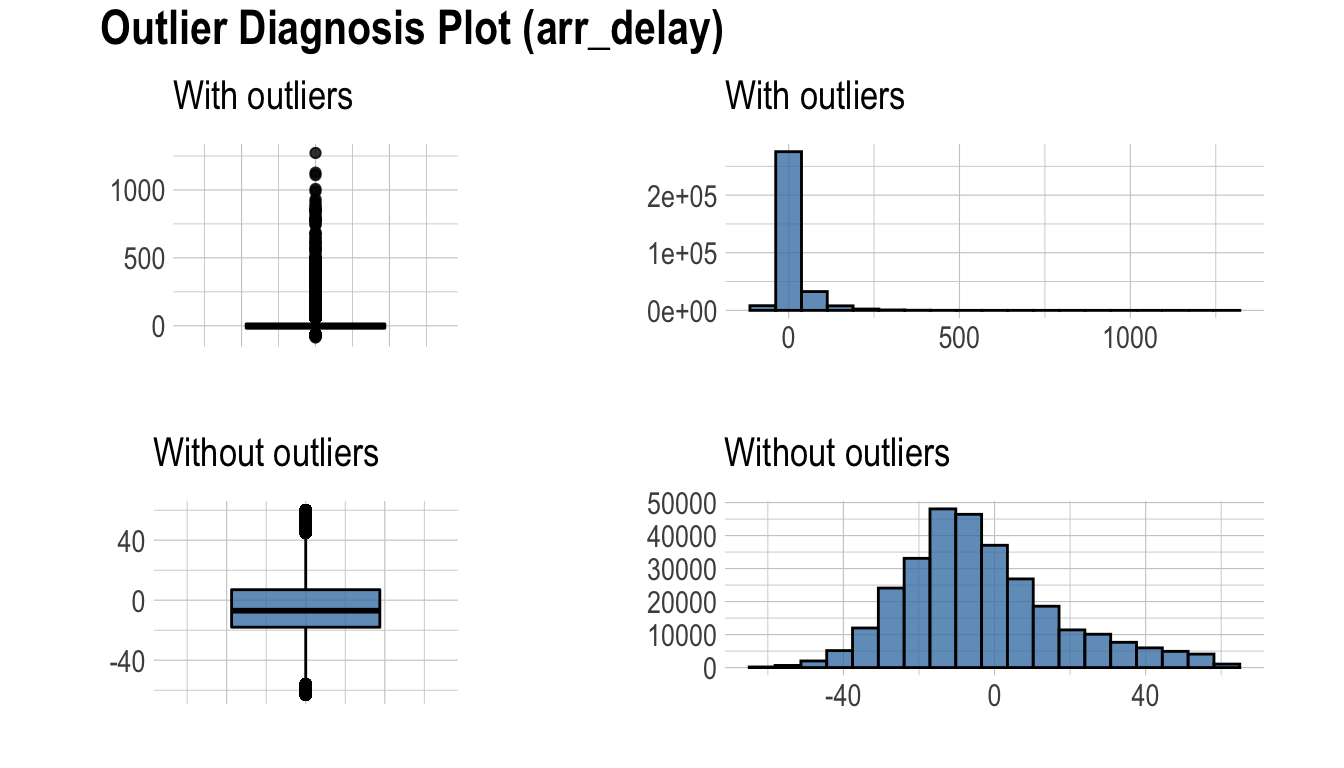
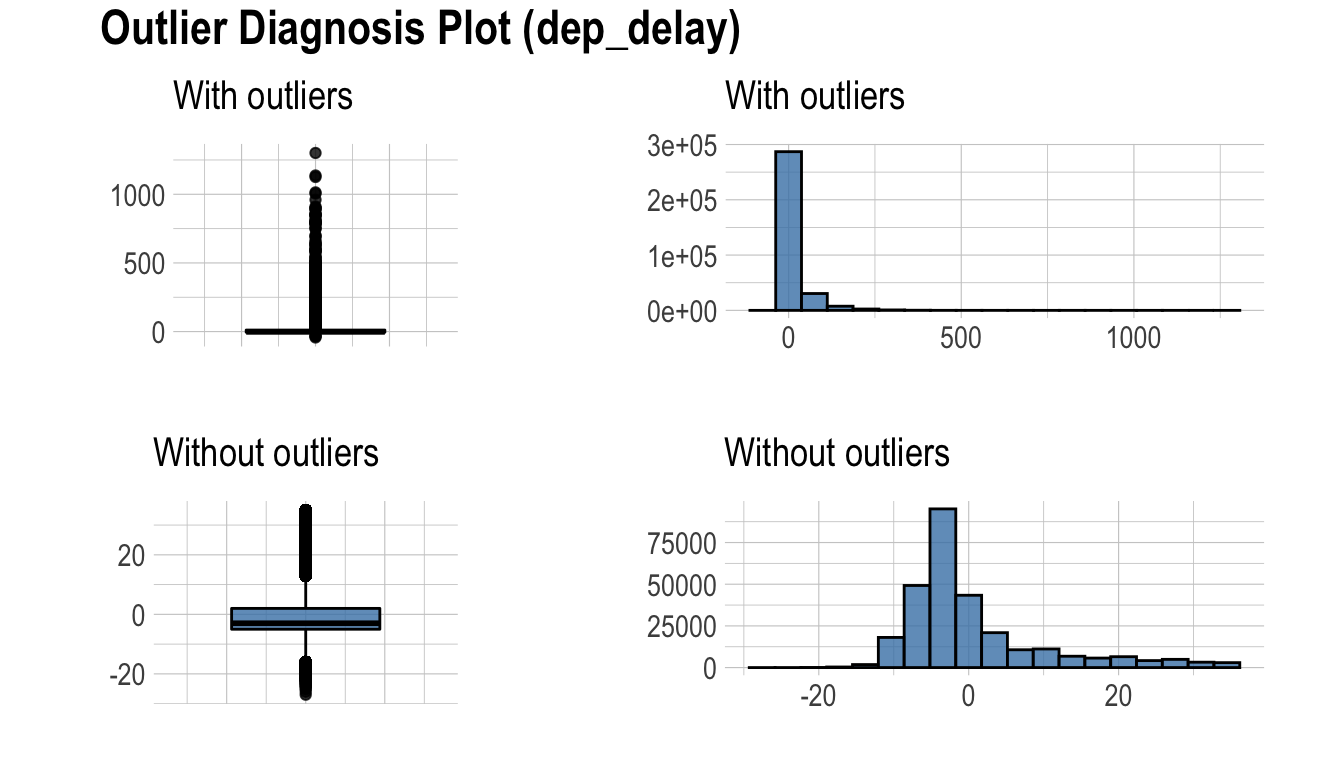
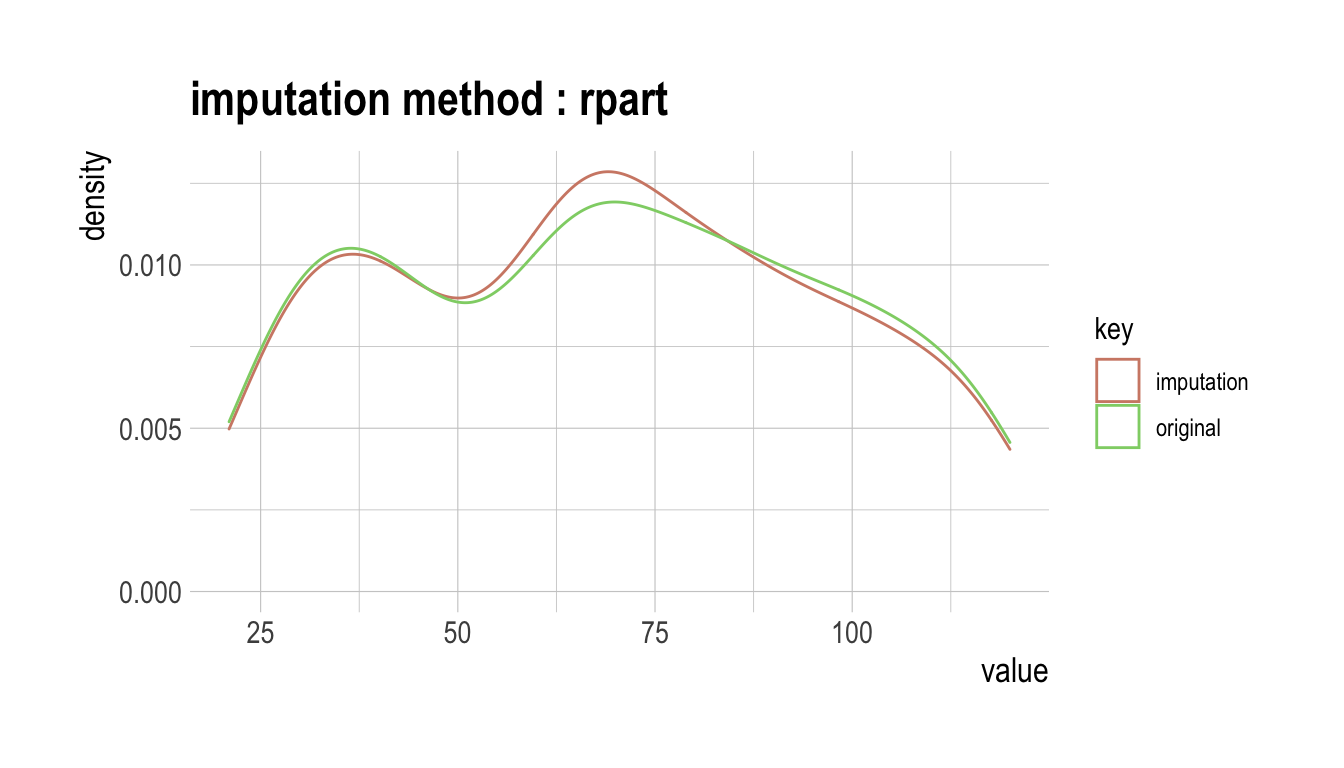
dlookr - 데이터 품질 진단
이 문서는 dlookr 기능 중에서 **데이터 품질 진단** 기능을 소개한다. 여러분은 dlookr에서 제공하는 함수로 데이터 프레임과 데이터 프레임을 상속한 tbl_df 데이터의 품질을 진단하는 방법을 일힐 수 있을 것이다.
dlookr - 탐색적 데이터 분석
이 문서는 dlookr 기능 중에서 **탐색적 데이터 분석** 기능을 소개한다. 여러분은 dlookr에서 제공하는 함수로 데이터 프레임과 데이터 프레임을 상속한 tbl_df 데이터의 탐색적 데이터 분석을 수행하는 방법을 일힐 수 있을 것이다.
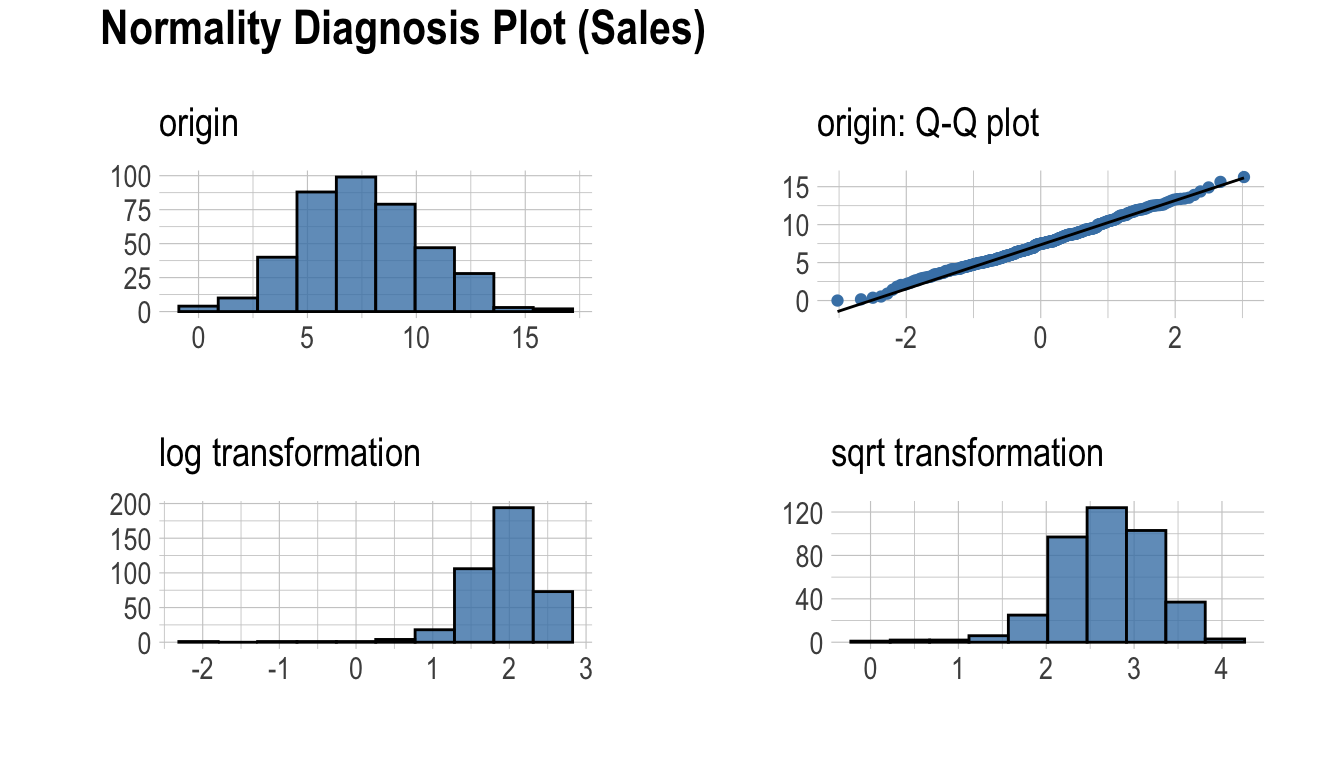
dlookr - 데이터 변환
이 문서는 dlookr 기능 중에서 **데이터 변환** 기능을 소개한다. 여러분은 dlookr에서 제공하는 함수로 데이터 프레임과 데이터 프레임을 상속한 tbl_df 데이터의 데이터 변환을 수행하는 방법을 일힐 수 있을 것이다.

Google Trends Analysis_Case Study
R에서 `Google Trends API`를 이용해서 관심 검색어의 traffic과 traffic 추이를 분석하는 방법을 실 사례로 따라가면서 학습할 수 있도로 정리한 학습자료다.
Documents Taxonomy - Speech
text2vec 패키지로 text를 vector 구조로 변환한 다음, Lasso and Elastic-Net Regularized Generalized Linear Models을 지원하는 glmnet 패키지를 이용해서 모델을 생성한다.
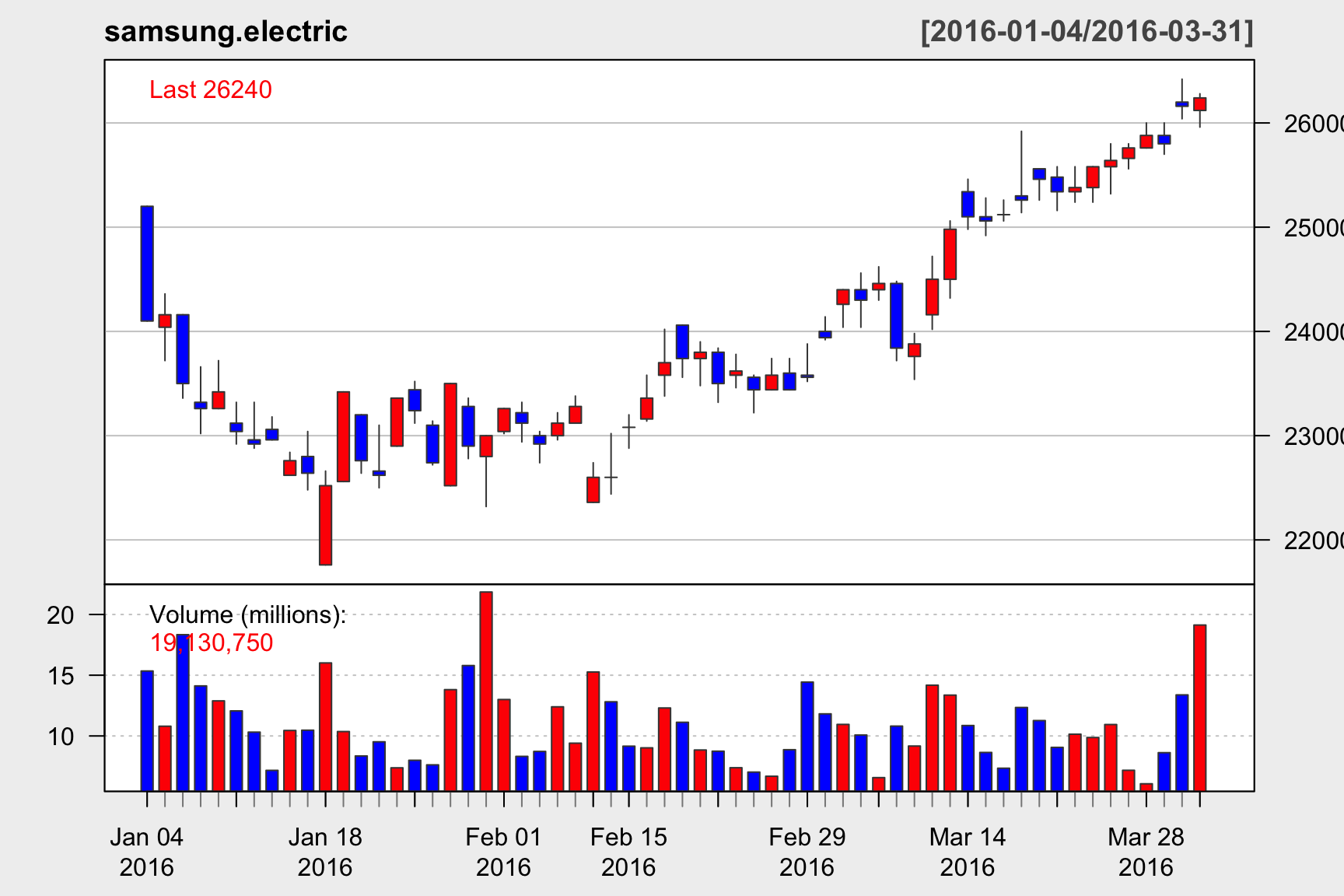
주가 데이터 분석하기
주가 데이터를 수집하는 방법을 알아본다.
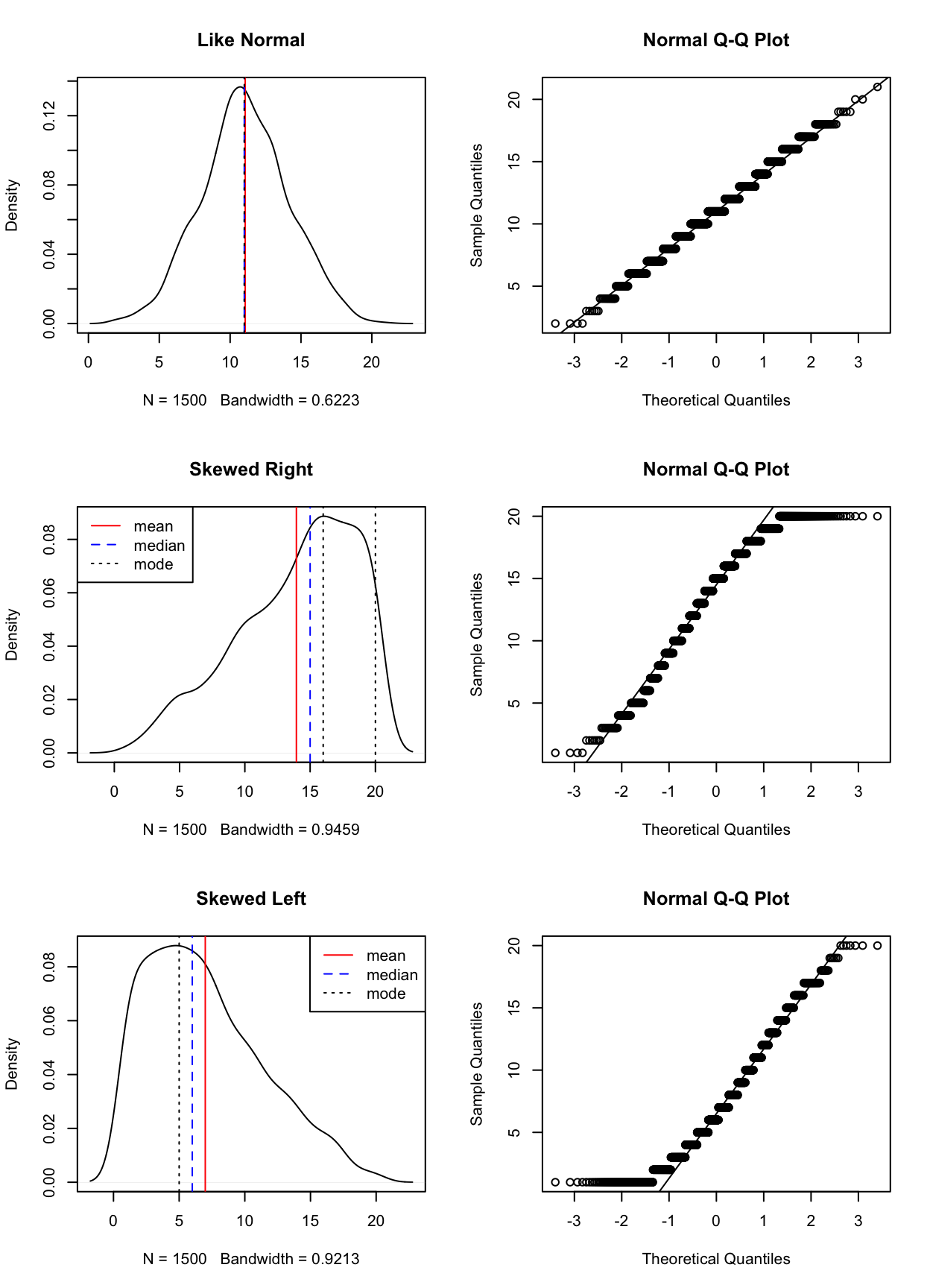
분포에 대해서
자료의 분포를 설명하는 통계량에 자료의 중심을 설명하는 대표치와 자료의 퍼짐을 설명하는 산포도(분산)가 있다. 대표치로는 평균, 중위수, 최빈수 등이 있고, 퍼진 정도를 표현하는 분산, 분산의 제곱근인 표준편차 등이 있다. 또한 자료가 어느쪽으로 편중되었는지의 기울기를 나타내는 왜도, 대표치 부근에 자료가 밀집한 정도를 나타내는 첨도 등이 있다.
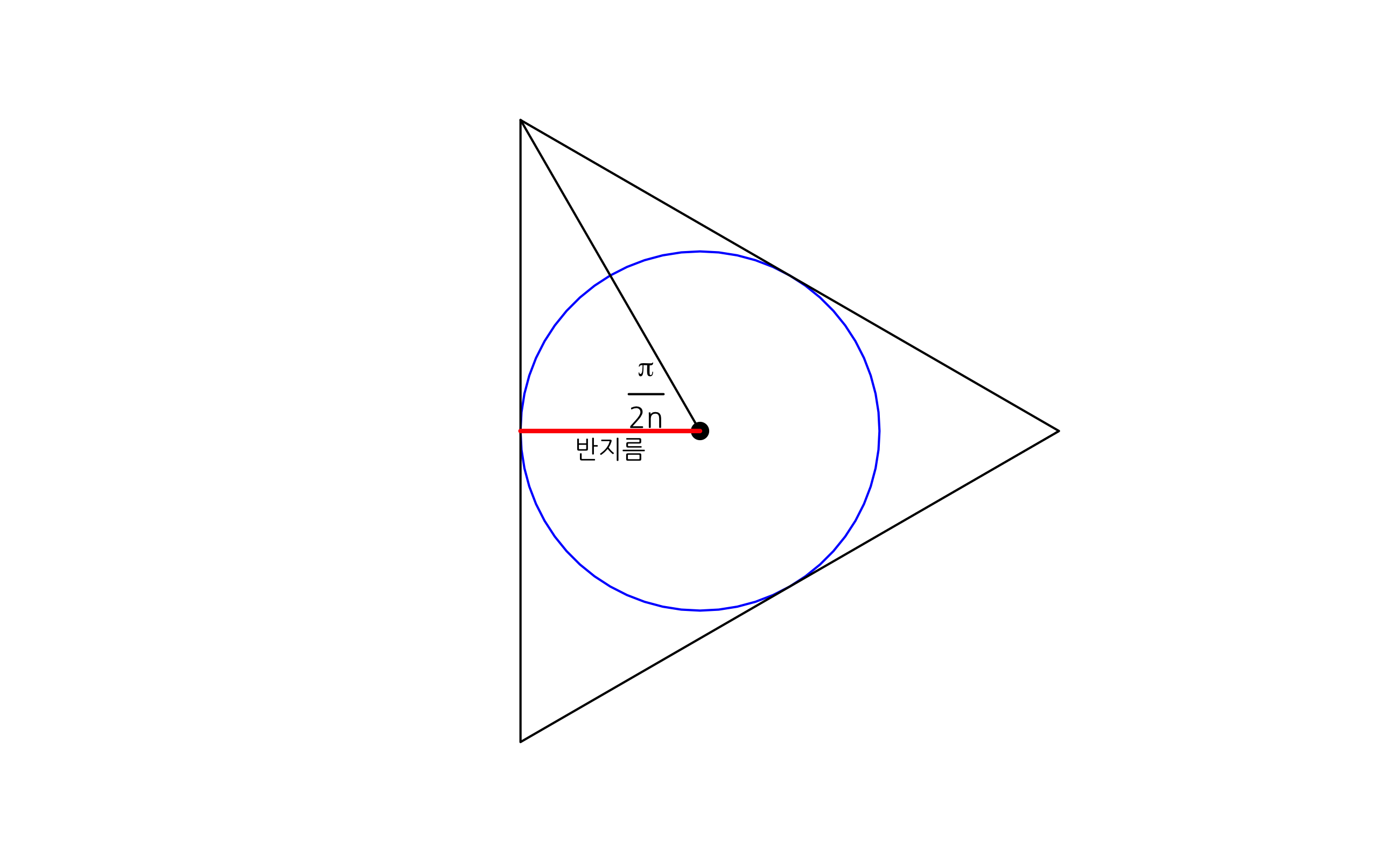
원에 대하여
가상의 한 점에서 같은 거리 만큼 떨어진 점들의 집합을 원이라 할수 있다. 한 점(원점)에서 1의 거리 만큼 떨어진 점들의 모임인 단위원을 생각해 보자. \\( x^2 + y^2 = 1^2 \\)인 원의 공식을 기억할지 모르겠다.

grid package로 그림 그리기
R로 야경을 그려보고, 한 낮의 풍경을 그려보겠다. 동심으로 돌아가 하얀 스케치북에 그레파스를 이용해서 산도 그리고, 달고 그리고, 별과 해도 그려보자. 밤의 그림은 Paul Murrell가 그렸고, 필자가 Paul Murrell의 스케치북과 그레파스를 빌려서 모사해보겠다. 해가 중천에 걸린 여름 산은 녹음이 우거져 있다.
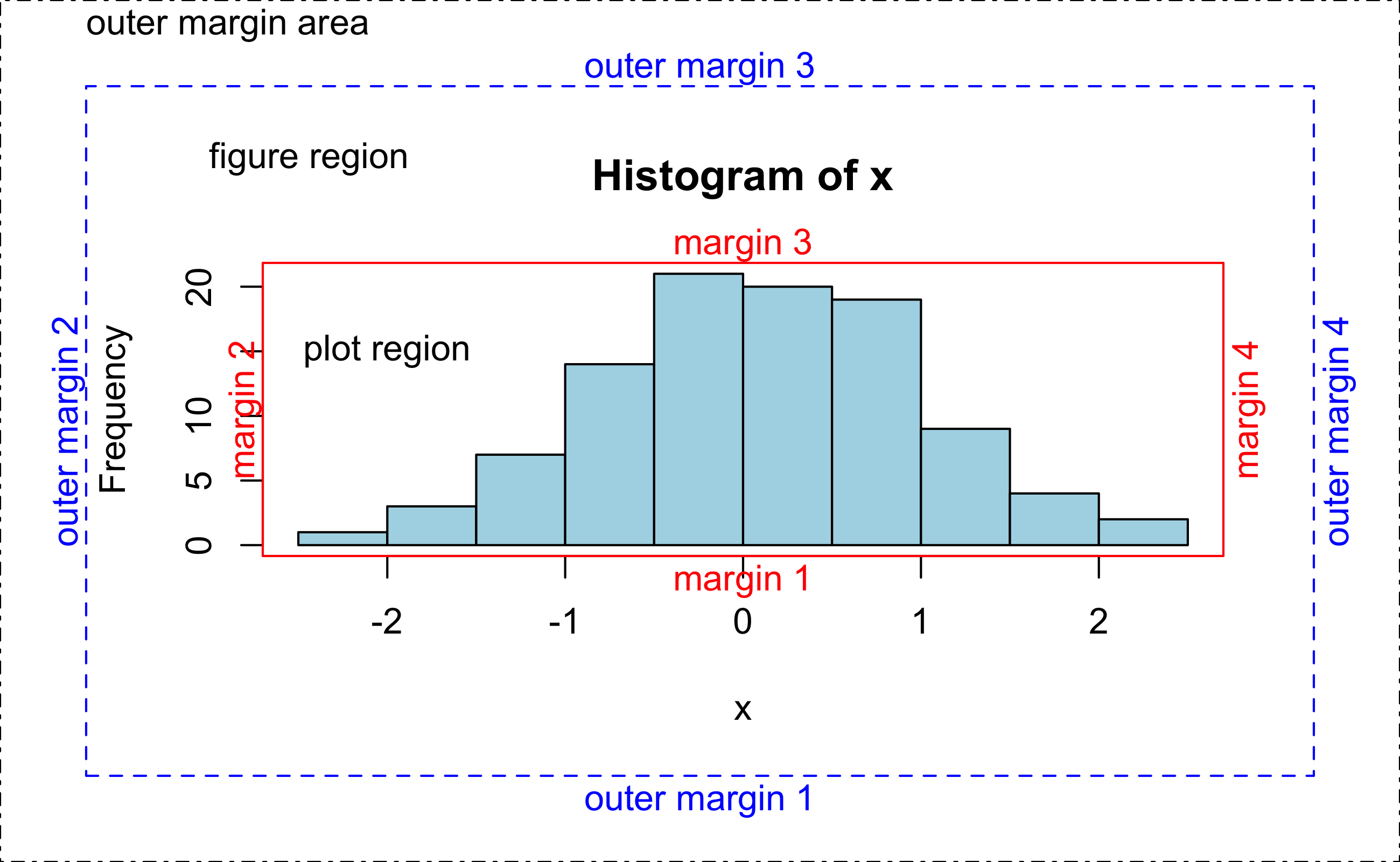
plot region 밖에 legend 출력하기
R Graphics Device에 플롯을 출력하는 영역의 구분에 대해서 알아보자.

메이다이닝, 시크릿 가든
반송과 바오밥 나무, 그리고 가을에 방문하면 잘 익은 몇 개의 모과도 얻어올 수 있는 곳, 메이다이닝
행렬의 원소중에 최대값의 위치 알아내기
행렬의 원소중에 최대값의 위치를 알아내는 방법을 알아본다.
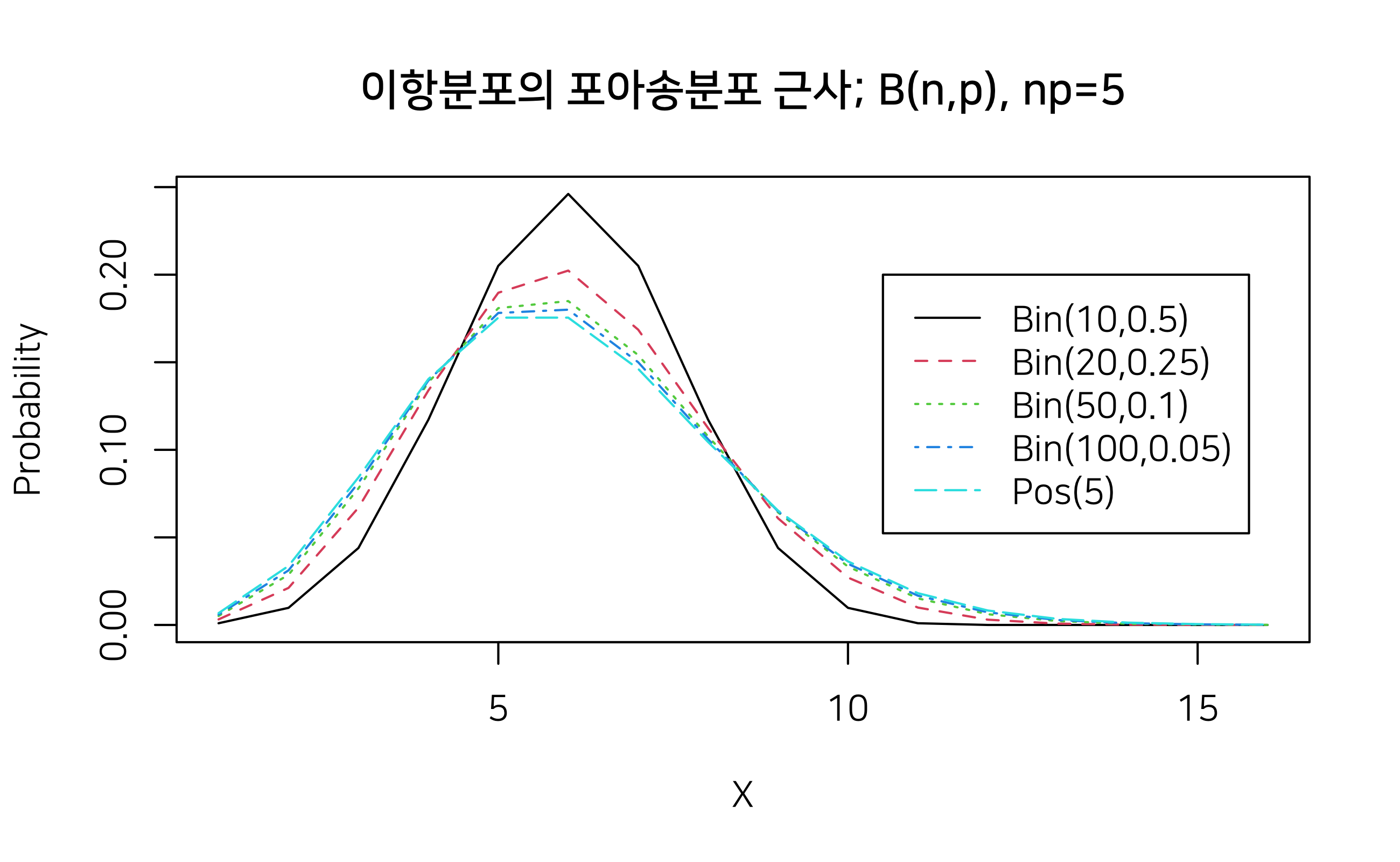
이항분포의 포아송분포 근사
샘플의 수가 커질수록 이항분포가 포아송분포로 근사하는 것을 시각화를 통해서 확인해 보자.
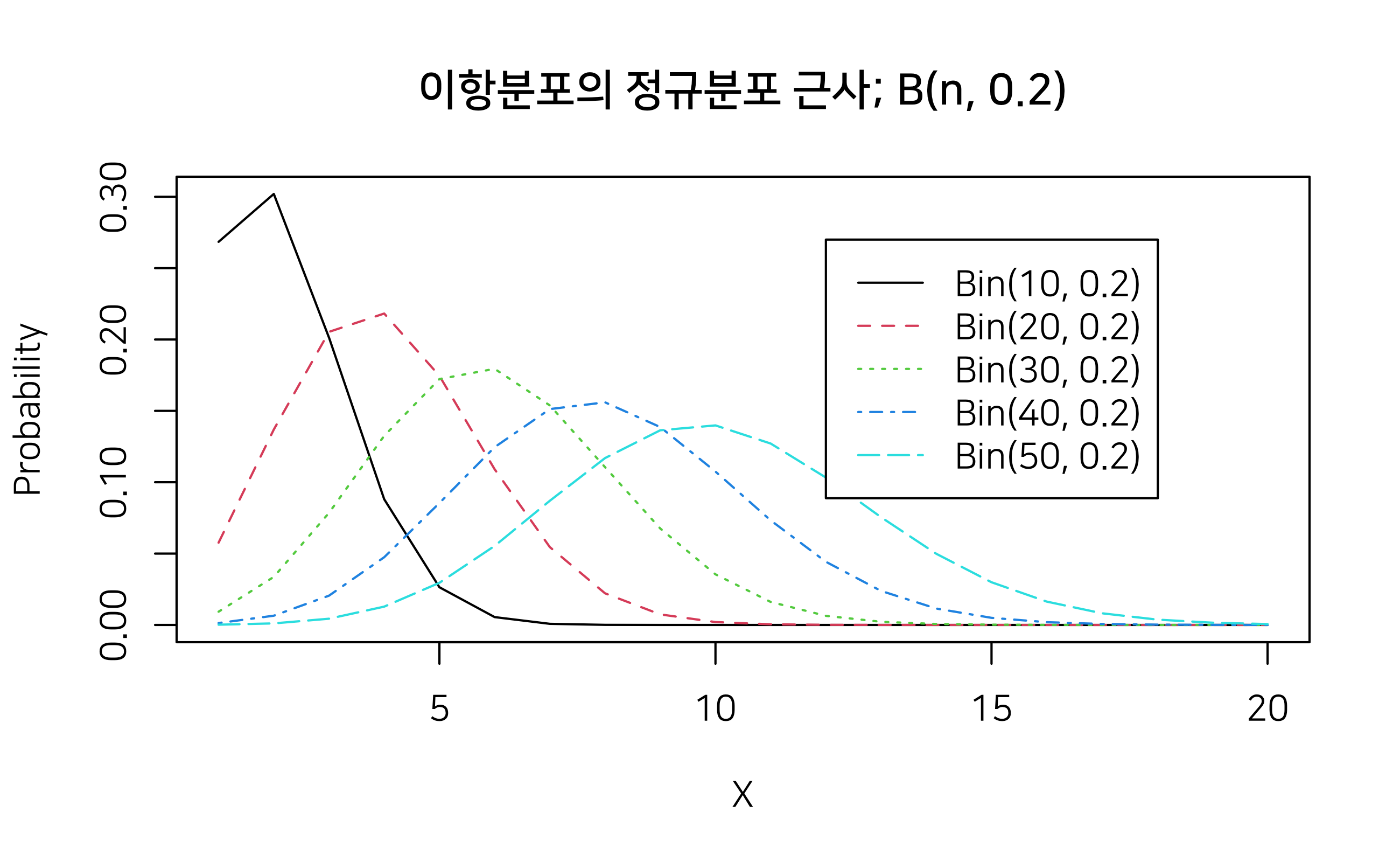
이항분포의 정규분포 근사
샘플의 수가 커질수록 이항분포가 정규분포로 근사하는 것을 시각화를 통해서 확인해 보자.
집합연산
R에서도 집합연산을 수행할 수 있는 여러 유용한 함수를 제공한다.

color
데이터 시각화에서 색상의 선택은 중요한 작업 중의 하나다.
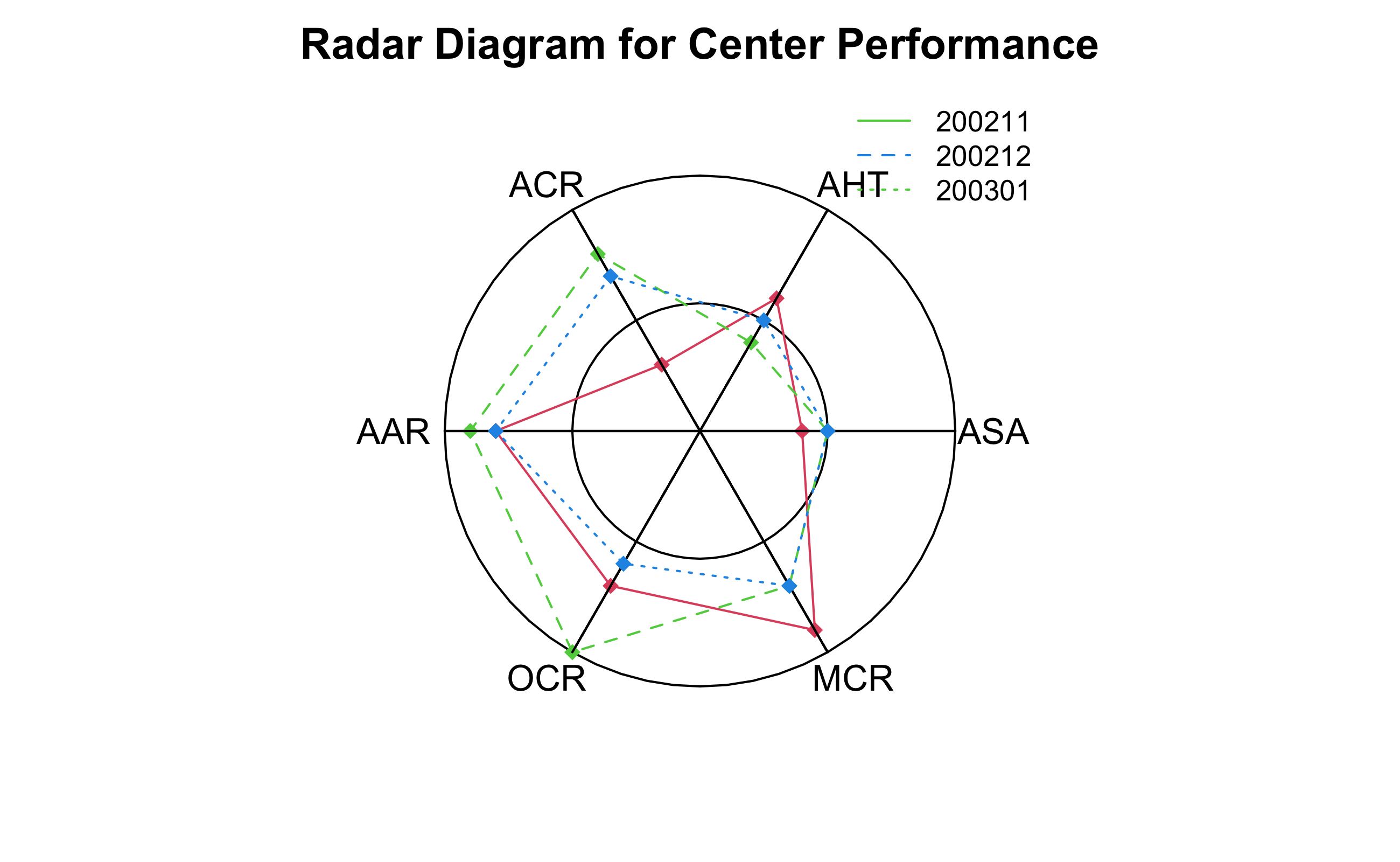
RADAR Plot
삼각함수를 이용해서 원을 그릴 수 있고, 이를 이용하면 RADAR Plot을 그릴 수 있다.
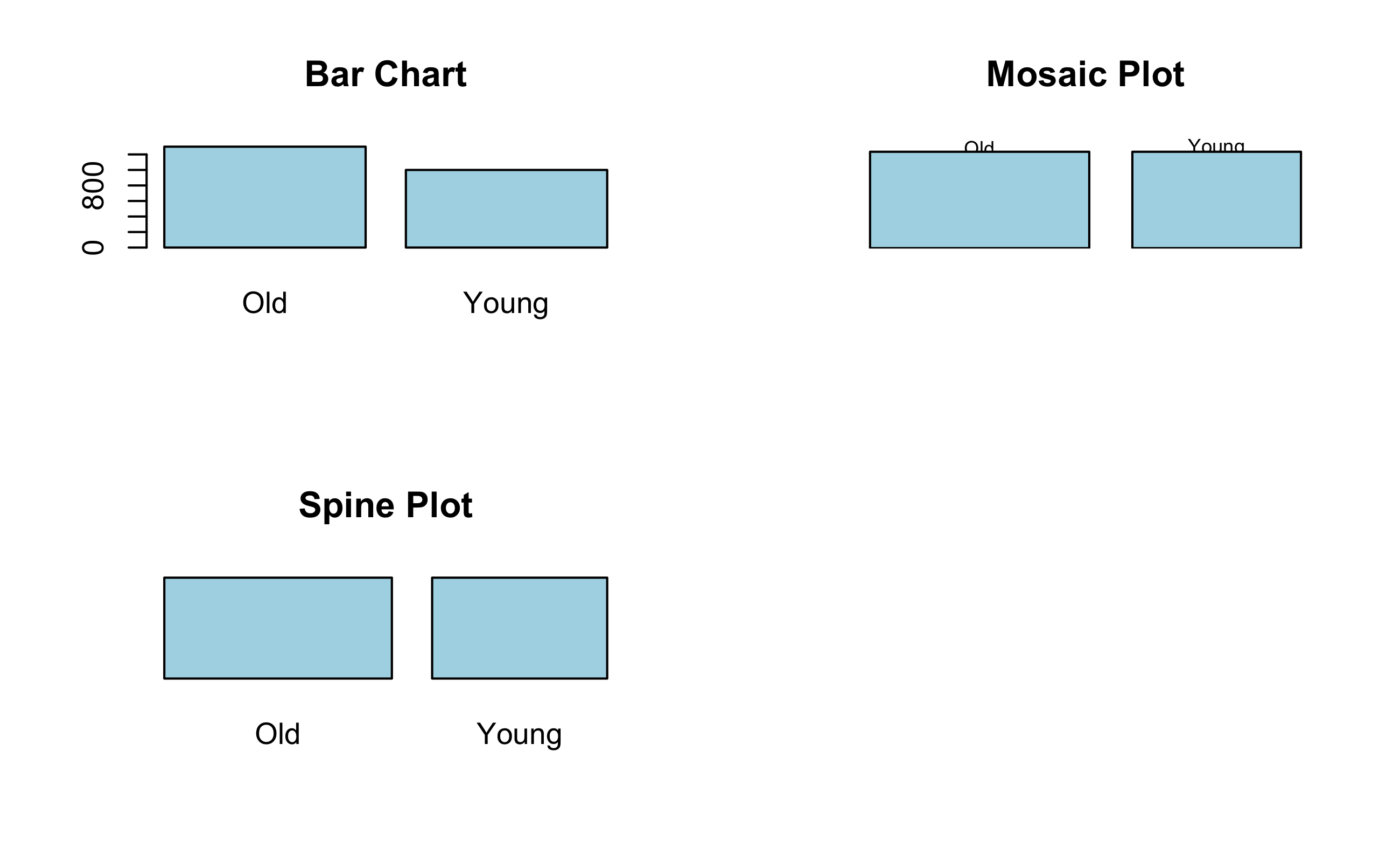
Spine Plot
Barchart는 일변량 범주형 자료에서 Class의 돗수의 비율을 막대의 길이로 표현한 것인 반면 Spine Plot은 막대의 길이는 동일하게 하고 Class의 돗수의 비율을 막대의 폭으로 표현한 것이다.